This is a huge topic that is impossible to cover in a posting. To make it worse, they become a buzz word that every body use to mean different things. AWS has a good white paper on CI/CD but there are too much focus on its own hosted services along the way. Otherwise it is a great introduction. In this post I’m trying to piece together some of the core principles related to the original idea of CI and CD, along with my thoughts about the recommended practices.
Continuous Integration involves many best practices with the target of stable delivery process. The word integration here refers to the addition of individual’s code changes into existing source repository and the entire code base continue to function. In a team collaboration with multiple developers, newly changed code from everyone should all be well integrated into existing code base. Note that sometimes existing code base means the code base after the previous developer checked in their code, maybe five minutes ago. The opposite is known as integration hell and can cost the business significantly. Common practices for continuous integration are:
Maintain a single source repository
Today some Git-based repository is common. In my first job as developer the company used CVS (Concurrent Version System) to begin with and two years later it was migrated to SVN (Apache Subversion) as source control. Today Git is the most prevalent tool as distributed version control system.
Automate the build and make the build self-testing
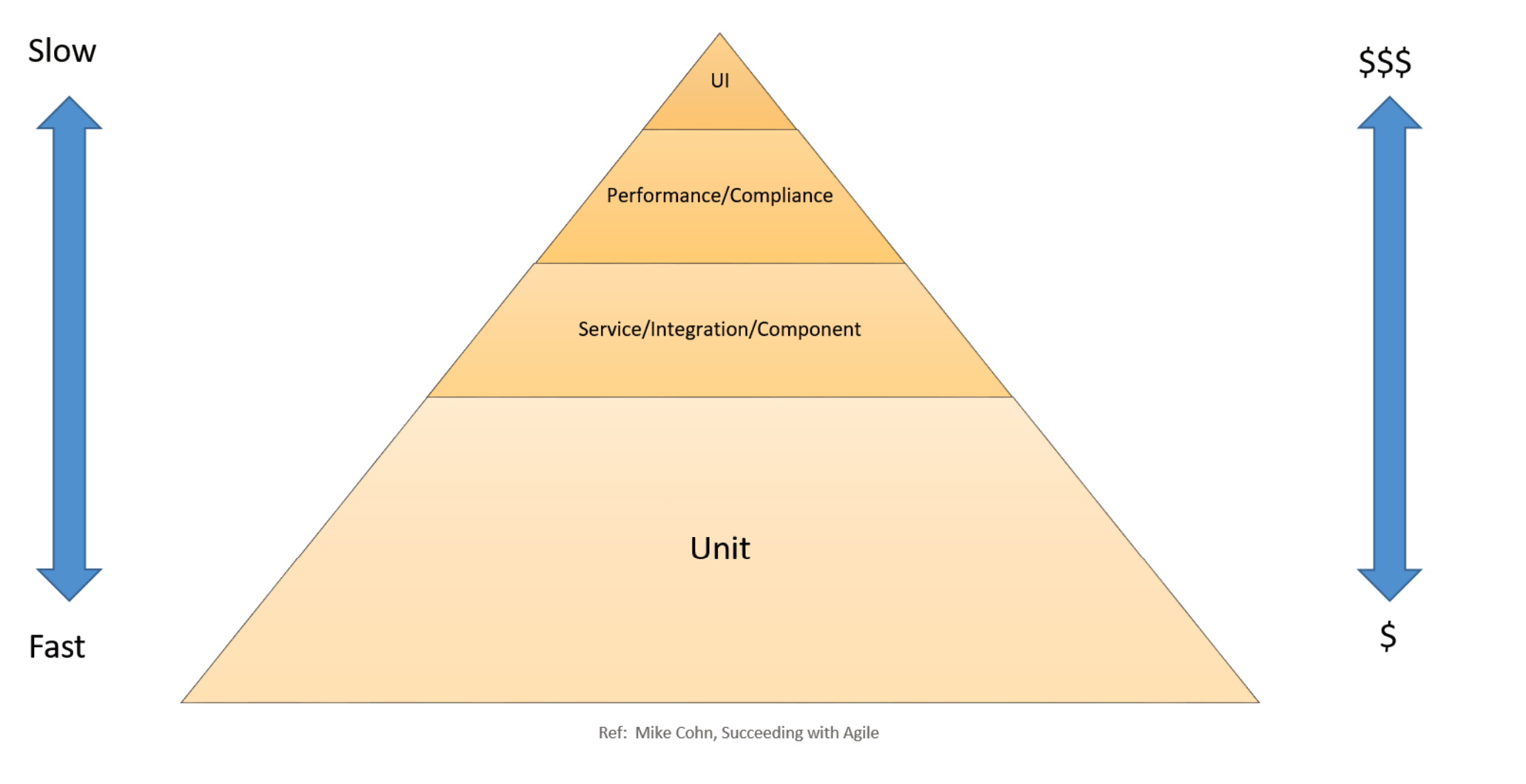
Jenkins is the power horse when it comes to build automation although it is an automation server for not only building, but also testing. The testing pyramid is introduced (as shown in the AWS white paper) to illustrate the fact that the later in the delivery process a bug is caught, the higher cost it carries. At the bottom of the pyramid is unit test that are fast and targeting individual components. A good rule of thumb is that unit test covers 70% of the testing effort and should cover the entire code base. Additional levels of testing are also important but are more expensive to execute, such as integration testing, business component testing, integration testing, system testing, compliance testing, user acceptance testing and field testing.
Everyone commits to the mainline every day. Every commit should build the mainline on an integration machine. Keep the build fast and fix broken build immediately.
CI was brought up prior to the first release of Git in 2005 as well as the concept of distributed version control. Therefore the original advocacy states commit to the mainline everyday. This is debatable and the AWS white paper does not stick to committing to the mainline. Note that committing individual branches on a daily basis is still highly recommended, if not mandatory. The other reason is that the application size grows overtime and it becomes less practical to build on every commit, from a timing and resource perspective. Build failure should raise an alert and be taken care of immediately but the team. However this actually contradictory to the other practice of committing to mainline everyday. If everyone commits to the mainline everyday, the chance of build failure will increase, especially with partial code checked in. Developers will have more “immediate” tasks to address. A good development organization knows to strike a balance here.
Test in a clone of the production environment.
Great idea but this may be challenging in the sense that a clone of the production environment involves a clone of production workload and traffic. Although production workload can be emulated but artificial workload is usually insufficient to represent the complexity of production load, including diversity of data, constraints of system, and unpredictability of traffic patterns.
Make it Easy for Anyone to get the latest executable. Everyone can see what’s happening.
This is in the territory of build artifact management and is typically not hard to implement. To smaller organizations, this just means having a shared storage space to host build artifact. To enterprises or organizations where artifact delivery is business critical, it requires some high availability and there are dedicated solution such as Jfrog Artifactory.
In Continuous Delivery, the word delivery refers to the delivery of build artifact. A continuous delivery process delivers build artifacts that are ready to deploy. The actual deployment is not triggered automatically upon the completion of build artifact delivery. The goal of Continuous delivery is that the build is technically validated and READY to go to production and that the go-live decision becomes a business decision instead of a technical one.
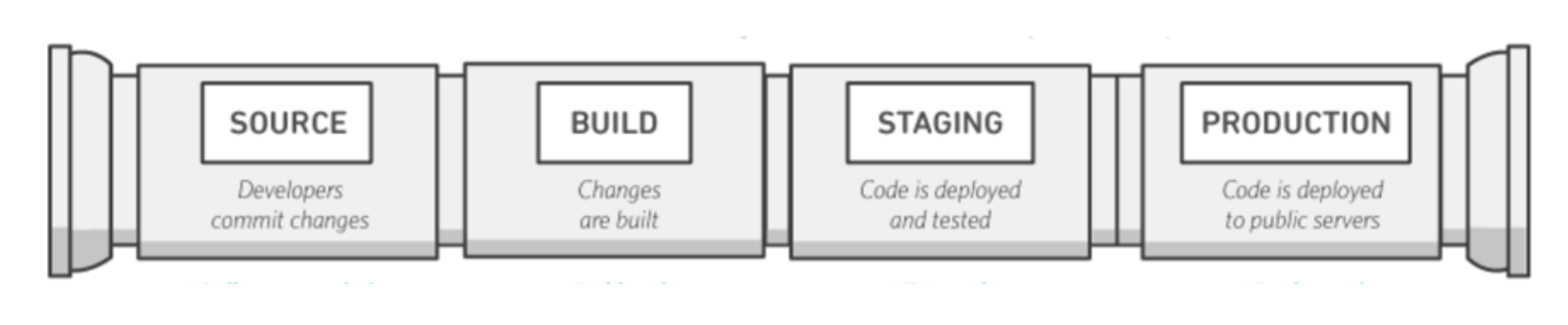
Continuous Deployment takes a step further and includes the deployment of new version of applications automatically to production. This sounds like the ultimate goal of the entire pipeline. To achieve continuous deployment, an organization need not only automate the release cycle, but also the entire deployment (in production servers). There are several deployment approaches such as blue/green, canary and rolling methods to ensure service uptime while complete the roll-out.
Obstacles
These are from wikipedia:
- Customer preferences: Some customers do not want continuous updates to their systems. This is especially true at the critical stages in their operations.
- Domain restrictions: In some domains, such as telecom and medical, regulations require extensive testing before new versions are allowed to enter the operations phase.
- Lack of test automation: Lack of test automation leads to a lack of developer confidence and can prevent using continuous delivery.
- Differences in environments: Different environments used in development, testing and production can result in undetected issues slipping to the production environment.
- Tests needing a human oracle: Not all quality attributes can be verified with automation. These attributes require humans in the loop, slowing down the delivery pipeline.