
Excerpts from Cassandra The Definitive Guide
Gossip and Failure Detection
Cassandra uses a gossip protocol that allows each node to keep track of state information about the other nodes in the cluster. The gossiper runs every second on a timer.
Gossip protocols assumes a faulty network, are commonly commonly employed in very large, decentralized network systems, and are often used as an automatic mechanism for replication in distributed databases. When a server node is started, it registers itself with the gossiper to receive endpoint state information. Because Cassandra gossip is used for failure detection, the Gossiper class maintains a list of nodes that are alive and dead.
- Once per second, the gossiper will choose a random node in the cluster and initialize a gossip session with it. Each round of gossip requires three messages.
- The gossip initiator sends its chosen friend a GossipDigestSynMessage.
- When the friend receives this message, it returns a GossipDigestAckMessage.
- When the initiator receives the ack message from the friend, it sends the friend a GossipDigestAck2Message to complete the round of gossip.
When the gossiper determines that another endpoint is dead, it “convicts” that endpoint by marking it as dead in its local list and logging that fact.
Cassandra has robust support for failure detection, as specified by a popular algorithm for distributed computing called Phi Accrual Failure Detection. The traditional failure detection (based on whether heartbeat is received or not) is deemed naive. Accrual failure detection determines suspicion level. Suspicion offers a more fluid and proactive indication of the weaker or stronger possibility of failure based on interpretation (sampling of heartbeats), as opposed to a simple binary assessment.
Accrual Failure Detectors output a value associated with each process (or node). This value is called Phi. The value is output in a manner that is designed from the ground up to be adaptive in the face of volatile network conditions, so it’s not a binary condition that simply checks whether a server is up or down.
The Phi convict threshold in the configuration adjusts the sensitivity of the failure detector. Lower values increase the sensitivity and higher values decrease it, but not in a linear fashion.
The Phi value refers to a level of suspicion that a server might be down. Applications such as Cassandra that employ an AFD can specify variable conditions for the Phi value they emit. Cassandra can generally detect a failed node in about 10 seconds using this mechanism.
Snitches
A snitch determines relative host proximity for each node in a cluster, which is used to determine which nodes to read and write from. Snitches gather information about your network topology so that Cassandra can efficiently route requests. The snitch will figure out where nodes are in relation to other nodes. Snitch property can be adjusted (endpoint_snitch in cassandra.yaml)
Rings and Token
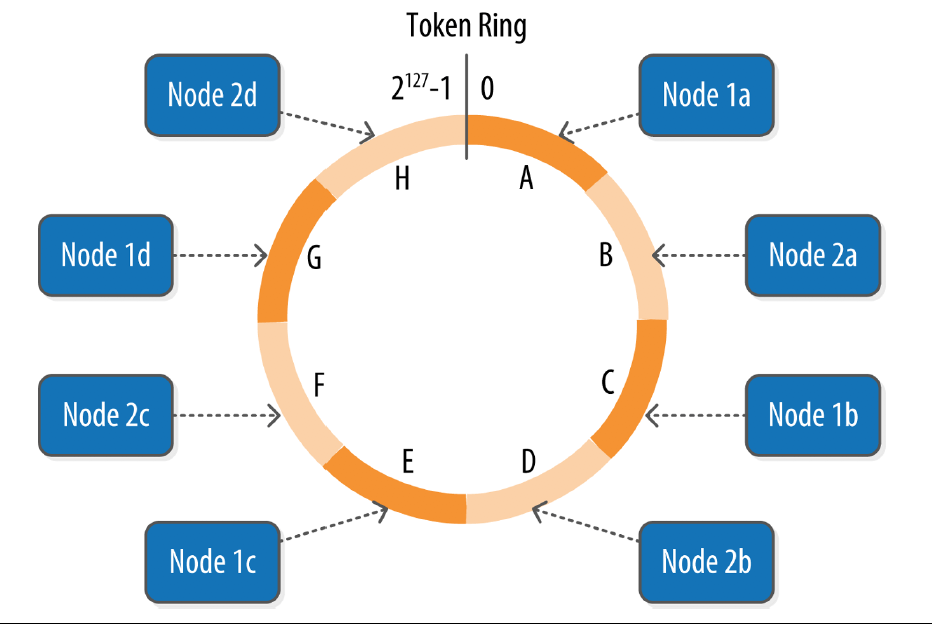
A cassandra cluster presents itself as a ring. Each node in the ring is assigned one or more ranges of data described by a token, which determines its position in the ring. A token is a 64-bit integer ID used to identify each partition.
A node claims ownership of the range of values less than or equal to each token and greater than the token of previous node. The node with lowest token owns the range less than or equal to its token and the range greater than the highest token, which is also known as the “wrapping range” In this way the token specifies a complete ring.
Data is assigned to nodes by using a hash function to calculate a token for the partition key. This partition key token is compared to the token values for the various nodes to identify the range, and therefore the node that owns the data.
Virtual Nodes
Instead of assigning a single token to a cassandra node, the token range is broken up into multiple smaller ranges, each represented by a vNode. By default a cassandra node will be assigned 256 vnodes (small range of tokens). Vnodes make it easier to maintain a cluster containing heterogeneous machines. Nodes in a cluster with more computing resources available can manage an increased number of vnode (num_tokens property in cassandra.yaml)
Replication Strategies
A node serves as a replica for different ranges of data. If one node goes down, other replicas can respond to queries for that range of data. Cassandra replicates data across nodes in a manner transparent to the user, and the replication factor is the number of nodes in your cluster that will receive copies (replicas) of the same data.
The first replica will always be the node that claims the range in which the token falls, but the remainder of the replicas are placed according to the replication strategy (sometimes also referred to as the replica placement strategy). Out of the box, Cassandra provides two primary implementations of this interface (extensions of the abstract class): SimpleStrategy and NetworkTopologyStrategy. They are specified at the time of keyspace creation.
The SimpleStrategy places replicas at consecutive nodes around the ring, starting with the node indicated by the partitioner. The NetworkTopologyStrategy allows you to specify a different replication factor for each data center. Within a data center, it allocates replicas to different racks in order to maximize availability.
Consistency Levels
Cassandra provides tuneable consistency levels that allow you to make trade-offs with CAP at a fine-grained level. You specify a consistency level on each read or write query that indicates how much consistency you require.
For read queries, the consistency level specifies how many replica nodes must respond to a read request before returning the data. For write operations, the consistency level specifies how many replica nodes must respond for the write to be reported as successful to the client. Because Cassandra is eventually consistent, updates to other replica nodes may continue in the background.
Consistency levels include:
- response from an absolute number of nodes: ONE, TWO or THREE
- response from the majority of the replica nodes (e.g. replication factor/2+1): QUORUM
- response from all nodes: ALL
ALL and QUORUM are considered strong consistency level. But in general we can consider a cluster of strong consistency if it meets this condition:
R + W > N
where
- R is read consistency level
- W is write consistency level
- N is replication factor
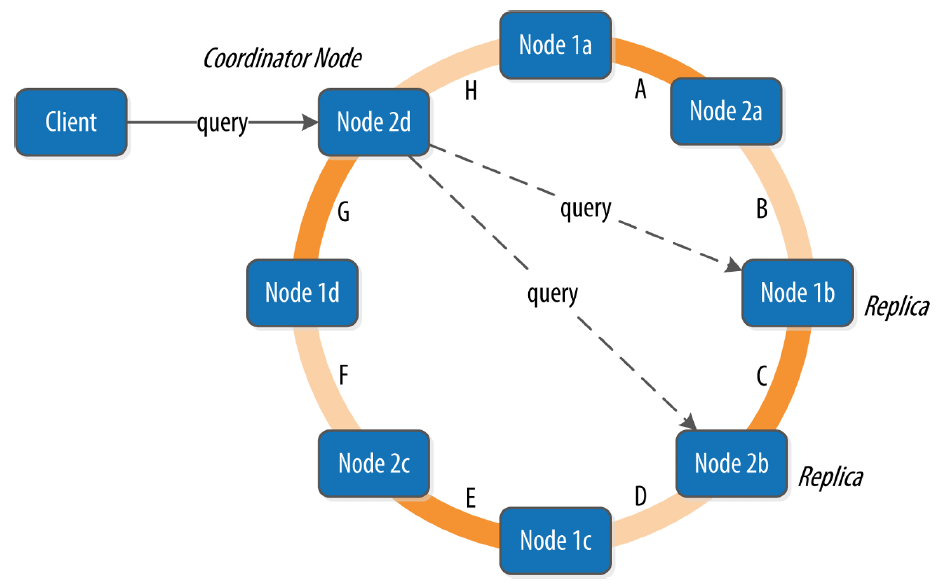
Queries and Coordinator Nodes
A client may connect to any node in the cluster to initiate a read or write query. This node is known as the coordinator node. The coordinator identifies which nodes are replicas for the data that is being written or read and forwards the queries to them.
For a write, the coordinator node contacts all replicas, as determined by the consistency level and replication factor, and considers the write successful when a number of replicas commensurate with the consistency level acknowledge the write.
For a read, the coordinator contacts enough replicas to ensure the required consistency level is met, and returns the data to the client.
Memtables, SSTables and Commit Logs
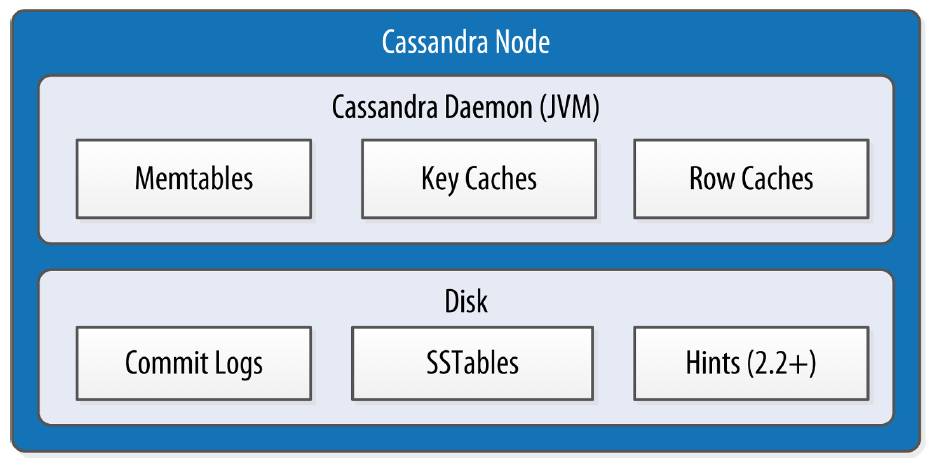
When you perform a write operation, it’s immediately written to a commit log so the write operation is considered successful. If you shut down the database or it crashes unexpectedly, the commit log can ensure that data is not lost. That’s because the next time you start the node, the commit log gets replayed. In fact, that’s the only time the commit log is read; clients never read from it.
After it’s written to the commit log, the value is written to a memory-resident data structure called the memtable. Each memtable contains data for a specific table. In early implementations of Cassandra, memtables were stored on the JVM heap, but
improvements starting with the 2.1 release have moved the majority of memtable data to native memory. (check out the memtable_allocation_type property: heap_buffers/offheap_buffers/offheap_objects). This makes Cassandra less susceptible to fluctuations in performance due to Java garbage collection.
When the number of objects stored in the memtable reaches a threshold, the contents of the memtable are flushed to disk in a file called an SSTable. A new memtable is then created. This flushing is a non-blocking operation; multiple memtables may exist for a single table, one current and the rest waiting to be flushed. They typically should not have to wait very long, as the node should flush them very quickly unless it is overloaded.
Each commit log maintains an internal bit flag to indicate whether it needs flushing. When a write operation is first received, it is written to the commit log and its bit flag is set to 1. There is only one bit flag per table, because only one commit log is ever being written to across the entire server. All writes to all tables will go into the same commit log, so the bit flag indicates whether a particular commit log contains anything that hasn’t been flushed for a particular table. Once the memtable has been properly flushed to disk, the corresponding commit log’s bit flag is set to 0, indicating that the commit log no longer has to maintain that data for durability purposes. Like regular logfiles, commit logs have a configurable rollover threshold, and once this file size threshold is reached, the log will roll over, carrying with it any extant dirty bit flags.
The SSTable is a concept borrowed from Google’s Bigtable. Once a memtable is flushed to disk as an SSTable, it is immutable and cannot be changed by the application. Despite the fact that SSTables are compacted, this compaction changes only their on-disk representation; it essentially performs the “merge” step of a mergesort into new files and removes the old files on success.
Cassandra supports the compression of SSTables in order to maximize use of the available storage. This compression is configurable per table. Each SSTable also has an associated Bloom filter, which is used as an additional performance enhancer.
All writes are sequential, which is the primary reason that writes perform so well in Cassandra. No reads or seeks of any kind are required for writing a value to Cassandra because all writes are append operations. This makes one key limitation on performance
the speed of your disk. Compaction is intended to amortize the reorganization of data, but it uses sequential I/O to do so. So the performance benefit is gained by splitting; the write operation is just an immediate append, and then compaction helps to organize for better future read performance. If Cassandra naively inserted values where they ultimately belonged, writing clients would pay for seeks up front.
On reads, Cassandra will read both SSTables and memtables to find data values, as the memtable may contain values that have not yet been flushed to disk.
Caching
Cassandra provides three forms of caching:
- Key cache: stores a map of partition keys to row index entries, facilicating faster read access into SSTables stored on disk. The key cache is stored on the JVM heap, configurable through key_cache_size_in_mb and key_cache_save_period in cassandra.yaml;
- Row cache: caches entire rows and can greatly speed up read access for frequently accessed rows, at the cost of more memory usage. The row cache is stored in off-heap memory, configurable through row_cache_size_in_mb and row_cache_save_period in cassandra.yaml;
- counter cache: improve counter performance by reducing lock contention for the most frequently accessed counters.
By default, key and counter caching are enabled, while row caching is disabled, as it requires more memory. Cassandra saves its caches to disk periodically in order to warm them up more quickly on a node restart.
Hinted Handoff
Hinted handoff mechanism is introduced to cope with the situation where a write request is sent to Cassandra but the replica node where the write belongs is not available. In this situation, the coordinator will create a hint to hang onto this write. Once the coordinator detects via gossip that the intended node is back online, the coordinator node will “hand off” to the intended node the “hint” regarding the write. Cassandra holds a separate hint for each partition that is to be written.
This allows Cassandra to be always available for writes, and generally enables a cluster to sustain the same write load even when some of the nodes are down. It also reduces the time that a failed node will be inconsistent after it does come back online.
Hints do not count as writes for the purposes of consistency level, except for consistency level ANY. Hinted handoff can be configured through properties hinted_handoff_enabled, max_hint_window_in_ms and hinted_handoff_throttle_in_kb, max_hints_delivery_threads and batchlog_replay_throttle_in_kb in cassandra.yaml.
There is a practical problem with hinted handoffs (and guaranteed delivery approaches, for that matter): if a node is offline for some time, the hints can build up considerably on other nodes. Then, when the other nodes notice that the failed node has come back online, they tend to flood that node with requests, just at the moment it is most vulnerable (when it is struggling to come back into play after a failure). To address this problem, Cassandra limits the storage of hints to a configurable time window. It is also possible to disable hinted handoff entirely.
Although hinted handoff helps increase Cassandra’s availability, it does not fully replace the need for manual repair to ensure consistency.
Lightweight Transactions
If a client is going to read (check existence) and then write a record (only if not existed already). We’d like to guarantee linearizable consistency. In other words, no other client can come in between our read and write queries with their own modification. Lightweight transaction is a mechanism to support linearizable consistency based on Paxos. Paxos is a consensus algorithm that allows distributed peer nodes to agree on a proposal, without requiring a master to coordinate a transaction. It emerged as alternative to traditional two-phase commit.
Cassandra’s lightweight transaction are limited to a single partition.
Tombstones
When you execute a delete operation, the data is not immediately deleted. Instead, it’s treated as an update operation that places a tombstone on the record. A tombstone is a deletion marker that is required to suppress older data in SSTables until compaction can run. The per-table setting gc_grace_period is the amount of time that the server will wait to garbage-collect tombstones. Once a tombstones ages over the grace period, they will be garbage-collected.
Bloom Filters
Introduced to boost the performance of reads, Bloom filters are very fast, non-deterministic algorithms for testing whether an element is a member of a set. Being deterministic means false-positive is possible but not false-negative. In other words, if the filter indicates the given element exists in the set, cassandra needs to make sure by checking the set (disk); if the filter indicates the given element does not exist in the set, it certainly doesn’t. Bloom filter is a special kind of cache, stored in memory to improve performance by reducing the need for disk access on key lookups. The accuracy can be increased (to reduce the chance of false positives) by increasing the filter size, at the cost of more memory. This is tunable per table using bloom_filter_fp_chance. Bloom filters are used in other distributed database and caching technologies as well such as Hadoop.
Compaction
A compaction operation in Cassandra is performed in order to merge SSTables. During compaction, the data in SSTables is merged: the keys are merged, columns are combined, tombstones are discarded, and a new index is created. Compaction is the process of freeing up space by merging large accumulated data files.
This is roughly analogous to rebuilding a table in the relational world. But the primary difference in Cassandra is that it is intended as a transparent operation that is amortized across the life of the server.
Another important function of compaction is to improve performance by reducing the number of required seeks. There are a bounded number of SSTables to inspect to find the column data for a given key. If a key is frequently mutated, it’s very likely that the mutations will all end up in flushed SSTables. Compacting them prevents the database from having to perform a seek to pull the data from each SSTable in order to locate the current value of each column requested in a read request.
When compaction is performed, there is a temporary spike in disk I/O and the size of data on disk while old SSTables are read and new SSTables are being written. Cassandra supports multiple algorithms for compaction via the strategy pattern. The compaction strategy is an option that is set for each table. Strategies include:
- SizeTieredCompactionStrategy (STCS) is the default compaction strategy and is recommended for write-intensive tables;
- LeveledCompactionStrategy (LCS) is recommended for read-intensive tables;
- DateTieredCompactionStrategy (DTCS), which is intended for time series or otherwise date-based data.
When compaction is performed, there is a temporary spike in disk I/O and the size of data on disk while old SSTables are read and new SSTables are being written.
Repairs
Replica synchronization is supported via two different modes known as read repair and antri-entropy repair.
- Read repair: the synchronization of replicas as data is read. Cassandra reads data from multiple replicas in order to achieve the requested consistency leve, and detects if any replicas have out of date values. If an insufficient number of nodes have the latest value, a read repair is performed to update the out of date replicas, either immediately or in the background.
- Anti-entropy repair (aka manual repair) is manually initiated operation performed on nodes as part of a regular maintenance process. This is initiated with nodetool repair command, which executes a major compaction. During a major compaction, the server initiates a TreeRequest/TreeResponse conversation to exchange Merkle trees with neighbouring nodes. The Merkel tree is a hash representing the data in that table. If the trees from different nodes don’t match, they have to be reconciled (repaired) to determine the latest data values they should all be set to. DynamoDB also use Merkle tress for anti-entropy, with a slightly different implementation.
Reference: