
When speaking about memory there are a few concepts that I had to wrap my head around. I’m hence putting them together for future reference. The fine details should be covered in any university course on computer architecture. To keep it simple, I’m only covering a high level in Linux. Much of the content below is from the book Systems Performances – Enterprise and the Cloud and Information and storage management.
Memory virtualization enables multiple applications and processes, whose aggregate memory requirement is greater than the available physical memory, to run on a host without impacting each other. Memory virtualization is an operating system feature that virtualizes the physical memory (RAM) of a host. It creates virtual memory with an address space larger than the physical memory space present in the compute system.
The virtual memory encompasses the address space of the physical memory and part of the disk storage. The operating system utility that manages the virtual memory is known as the virtual memory manager (VMM). The VMM manages the virtual-to-physical memory mapping and fetches data from the disk storage when a process references a virtual address that points to data at the disk storage. The space used by the VMM on the disk is known as a swap space. A swap space (also known as page file or swap file) is a portion of the disk drive that appears to be physical memory to the operating system.
In a virtual memory implementation, the memory of a system is divided into contiguous blocks of fixed-size pages. A process known as paging moves inactive physical memory pages onto the swap file and brings them back to the physical memory when required. This enables efficient use of the available physical memory among different applications. The operating system typically moves the least used pages into the swap file so that enough RAM is available for processes that are more active. Access to swap file pages is slower than access to physical memory pages because swap file pages are allocated on the disk drive, which is slower than physical memory.
Physical memory (aka main memory) – data exchange area of a computer (e.g. DRAM). It is usually fast, volatile and more expensive than disks. You know what i’m talking about ……
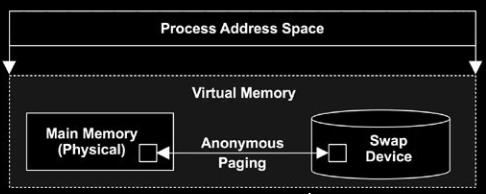
Virtual memory – this is an abstraction of memory presented to kernel and processes. It is (almost) infinite and non-contended. Some of its area are mapped to physical memory, and some can be mapped to storage device (i.e. disks). Virtual memory simplifies software development by leaving physical memory placement for the OS to manage. Most OS map virtual memory to physical memory only on demand, and the kernel strives to keep the most active data in physical memory.
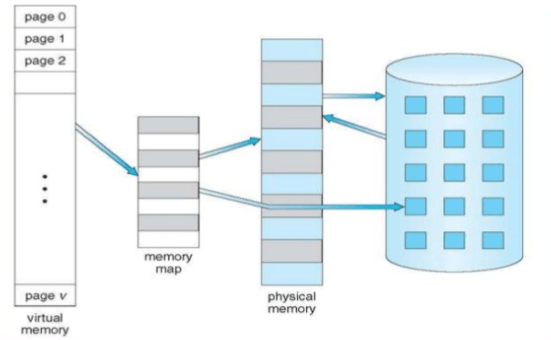
Paging – In the context of memory management scheme, the word paging simply refers to the technique that kernel moves small units of memory (aka. pages, usually 4KB or 8KB) to contain fragmentation. In this technique, physical memory is broken into fixed-sized blocks called frames, and logical memory is broken into blocks of the same size called pages.
Swapping – In (old-style) Unix, kernel can move the entire process between physical memory and storage device. This is the original Unix method. While it used to make sense in earlier generations of machines with maximum size of process size at 64KB. The cost on performance is significant so it is NOT supported by Linux anymore.
Paging – In comparison to swapping (of entire process), paging is a fine-grained approach to managing and freeing physical memory. Because the old unix-style swapping of entire threads and processes is phased out in the Linux world, the term swapping in Linux actually refers to paging. This can be confusing
Swap – an on-disk area for paged anonymous data and swapped processes. It can either be an area on a storage device (aka physical swap device), or just file (aka swap file) on a dedicated file system. The latter is usually more efficient. This post shows a little technique to tell what processes are using swap.
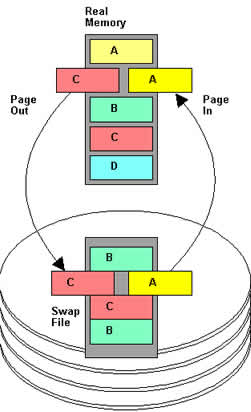
One reason that could account for system slowness is the large amount of swapping in and out. You can configure how Linux is likely to use swap by modifying swapiness value.
Address Space – a memory context. There are virtual address spaces for each process, and for the kernel.
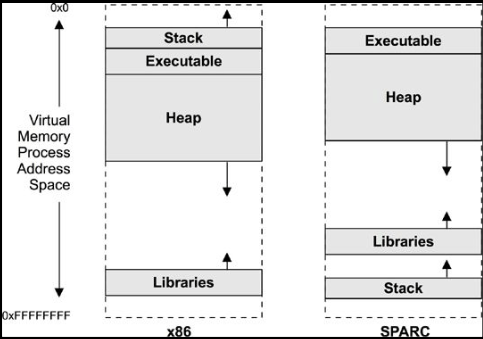
Process Address Space – a range of virtual pages that are mapped to physical pages as needed. It comprises of four segments:
* executable text- executable CPU instructions (read-only) for the process
* executable data – initialized variables mapped from the data segments of the binary program.
* heap – the working memory for the process, and is anonymous memory
* stack – stacks of running threads, mapped read/write
Resident memory – process can mark certain parts of virtual memory, such that OS is not permitted to swap them out to storage device, and they remain mapped to physical memory.
Anonymous memory – memory with no file system location or path name. It includes the working data of a process address space, called the heap.
Further details on resident memory and anonymous memory can be found here.
When application runs, I/O is a very slow step. Linux uses buffer and cache to optimize it. When operating system kernel receives a file I/O request, it first looks up the buffer and cache to see whether that region of the file is already available in main memory. If it is, a physical disk I/O can be avoided or deferred. Also, disk writes are accumulated in the buffer cache for several seconds, so that large transfers are gathered to allow efficient write schedules. All these efforts increase system performance.
Buffer – a memory area that stores data being transferred between an application and a device (or between two devices). The device can be either a disk or a network interface. It is to cope with the mismatch of speed, transfer-size between the producer and consumer of a data stream. When it comes to file systems, buffer only keeps file system metadata and tracks in-flight pages. Buffers remember what’s in directories, what file permissions are, and keep track of what memory is being written from or read to for a particular block device. For example, if you use find command for all files with .conf extension, run the command twice back to back, the second time would be faster.
Cache – a memory area that holds copies of data. Access to the cached copy is more efficient that access to the original. The cache keeps the content of the files that we have opened. For example, if you use vim to open a large file for twice back to back, you can usually tell that it is faster the second time.
One important difference between a buffer and a cache, is that a buffer may hold the only existing copy of a data item, whereas a cache, by definition holds a copy on faster storage of an item that resides elsewhere.
Further, as to how JVM manages (heap) memory and how garbage collection works, I found an article here with great insights.