
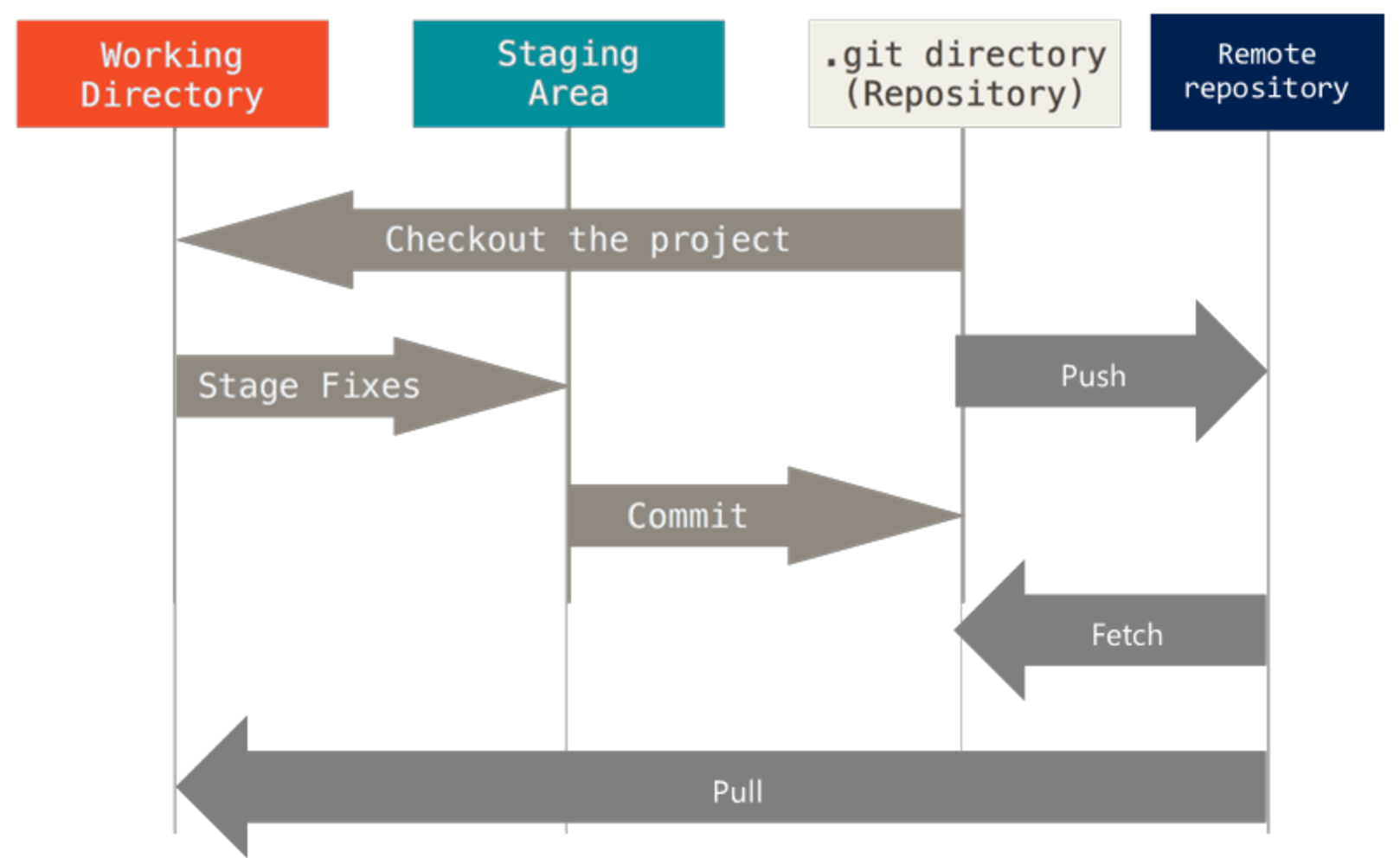
In a nutshell, Git is a distributed version control system, commonly used as source control management. It places files in one of three logical areas (working dir, staging, repo) below depending where it is in its lifecycle.
There are many cheetsheets out there but this article will just sort through some concepts unique to Git. To understand how Git works it is crucial to think in terms of Git data model.
Working directory a single checkout of one version of the project. These files are pulled out of the object database in the Git directory (upon checkout) and placed in the project directory on disk, for you to use or modify;
Index a file contained in your Git directory (stored as binary data in file .git/index) that keeps information about what will go into your next commit. To display what’s in the index, run `git ls-files –stage`. Read this post for further details
Repository: where Git stores the metadata and object database for your project. The local repository is in .git/ under the project directory.
Add – register one or more modified files to staging area. You may edit several files with only a few needed registered for future commit. Add activity ensures the file edited are recorded in the index (as a preview of next commit). You technically need to run add against each file. But the command syntax with * or . allows you to capture all edits in the same directory or under.
Commit – persist the staged file edits to the repository (so they are stored in Git object database). A commit represents all the file edits that were staged by add command in previous steps.
Branch – a branch is simply a movable pointer to a commit. Default branch name created by git init is called “master”. Other than the name, there is nothing special about master branch. Everytime you commit, the master branch pointer moves forward automatically. Branch pointers are kept in .git/refs directory. Read this post for further details.
HEAD – the pointer to the current branch reference, which is in turn a pointer to the last commit made on that branch. Git use HEAD pointer to know what branch you’re currently on. HEAD will be the parent of the upcoming commit.
Tag – an annotated tag contains the SHA of the commit being tagged. Alias of a commit.
Merge – choose current commit of other branch and apply it onto your branch.
Rebase – copy all commits from other branch to your branch. Compared to merge, rebasing forms a cleaner commit history.
Cherrypick – choose a previous commit from other branch and apply it onto your branch.
Stash – temporarily stashes changes you’ve made to working tree so you can work on something else, and then come back and re-apply them later on.
Reset – at a high level, reset is to revert some operations. After pulling code, developer usually follow three steps: editing->add->commit. reset is to reverse these steps, based on different modes. The Pro Git reference has further details on the three different modes:
- soft mode (reverse operation of commit): based on what branch HEAD points to, move where that branch points to (e.g. from latest commit, to a different commit several steps up the link);
- mixed mode (default; reverse operation of commit and add) – in addition to soft mode, also update index;
- hard mode (reverse operation of commit, add and file editing)- in addition to mixed mode, also update working directory. Edit on files are discarded.
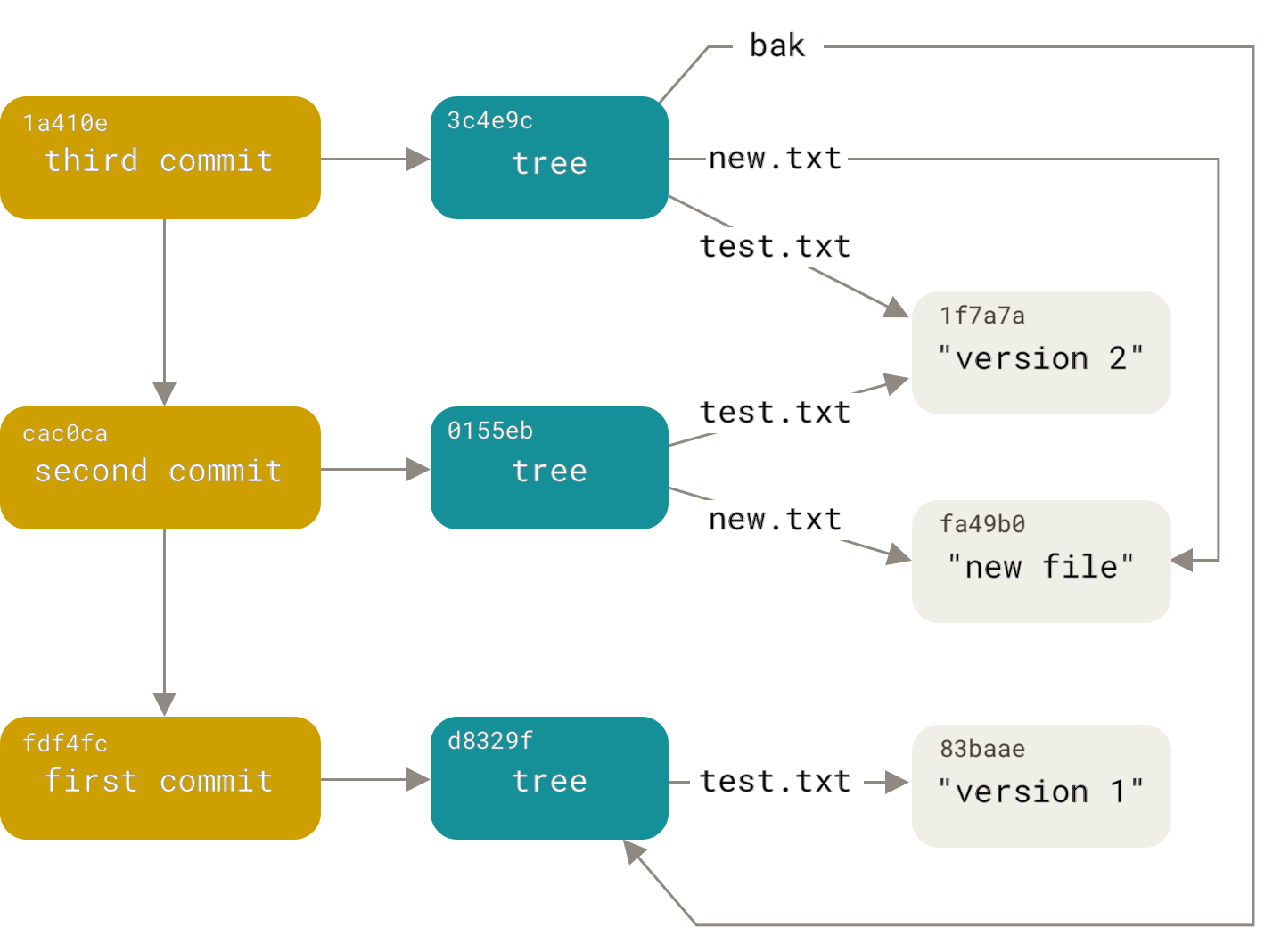
Git object model – In Git database, files, commits and directories are stored as objects, In Git object model, there are three types (to tell object type, run `git cat-file -t`). Read this post for further details:
- blob object – stores file data with metadata; use `git show` to examine blob object;
- tree object – represents a directory. It references other tree objects (sub-directories) or blob objects (files under the directory, of a certain version); use `git ls-tree` to examine tree object;
- commit object – represents a commit. It references its parent commit, as well as a tree object that represents the entire project directory. use `git cat-file -p` to inspect commit object;
This diagram from from Git Pro outlines the interactions amongst these types of objects.
For more details, the official documentation is actually the most helpful reference with illustrations. In addition, I find on Hakcermoon three excellent articles with thorough explanation on data model, branching and index.