
Business Continuity
Information Availability IA = MTBF/(MTBF+MTTR), where
* MTBF (Mean Time Between Failure) – average time available for a system or component to perform its normal operations between failures.
* MTTR (Mean Time to Repair) – the average time required to repair a failed component.
Disaster Recovery – the coordinated process of restoring systems, data, and the infrastructure required to support ongoing business operations after a disaster occurs. It is the process of restoring a previous copy of the data and applying logs or other necessary processes to that copy to bring it to a known point of consistency.
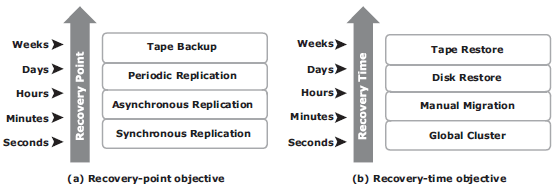
Recovery-Point Objective (RPO) – the point in time to which systems
and data must be recovered after an outage. It defi nes the amount
of data loss that a business can endure. A large RPO signifi es high tolerance
to information loss in a business.
Recovery-Time Ojbective (RTO) – The time within which systems and applications must be recovered after an outage. It defi nes the amount of downtime that a business can endure and survive. Businesses can optimize disaster recovery plans after defi ning the RTO for a given system.
Data Vault: a repository at a remote site where data can be periodically or continuously copied so a copy is always available in that site.
Hot site: A backup site running all the time.
Cold site: A backup site with minimum infrastructure, to be activated for operation in the event of disaster.
Server Clustering: a group of servers and relevant resources coupcled to operate as a single syste. Clusters can ensure high availability and load balancing.
Single Point of Failure – failure of a component that can terminate the availability of the entire system or IT service. To mitigate single point of failure, systems are designed with redundancy. This includes:
- redundant HBA on server
- NIC teaming
- redundant switch
- multiple storage array ports
- RAID and hot spare configuration
- Redundant storage array
- server clustering (e.g. clustered servers exchange heartbeat to inform each other about their health. If one of the servers fails, other server can take up the workload.
- VM Fault Tolerance
- Multipathing software: If one path fails, I/O does not reroute unless the system recognizes that it has an alternative path. Multipathing software provides the functionality to recognize and utilize alternative I/O paths to data. Multipathing software also managees the load balancing by distributing I/Os to all available, active paths.
Backup
Backup is an additional copy of production data created and retained for the sole purpose of recovering lost or corrupted data. Backup are typically performed for the following purposes:
- Disaster recovery. e.g. the backup copies are used for restoring data at an alternate site, when the primary site is incapacitated due to disaster.
- Operational recovery. e.g. accidental deletion, file corruption
- Archival. e.g. data is not changed or accessed any more.
Common considerations for backup includes: time interval between two backups (to meet RPO), retention period, media type (to meet RTO), granularity, compression and deduplication
Backup Granularity
- Full backup: backup of the complete data on the production volumes.
- Incremental backup: copies the data that has changed since the last full or incremental backup, whichever occurred more recently.
- Cumulative backup: copies the data that has changed since the last full backup.
Backup Methods
- hot backup/online backup: backup is completed while application is up and running;
- cold backup/offline backup: backup is completed while the application is shutdown for the backup window.
The hot backup of online production data is challenging because data is actively used and changed. If a file is open, it is normally not backed up during the backup process. In such situations, an open file agent is required to back up the open file. These agents interact directly with the operating system or application and enable the creation of consistent copies of open files. In database environments, To ensure a consistent database backup, all files need to be backed up in the same state. That does not necessarily mean that all files need to be backed up at the same time, but they all must be synchronized so that the database can be restored with consistency. The disadvantage associated with a hot backup is that the agents usually affect the overall application performance. If this is not acceptable, PIT (point-in-time) copy method can be utilized to create a PIT copy from the production volume and use it as the source for the backup. PIT copy method can reduce impact on production volume.
Typical Backup Architecture
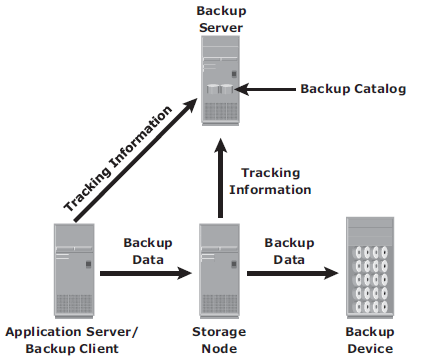
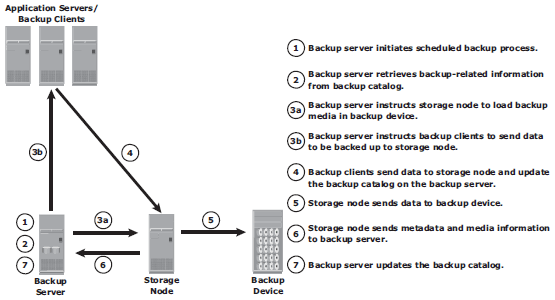
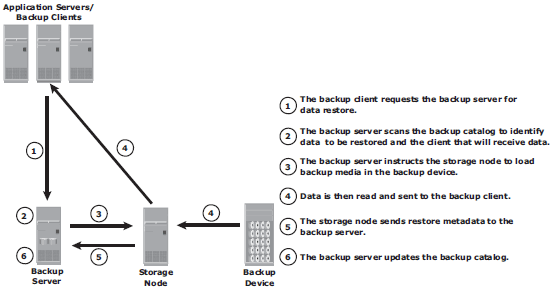
Backup topologies
Direct-attached backup: the storage node is configured on a backup client, and the backup device is attached directly to the client;
LAN-based backup: the clients, backup server, storage node, and backup device are connected to the LAN;
SAN-based backup (LAN-free): The SAN-based backup topology is the most appropriate solution when a backup device needs to be shared among clients;
Mixed topology: mix of LAN-based and SAN-based topologies;
NDMP protocol is for backup in NAS environment
Backup media
- Tape: for long-term offsite storage due to low cost. data access is sequential which implies slowness for both backup and restore. Tapes are susceptible to wear and tear.
- Disk: fast backup and retrieve to improve RPT and RTO. No offsite capability.
- Virtual Tape: virtual taps are disk drives emulated and presented as tapes to the backup software. VTL (virtual tape library) has the same components as that of a physical tape library.
Fig 10-18
Data deduplication – identify and eliminate redundant data to reduce backup window and size. Common data deduplication methods:
- file-level deduplication (aka. single-instance storage) detects and removes redundant copies of identical files. It enables storing only one copy of the file; the subsequent copies are replaced with a pointer that points to the original file.
- subfile deduplication breaks file into smaller chunks and then uses a specialized althorithm to detect redundant data within and across the file. This eliminates duplicate data across files. This has two forms:
* fixed-length block deduplication – divides the files into fi xed length blocks and uses a hash algorithm to fi nd the duplicate data.
* variable-length segment deduplication – if there is a change in the segment, the boundary for only that segment is adjusted, leaving the remaining segments unchanged.
Data deduplication implementation
- source-based data deduplication – eliminates redundant data at the source before it
transmits to the backup device. This requires less bandwidth and shortens backup window. It increases the overhead on the backup client and could impact the performance of the backup and application running on the client. - target-based data deduplication – deduplication occurs at the backup device, which offloads the backup client from the deduplication process. This takes two forms:
- inline deduplication – performs deduplication on the backup data before it is stored on the backup device. this reduces storage need, but introduces time overhead to identify and remove duplication. best for large backup window
- post-process deduplication – enables backup data to be stored on backup device first, and then deduplicate later. This is suitable for tighter backup windows, but requires more storage.
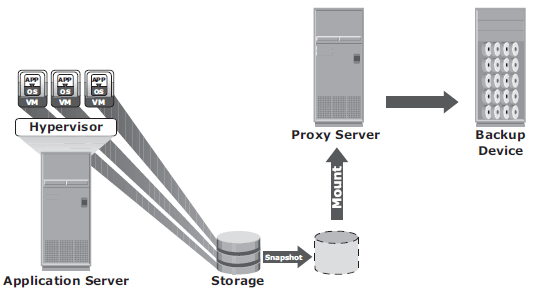
In virtualized environments, backup agent can be installed on the hypervisor, where the VMs appear as a set of files to the agent. VM files can be backed up by performing a file system backup from a hypervisor. For example, Image-based backup operates at hypervisor level and essentially takes a snapshot of the VM. It creates a copy of the guest OS and all the data associated with it (snapshot of VM disk files), including the VM state and application configurations. The backup is saved as a single file (an image) and mounted on a separate server as proxy, which acts as backup client.
Data archive
Archive – a repository where fixed content is stored. Fixed content can be data that were changed but will not be changed anymore.
Online archive: A storage device directly connected to a host that makes
the data immediately accessible.
Nearline archive: A storage device connected to a host, but the device where the data is stored must be mounted or loaded to access the data.
Offline archive: A storage device not ready to use. Manual intervention is required to connect, mount or load the storage device before data can be accessed.
An archiving agent is software installed on application server. The agent is responsible for identify data that can be archvied based on policy. After the data is identified for archiving, the agent sends the data to the archiving server. Then the original data on the application server is replaced with a stub file, which contains the address of the archived data.
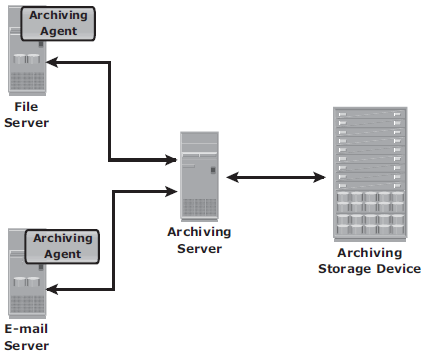
An archiving server is software installed on a host that enables administrators to configure the policies for archiving data. An archiving storage device stores fixed content.