Replication Terms
PIT (point in time) replica – snapshot of the source at some specific timestamp;
Continuous Replica – always in-sync with the production data;
Recoverability – enables restoration of data from the replica to the source if data loss or corruption occurs;
Restartability – enables restarting business operations using the replicas;
Local Replication
Use Case:
- Alternative source for backup
- Fast recovery
- Decision-support activities such as data warehousing
- Testing platform
- Data migration
Consistency in file system replication
File systems buffer the data in the host memory to improve the application response time. The buffered data is periodically written to the disk. In UNIX operating systems, sync daemon is the process that flushes the buffers to the disk at set intervals. In some cases, the replica is created between the set intervals, which might result in the creation of an inconsistent replica. Therefore, host memory buffers must be flushed to ensure data consistency on the replica, prior to its creation.
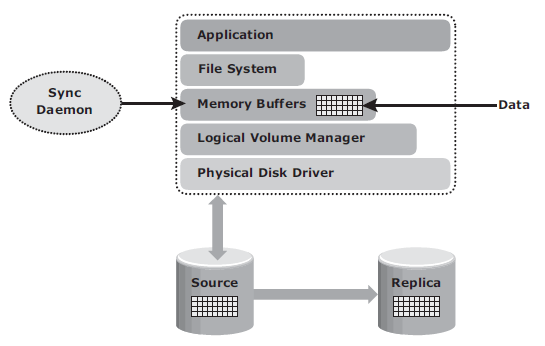
In the illustration above, If the host memory buffers are not flushed, the data on the replica will not contain the information that was buffered in the host. If the file system is unmounted before creating the replica, the buffers will be automatically flushed and the data will be consistent on the replica.
Consistency in database replication
When a database is replicated while it is online, changes made to the database at this time must be applied to the replica to make it consistent. A consistent replica of an online database is created by using the dependent write I/O principle or by holding I/Os momentarily to the source before creating the replica.
A dependent write I/O principle is inherent in many applications and database management systems (DBMS) to ensure consistency. According to this principle, a write I/O is not issued by an application until a prior related write I/O has completed. For example, a data write is dependent on the successful completion of the prior log write.
For a transaction to be deemed complete, databases require a series of writes to have occurred in a particular order. These writes will be recorded on the various devices or file systems.
Another way to ensure consistency is to make sure that the write I/O to all
source devices is held for the duration of creating the replica. This creates a
consistent image on the replica. However, databases and applications might time out if the I/O is held for too long.
Local Replication Technologies
Host-based Local Replication
- LVM-based replication: logical volume manager (LVM) is responsible for creating and controlling the host-level logical volumes. Each logical block in a logical volume is mapped to two physical blocks on two different physical volumes. LVM-based replication is part of operating system and comes without additional license cost. However, every write generated by application translates into two writes on the disk, and thus, an additional burden is placed on the host CPU. This can degrade application performance. Presenting an LVM-based logical replica to another host is usually not possible because the replica will still be part of the volume group, which is accessed by one host at any given time. You can’t track changes on LVMs either so it does not support incremental resynchronization.
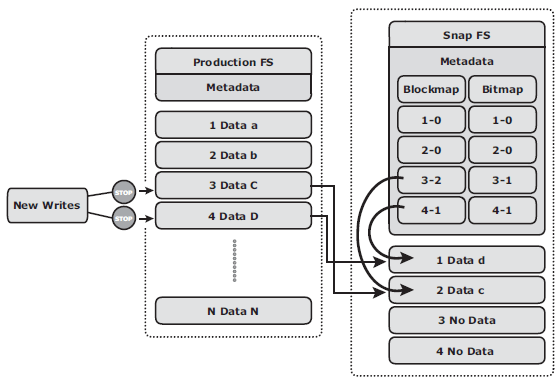
- File system snapshot: a pointer-based replica that requires a fraction of the space used by the production FS. This snapshot can be implemented by either FS or by LVM. It uses the Copy on First Write (CoFW) principle to create snapshot. When a snapshot is created, a bitmap and blockmap are created in the metadata of the Snap FS. The bitmap is used to keep track of blocks that are changed on the production FS after the snap creation. The blockmap is used to indicate the exact address from which the data is to be read when the data is accessed from the Snap FS. Immediately after the creation of the FS snapshot, all reads from the snapshot are actually served by reading the production FS. In a CoFW mechanism, if a write I/O is issued to the production FS for the fi rst time after the creation of a snapshot, the I/O is held and the original data of production FS corresponding to that location is moved to the Snap FS. Then, the write is allowed to the production FS. The bitmap and blockmap are updated accordingly. Subsequent writes to the same location do not initiate the CoFW activity. To read from the Snap FS, the bitmap is consulted. If the bit is 0, then the read is directed to the production FS. If the bit is 1, then the block address is obtained from the blockmap, and the data is read from that address on the Snap FS. Read requests from the production FS work as normal.
Storage Array-based local replication
the array-operating environment performs the local replication process. The host resources, such as the CPU and memory, are not used in the replication process. Consequently, the host is not burdened by the replication operations. The replica can be accessed by an alternative host for other business operations.
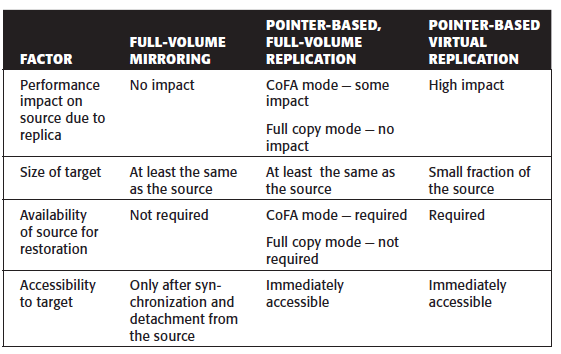
- Full-Volume Mirroring – the target is attached to the source and established as a mirror of the source. After all the data is copied and both the source and the target contain identical data, the target can be considered as a mirror of the source. After the synchronization is complete, the target can be detached from the source and made available for other business operations. The target becomes a point-in-time (PIT) copy of the source. After detachment, changes made to both the source and replica can be tracked at some predefined granularity. This enables incremental resynchronization (source to target) or incremental restore (target to source). The granularity of the data change can range from 512 byte blocks to 64 KB blocks or higher.
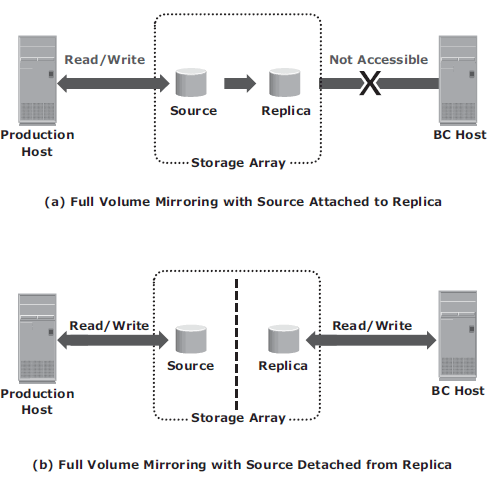
- Pointer-based, Full-Volume Replication – the target is immediately accessible by the BC host after the replication session is activated. Therefore, data synchronization and detachment of the target is not required to access it.
- Pointer-based, Virtual Replication – at the time of the replication session activation, the target contains pointers to the location of the data on the source. The target does not contain data at any time. Therefore, the target is known as a virtual replica. the target is immediately accessible after the replication session activation. A protection bitmap is created for all data blocks on the source device. Granularity of data blocks can range from 512 byte blocks to 64 KB blocks or greater.
Network-based local replication: the replication occurs at the network layer between host and storage arrays. By offloading replication from servers and arrays, network-based replication can work across a large number of server platforms and storage arrays, making it ideal for highly heterogeneous environments.
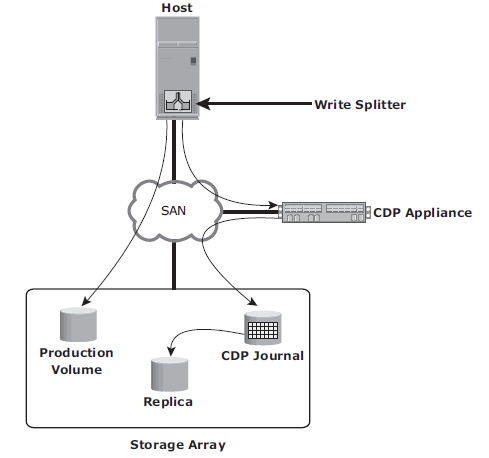
- Continuous Data Protection: CDP provides the ability to restore data to any previous PIT. In CDP, data changes are continuously captured and stored in a separate location from the primary storage. With CDP, recovery from data corruption poses no problem because it allows going back to a PIT image prior to the data corruption incident. CDP uses a journal volume to store all data changes on the primary storage. The journal volume contains all the data that has changed from the time the replication session started. The amount of space that is configured for the journal determines how far back the recovery points can go. CDP appliance is an intelligent hardware platform that runs the CDP software and manages local and remote data replications. Write splitters intercept writes to the production volume from the host and split each write into two copies. Write splitting can be performed at the host, fabric, or storage array.
- CDP Local Replication Operation: before the start of replication, the replica is synchronized with the source and then the replication process starts. After the replication starts, all the writes to the source are split into two copies. One of the copies is sent to the CDP appliance and the other to the production volume. When the CDP appliance receives a copy of a write, it is written to the journal volume along with its timestamp. As a next step, data from the journal volume is sent to the replica at predefi ned intervals.
Tracking Changes to Source and Replica
Changes can occur on the replica device if it is used for other business operations. To enable incremental resynchronization or restore operations, changes to both the source and replica devices after the PIT should be tracked.
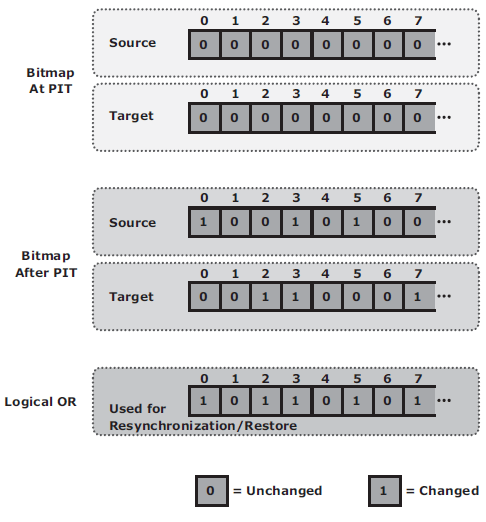
This is typically done using bitmaps, where each bit represents a block of data. For example, if the block size is 32 KB, then a 1-GB device would require 32,768 bits (1 GB divided by 32 KB). The size of the bitmap would be 4 KB. If the data in any 32 KB block is changed, the corresponding bit in the bitmap is flagged. If the block size is reduced for tracking purposes, then the bitmap size increases correspondingly.
The bits in the source and target bitmaps are all set to 0 (zero) when the replica is created. Any changes to the source or replica are then fl agged by setting the appropriate bits to 1 in the bitmap. When resynchronization or restore is required, a logical OR operation between the source bitmap and the target bitmap is performed. The bitmap resulting from this operation references all blocks that have been modifi ed in either the source or replica.
This enables an optimized resynchronization or a restore operation because it eliminates the need to copy all the blocks between the source and the replica. The direction of data movement depends on whether a resynchronization or a restore operation is performed.
If resynchronization is required, changes to the replica are overwritten with the corresponding blocks from the source. If a restore is required, changes to the source are overwritten with the corresponding blocks from the replica.
If a restore is required, changes to the source are overwritten with the corresponding blocks from the replica.
Local Replication in a Virtualized Environment
Typically, local replication of VMs is performed by the hypervisor at the compute level. However, it can also be performed at the storage level using array-based local replication, similar to the physical environment. In the array-based method, the LUN on which the VMs reside is replicated to another LUN in the same array. VM Snapshot captures the state and data of a running virtual machine at a specifi c point in time. The VM state includes VM files, such as BIOS, network confi guration, and its power state (powered-on, powered-off, or suspended). The VM data includes all the files that make up the VM, including virtual disks and memory. A VM Snapshot uses a separate delta file to record all the changes to the virtual disk since the snapshot session is activated. Snapshots are useful when a VM needs to be reverted to the previous state in the event of logical corruptions. Reverting a VM to a previous state causes all settings confi gured in the guest OS to be reverted to that PIT when that snapshot was created. There are some challenges associated with the VM Snapshot technology. It does not support data replication if a virtual machine accesses the data by using raw disks. Also, using the hypervisor to perform snapshots increases the load on the compute and impacts the compute performance.
Remote Replication
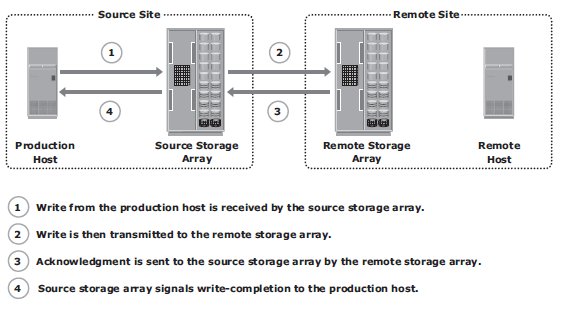
Synchronous remote replication – writes must be committed to the source and remote replica (or target), prior to acknowledging “write complete” to the host. Additional writes on the source cannot occur until each preceding write has been completed and acknowledged. This ensures that data is identical on the source and replica at all times. Further, writes are transmitted to the remote site exactly in the order in which they are received at the source. Therefore, write ordering is maintained. If a source-site failure occurs, synchronous remote replication provides zero or near-zero RPO. However, application response time is increased with synchronous remote replication because writes must be committed on both the source and target before sending the “write complete” acknowledgment to the host. The degree of impact on response time depends primarily on the distance between sites, bandwidth, and quality of service (QOS) of the network connectivity infrastructure.
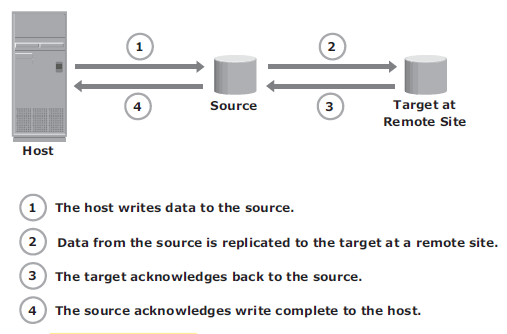
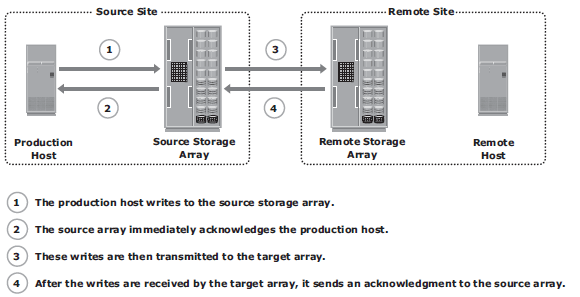
In asynchronous remote replication, a write is committed to the source and immediately acknowledged to the host. In this mode, data is buffered at the source and transmitted to the remote site later. Asynchronous replication eliminates the impact to the application’s response time because the writes are acknowledged immediately to the source host. This enables deployment of asynchronous replication over distances ranging from several hundred to several thousand kilometers between the primary and remote sites.
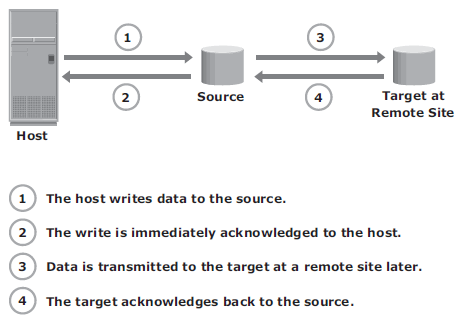
Below are the bandwith requirement for both:
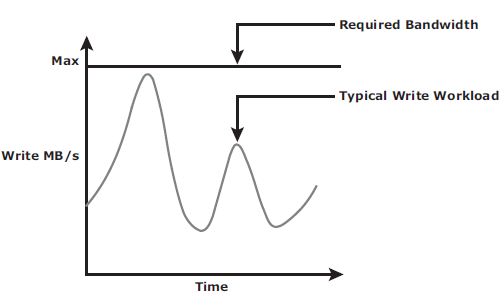
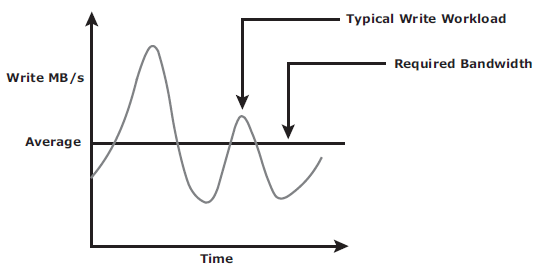
Asynchronous replication implementation can also take advantage of locality of reference (repeated writes to the same location). If the same location is written multiple times in the buffer prior to transmission to the remote site, only the final version of the data is transmitted. This feature conserves link bandwidth.
Remote Replication Technologies
Host-Based Remote Replication
LVM-based remote replication: performed and managed at the volume group level. Writes to the source volumes are transmitted to the remote host by the LVM. The LVM on the remote host receives the writes and commits them to the remote volume group.
LVM-based remote replication supports both synchronous and asynchronous modes of replication. LVM-based remote replication is independent of the storage arrays and therefore supports replication between heterogeneous storage arrays.
The replication process adds overhead on the host CPUs. CPU resources on the source host are shared between replication tasks and applications. Because the remote host is also involved in the replication process, it must be continuously up and available.
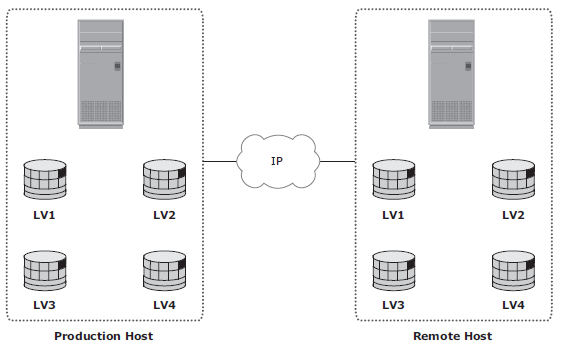
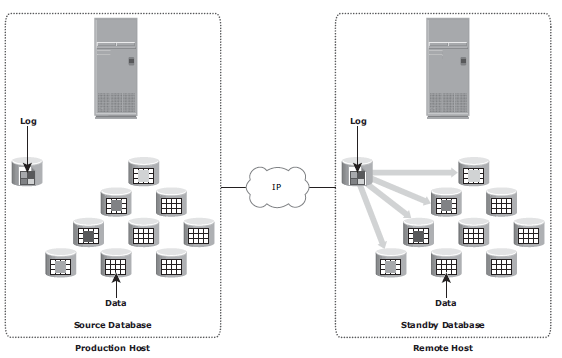
Host-Based Log Shipping
Database replication via log shipping is a host-based replication technology supported by most databases. Transactions to the source database are captured in logs, which are periodically transmitted by the source host to the remote host. The remote host receives the logs and applies them to the remote database.
RPO at the remote site is fi nite and depends on the size of the log and the frequency of log switching. Available network bandwidth, latency, rate of updates to the source database, and the frequency of log switching should be considered when determining the optimal size of the log file. Host-based log shipping requires low network bandwidth because it transmits only the log fi les at regular intervals.
Storage Array-Based Remote Replication
Synchronous replication mode
To optimize the replication process and to minimize the impact on application response time, the write is placed on cache of the two arrays. The intelligent storage arrays destage these writes to the appropriate disks later.
If the network links fail, replication is suspended; however, production work can continue uninterrupted on the source storage array. The array operating environment keeps track of the writes that are not transmitted to the remote storage array. When the network links are restored, the accumulated data is transmitted to the remote storage array. During the time of network link outage, if there is a failure at the source site, some data will be lost, and the RPO at the target will not be zero.
Asynchronous replication mode Fig 12-8
Data is buffered at the source and transmitted to the remote site later. The source and the target devices do not contain identical data at all times. The data on the target device is behind that of the source, so the RPO in this case is not zero. Asynchronous replication writes are placed in cache on the two arrays and are later destaged to the appropriate disks. Some implementations of asynchronous remote replication maintain write ordering. A timestamp and sequence number are attached to each write when it is received by the source. Writes are then transmitted to the remote array, where they are committed to the remote replica in the exact order in which they were buffered at the source. This implicitly guarantees consistency of data on the remote replicas.
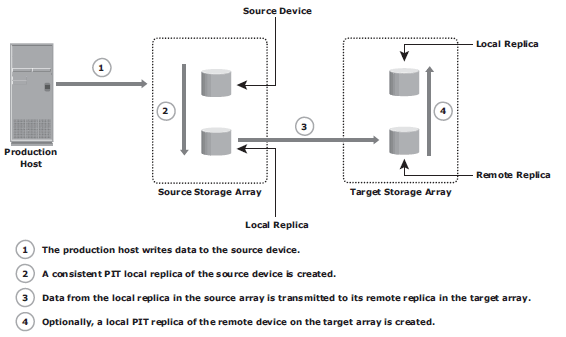
Disk-buffered replication mode: a combination of local and remote technologies. A consistent PIT local replica of the source device is fi rst created. This is then replicated to a remote replica on the target array.
At the beginning of the cycle, the network links between the two arrays are suspended, and there is no transmission of data. While production application runs on the source device, a consistent PIT local replica of the source device is created. The network links are enabled, and data on the local replica in the source array transmits to its remote replica in the target array.
Network-based Remote Replication
CDP remote replication
Fig 12-10
Three site replication
- Cascade/Multihop: data fl ows from the source to the intermediate storage array, known as a bunker, in the fi rst hop, and then from a bunker to a storage array at a remote site in the second hop. Replication between the source and the remote sites can be performed in two ways: synchronous + asynchronous or synchronous + disk buffered. Replication between the source and bunker occurs synchronously, but replication between the bunker and the remote site can be achieved either as disk-buffered mode or asynchronous mode.
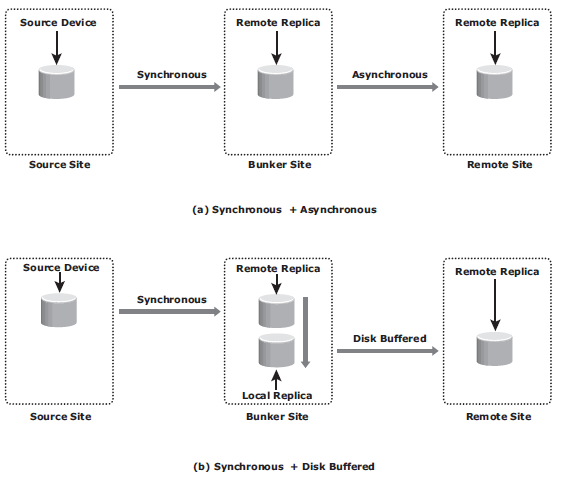
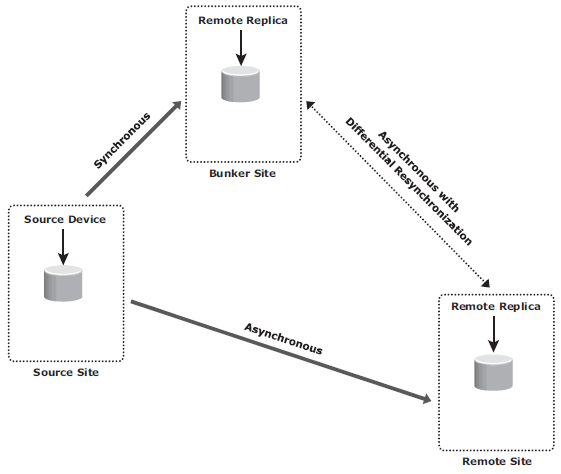
- Triangle/Multitarget: data at the source storage array is concurrently replicated to two different arrays at two different sites. The source-to-bunker site (target 1) replication is synchronous with a near-zero RPO. The source-to-remote site (target 2) replication is asynchronous with an RPO in the order of minutes. The distance between the source and the remote sites could be thousands of miles. The key benefit of three-site triangle/multitarget replication is the ability to failover to either of the two remote sites in the case of source-site failure, with disaster recovery (asynchronous) protection between the bunker and remote sites.
Data migration solutions
Data mobility refers to moving data between heterogeneous storage arrays for cost, performance, or any other reason. It helps implement a tiered storage strategy.
Data migration refers to moving data from one storage array to other heterogeneous storage arrays for technology refresh, consolidation, or any other reason. The array performing the replication operations is called the control array.
Data migration solutions perform push and pull operations for data movement.
These terms are defined from the perspective of the control array. In the push operation, data is moved from the control array to the remote array.
The control device, therefore, acts like the source, while the remote device is the target.
In the pull operation, data is moved from the remote array to the control array.
The remote device is the source, and the control device is the target.
The push and pull operations can be either hot or cold. These terms apply to the control devices only. In a cold operation the control device is inaccessible to the host during replication. Cold operations guarantee data consistency because both the control and the remote devices are offl ine. In a hot operation the control device is online for host operations. During hot push and pull operations, changes can be made to the control device because the control array can keep track of all changes and thus ensure data integrity.
Remote replication and migration in a virtualized environment
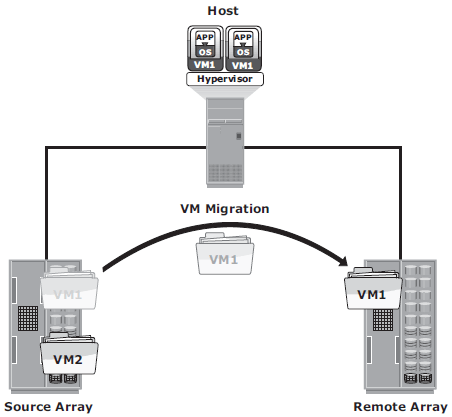
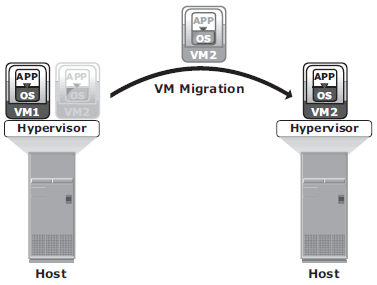
In hypervisor-to-hypervisor VM migration, the entire active state of a VM is moved from one hypervisor to another. This method involves copying the contents of virtual machine memory from the source hypervisor to the target and then transferring the control of the VM’s disk fi les to the target hypervisor. Because the virtual disks of the VMs are not migrated, this technique requires both source and target hypervisor access to the same storage.
In array-to-array VM migration, virtual disks are moved from the source
array to the remote array. This approach enables the administrator to move VMs across dissimilar storage arrays. Array-to-array migration starts by copying the metadata about the VM from the source array to the target. The metadata essentially consists of configuration, swap, and log files. After the metadata is copied, the VM disk file is replicated to the new location.