
EMC has several product lines for different use cases in enterprise data storage. Like may other IT solutions, the website is clouded with marketing terms and slogans, and is purposefully not technical. This makes it difficult for technical staff to grasp the advantage of its product in a glimpse. I personally have to know their product (mostly with Isilon and ECS) well in order to make integration decisions. So I’m putting together this note (updated as of July 2020), with lots of details from their technical white paper.
Overview of EMC storage
At the highest level, the EMC enterprise data storage product lines are categorized into two groups: primary storage (along the lines of block-level storage) and unstructured storage (mostly file and object storage). The primary storage includes the following product:
- PowerMax for OLTP database (Oracle, MicrosoftSQL and SAP)
- PowerFlex: for Software defined storage, Oracle RAC, Elastic Stack, Kubernetes, Splunk
- XtremIO for VMware, VDI, SAP
- PowerStore for Database, VMware
- PowerVault for Entry-level SAN and DAS environment
This post only expands on the unstructured storage product line, which mainly consists of PowerScale and ECS. ECS (elastic cloud storage) is EMC’s object storage. PowerScale (aka Isilon) is scale-out NAS platform for high-volume storage (up to 50 PB in a single file system), backup and archiving of unstructured data. For the rest of this post, I will still refer to PowerScale as Isilon.
Dell’s official support website is the most resourceful place to get information. For example, when I want to read about Isilon. I start with Dell support, then click on knowledgebase at the top, then go to “servers, storage and networking“, then “storage technical documents and videos“. There I can select a productline such as Isilon.
Overview of Isilon Family
Isilon is a clustered storage system consisting of three or more nodes. A node is a server with OneFS as its operating system. Based on FreeBSD, OneFS is EMC’s proprietary operating system to unify a cluster of nodes into a single shared resource. So OneFS is for Isilon only. It is the basis of Isilon. Isilon has three series of products:
- F series: F200, F600, F800 and F810.
- H series: typical models are H400, H500 and H600, which seeks to balance performance and capacity
- A series: typical models are A200 and A2000 for active and deep archive storage
In June 2020, Dell decoupled OneFS software (with 9.0 released) from server hardware (referred to as PowerScale). Going forward EMC will refer to Isilon as PowerScale for OneFS version newer than 9.0 in spec sheets and white papers.
F200 is the cost-effective choice with SSD for remote office, small hospital, retail outlets, IOT or factory floor. F600 uses NVMe drives instead, and has more ECC memory and faster ethernet backend network. and is higher than F200 in its use case. Both F200 and F600 provide inline data compression and deduplication capabilities. F800 and F810 both use SSD and they are similar. F800 comes with InfiniBand backend network and F810 provides inline data compression and deduplication capabilities. H series tries to strike a balance between performance and capacity so they are pretty much everything in betwee. On the other end, A200 and A2000 are almost the same except for capacity difference.
Isilon’s advantage
Isilon has lots of intelligence built into its solution compared to a traditional NAS. Here are some aspects from its product white paper:
| Aspects of Design | Isilon OneFS Scale-Out NAS | Traditional NAS |
|---|---|---|
| Network | Separation of front-end and back-end network to isolate node-to-node communication to a private low-latency network. Front-end traffic load balanced with SmartConnect | Single network for both external and internal traffic |
| File system structure and NameSpace | The storage is completely virtualized to users as a truly single file system with one namespace. There is no partitioning or volumes. The single file tree can grow organically without requiring planning or oversight about how the tree grows. SmartPool handles tiering of files to appropriate disk, without disrupting the single file tree. | An appearance of single namespace is typically achieved through namespace aggregation, where files are still managed in separate volumes, and a simple “veneer” layer glues individual directories to a “top-level” tree via symbolic links. LUNs and volumes, as well as volume limits are still present. Files have to be manually moved from volume-to-volume to load-balance. |
| Data Layout | OneFS controls the placement of file directly, down to the sector-level on any drive anywhere in the cluster. The addressing scheme for data and metadata is indexed at physical level by a tuple of {node, drive, offset} | Data are sent through RAID and volume management layers, introducing inefficiencies in data layout and providing non-optimized block access. |
| Redundancy Control | OneFS can flexibly control the type of striping as well as the redundancy level of the storage system at the system, directory and even file-levels. | The entire RAID volume is dedicated to a particular performance type and protection setting. |
Isilon terms
The Isilon technology re-implemented the read and write path during file storage and introduced several terms along with its technology.
SmartPools – Job that runs and moves data between the tiers of nodes within the same cluster. Also executes the CloudPools functionality if licensed and configured. FilePolicy is changelist-based SmartPools file pool policy job. SmartPoolsTree enforces SmartPools file policies on a subtree.
Storage Pools – Storage pools provide the ability to define subsets of hardware within a single cluster, allowing file layout to be aligned with specific sets of nodes through the configuration of storage pool policies. The notion of Storage pools is an abstraction that encompasses disk pools, node pools, and tiers.
Disk Pools – Disk pools are the smallest unit within the storage pools hierarchy. OneFS provisioning works on the premise of dividing similar nodes’ drives into sets, or disk pools, with each pool representing a separate failure domain. Disk pools are laid out across all five sleds in each node.
Node Pools – groups of disk pools, spread across similar storage nodes (or equivalent classes). Multiple groups of different node types can work together in a single, heterogeneous cluster. For example, one node pool of all-flash F-Series anodes, one node pool of H-series, and one node pool of A-series. Each node pool only contains disk pools from the same type of storage nodes.
Tiers – groups of nodepools combined into a logical superset to optimize data storage, according to OneFS platform type. this allows customers who consistently purchase highest capacity nodes available to consolidate a variety of node styles within a single tier, and manage them as one logical group. SmartPools users typically deploy 2 to 4 tiers. different node pools under a tier needs to be compatible.
Global Namespace Acceleration (GNA)’s principal goal is to help accelerate metadata read operations by keeping a copy of a cluster’s metadata on high performance, low latency SSD media.
SmartConnect is a load balancer that works at the front-end Ethernet layer to evenly distribute client connections across the cluster. SmartConnect supports dynamic NFS failover and failback to ensure that when a node failure occurs, or preventative maintenance is performed, all in-flight reads and writes are handed off to another node in the cluster to finish its operation without any user or application interruption.
Auto Balance reallocates and rebalances data and make storage space more usable and efficient.
SmartQuotas is directory-level quota management. Note: there is no partitioning, and no need for volume creation in OneFS.
SmartRead creates a data “pipeline” from L2 cache, prefetching into a local “L1” cache, on the captain node, in order to greatly improve sequential-read performance. For high-sequential cases, SmartRead can very aggressively prefetch ahead. SmartRead can control how aggresive the pre-fetching is, and how long data stays in the cache, and optimizes where data is cached.
In-line Data Reduction – the write path involves zero block removal, in-line deduplication, and in-line compression. This is supported in some models only.
Smart Dedupe – post-process, asynchronous deduplication. Smart Dedupe scans the on-disk data for identical blcoks and then eliminate the duplicates. After duplicate blocks are discovered, SmartDedupe movees a single copy of those blocks to a special set of files known as shadow stored. With post-process deduplication, new data is first stored on the storage device and then a subsequent process analyzes the data looking for commonality. This means that initial file write or modify performance is not impacted, since no additional computation is required in the write path, as opposed to in-line deduplication. This is supported on some models only.
OneFS SSD strategy – How OneFS leverage the SSD for performance. It has these options:
- L3 cache (implemented at nodepool level)
- metadata read
- metadata read/write
- Global Namespace Acceleration (GNA)
- Data on SSD
L3 cache consumes all the SSD in node pool. L3 cannot coexist with other SSD strategies, with the exception of GNA just because L3 cache node pool SSD cannot participate in GNA.
Isilon’s High Availability
The OneFS is distributed across all nodes in the cluster and is accessible by clients connecting to any node in the cluster. Metadata and locking tasks are managed by all nodes collectively and equally in a peer-to-peer architecture. This symmetry is key to the simplicity and resiliency of the architecture. There is no single metadata server, lock manager or gateway node.
The entire cluster forms a single file system with a single namespace that runs across every node equally. No one node controls or “masters” the cluster; all nodes are true peers.
During failover, clients are evenly redistributed across all remaining nodes in the cluster, ensuring minimal performance impact. If a node is brought down for any reason, including a failure, the virtual IP addresses on that node is seamlessly migrated to another node in the cluster. When the offline node is brought back online, SmartConnect automatically rebalances the NFS and SMB3 clients across the entire cluster to ensure maximum storage and performance utilization. This functionality allows for per-node rolling upgrades affording full-availability throughout the duration of the maintenance window.
There are two logical roles in processing an I/O request from client:
- The initiator: the node that the client connects to with front-end protocol. The initiator acts as the ‘captain’ for the entire I/O operation.
- The participant: Every node in the cluster is a participant for a particular I/O operation.
File Write in Isilon
OneFS employs a patented transaction system during write to eliminate single point of failure. In a write operation, the initiator “captains” or orchestrates the layout of data and metadata, the creation of erasure codes, and the normal operations of lock management and permission control.
When a client connects to a node to write a file, it is connecting to the Initiator. OneFS breaks the file down into atomic units. An atomic unit is a smaller logical chunk of data, also called stripe, or protection groups in the context of data protection. The size of each file chunk is referred to as the stripe unit size. After this division, OneFS then write the stripe individually to the Participant (with disks). This design ensures that data is protected at the specified level as soon as it is being written. Redundancy is built into protection groups, such that if every protection group of a file is safe, then the entire file is safe. In terms of protection mechanism, OneFS can use either Reed-Solomon erasure coding system, or simply mirroring for data protection. Erasure coding is the predominant mechanism with very high performance without sacrificing on-disk efficiency.
The initiator node uses a modified two-phase commit transaction to safely distribute writes to multiple NVRAMs across the cluster. As client initiates write to OneFS cluster, instead of immediately writing to disk, OneFS temporarily writes the data to an NVRAM-based journal cache on the initiator node and acknowledge the write the client. As outlined above, these writes are also mirrored to participant nodes’ NVRANM journals to satisfy the file’s protection requirement. Later, at a more convenient time, OneFS then flush these cached writes to disks asynchronously.
Since NVRADM journals all the transactions that are occurring across every node in the storage cluster. If a node fails mid-transaction, and then re-joins the cluster, the uncommitted cached writes are fully protected, and the only required actions for the node, are to replay its journal from NVRAM, and occasionally for AutoBalance to rebalance files that were involved in the transaction. Writes are never blocked due to a failure. There is no ‘fsck’ or ‘disk-check’ process.
OneFS file system block size is 8KB. A file smaller than 8KB will use a full 8KB block. For larger files, OneFS can maximize sequential performance by taking advantage of a stripe unit consisting of 16 contiguous blocks, for a total of 128KB per stripe unit.
Cache in Isilon
OneFS aggregates the cache present on each node in a cluster into one globally accessible pool of memory by using a messaging system similar to NUMA (non-uniform memory access). This allows all the nodes’ memory cache to be available to each and every node in the cluster. Remote memory is access over internal network with much lower latency than accessing hard disk drives. The internal network as distributed system bus, is a redundant, under-subscribed flat Ethernet up to 40Gb. The oneFS caching subsystem is coherent across the cluster, due to the use of MESI protocol to maintain cache coherency. If the same content exists in the private caches of multiple nodes, this cached data is consistent across all instances.
OneFS uses up to three levels of read cache, plus an NVRAM-backed write cache, or coalescer.
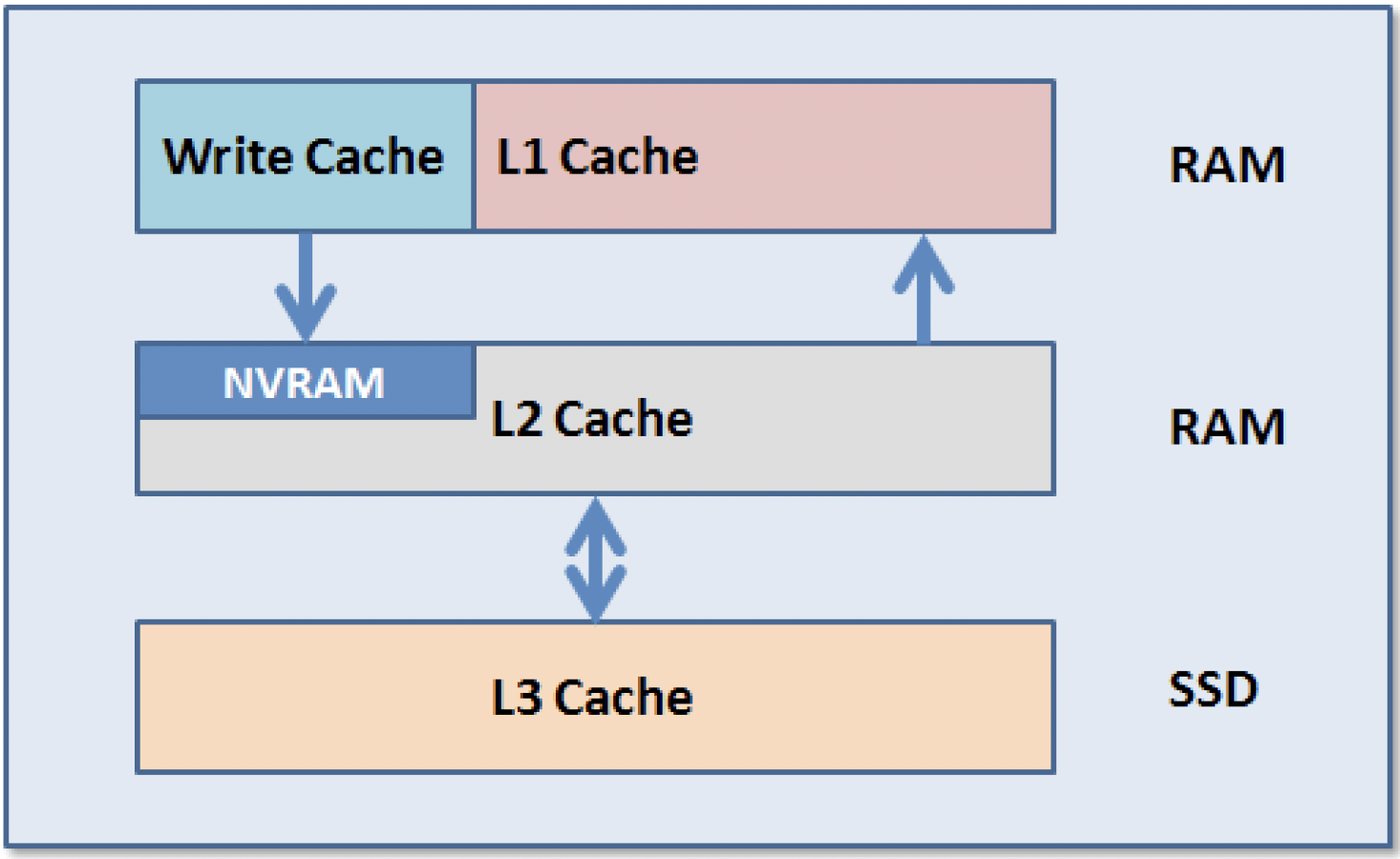
L1 cache – prefetches data from remote nodes. Data is prefetched per file, and this is optimized in order to reduce the latency associated with the nodes’ back-end network. The L1 cache refers to memory on the same node as the initiator. It is only accessible to the local node, and typically the cache is not the master copy of the data.
L1 is also known as remote cache because it contains data retrieved from other nodes in the cluster. It is coherent across the cluster but is used only by the node on which it resides and is not accessible by other nodes. Data in L1 cache on storage nodes is aggressively discarded after it is used. L1 cache uses file-based addressing, in which data is accessed via an offset into a file object.
OneFS also uses a dedicated inode cache in which recently requested inodes are kept. The inode cache frequently has a large impact on performance, because clients often cache data, and many network I/O activities are primarily requests for file attributes and metadata, which can be quickly returned from the cached inode.
L2 cache (backend cache) refers to local memory on the node on which a particular block of data is stored. L2 cache is globally accessible from any node in the cluster and is used to reduce the latency of a read operation by not requiring a seek directly from the disk drives.
L2 cache is also known as local cache because it contains data retrieved from disk drives located on that node and then made available for requests from remote nodes. Data in L2 cache is evicted according to a Least Recently Used (LRU) algorithm.
L3 cache, or Smart Flash, is configurable on nodes that contain solid state drives. Smart Flash (L3) is an eviction cache that is populated by L2 cache blocks as they are aged out from memory.
During I/O request, clients talk to L1 cache and write coalescer; L1 cache talks to L2 cache on all cluster nodes. L2 cache buffers to and from disks. L3 cache is optionally enabled per node pool, as an extension from L2. L3 and L2 communicate in backend network.
| Name | Medium | Description |
| L1 Cache (aka front-end cache or remote cache) | RAM (volatile) | holds clean, cluster coherent copies of file system data and metadata blocks requested by clients via front-end network |
| L2 Cache (aka back-end cache or local cache) | RAM (volatile) | contains clean copies of file system data and metadata on a local node |
| SmartCache (Write Coalescer) | Battery-backed NVRAM (Persistent) | a persistent journal cache that buffers any pending writes to front-end files that have not been committed to disk |
| SmartFlash or L3 Cache | SSD (persistent) | contains file data and metadata blocks evicted from L2 cache, effectively increasing L2 cache capacity |
File Read in Isilon
The high-level steps for fulfilling a read request with cache interaction involves:
Step 1 – on local node, determine whether part of the requested data is in the local L1 cache:
- if so, return to client
- if not, request data from remote nodes
Step 2 – on remote nodes, determine whether requested data is in the local L2 or L3 cache:
- if so, return to the requesting node
- if not, read from disk and return to requesting node
During a read operation, the “captain” node gathers all of the data from the various nodes in the cluster and presents it in a cohesive way to the requestor.
The cluster provides a high ratio of cache to disk (multiple GB per node) that is dynamically allocated for read and write operations as needed. This RAM-based cache is unified and coherent across all nodes in the cluster, allowing a client read request on one node to benefit from I/O already transacted on another node. As the cluster grows larger, the cache benefit increases. For this reason, the amount of I/O to disk on a cluster is generally substantially lower than it is on traditional platforms.
For files marked with an access pattern of concurrent or streaming, OneFS can take advantage of pre-fetching of data based on heuristics used by the SmartRead component
Conclusion
This post provided a high level introduction to EMC storage product line and expanded into some technical details in the read write operation in OneFS/Isilon. Some of the features can be seen in OneFS simulator which is a free tool from EMC.