
Distributed systems
Distributed system involves independent computing entities linked together by network. The components communicate and coordinate with each other to achieve a common goal. In early days, designers and developers often had made some assumptions (aka. fallacies) of distributed computing:
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- Network is secure
- Topology doesn’t change: in reality, components to a network get removed/added over time. the system should tolerate such changes.
- There is one administrator: for distributed systems to function, they interact with external system beyond administrative control.
- Transport cost is zero: cost is involved everywhere, in the form of CPU cycles spent, to actual dollars paid to service provider.
- Network is homogenous
These fallacies make coordinating distributed computing entities a huge challenge and Zookeeper is introduced to address these challenges. Zookeeper implements common tasks for distributed coordination, such as:
- Configuration Management (propagate configuration changes to all worker nodes dynamically)
- Naming service
- Distributed synchronization (locks and barriers)
- Cluster membership operations (e.g. detection of node leave/join)
ZooKeeper is a centralized coordination service for the distributed application. ZooKeeper itself is distributed as well. It runs on its own cluster of servers called a ZooKeeper ensemble, separate from application’s cluster. Distributed consensus, group management, presence protocols, and leader election are implemented by the service so that the application developers do not need to reinvent the wheel by implementing them on their own.
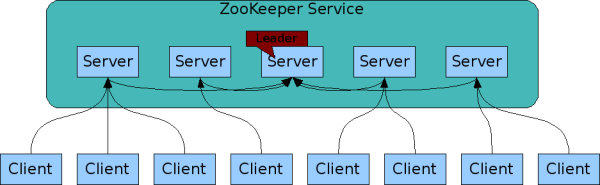
Developers will have to use APIs through ZooKeeper’s client library, which has language bindings for almost all popular programming languages. The client library is responsible for the interactions of an application with the ZooKeeper service. For testing with API access one can alternatively use its Java-based command-line shell (zkCli.sh)
$ zkCli.sh -server zknode:2181
How Zookeeper works
Data Model
ZooKeeper allows distributed process to coordinate with each other through a shared hierarchical namespace of data registers (znodes). The hierarchy start with root node which has child znode(s). Each znode can have their children, as well as store its own data (hence the name data register). The data in a znode is stored in byte format for a maximum of 1MB (ZooKeeper by design is just a coordinator service of host application, so its own data set size is fairly small).
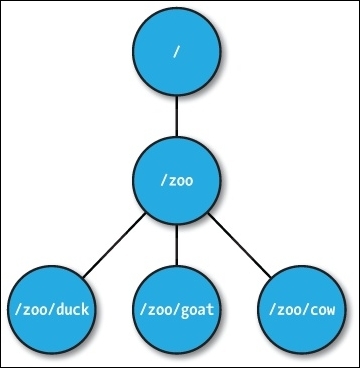
Znodes have two types (set at time of creation)
- persistent znode: for storing persistent data, such as configuration. The znodes and their data will exist even if the creator client dies.
- ephemeral znode: deleted by ZooKeeper service when the creating client’s session ends (due to disconnection or explicit termination). It can also be explicitly deleted by creator client through delete API call. They cannot have children. Their visibility is controlled by ACL policy
ZooKeeper can assign an incremental sequence number as part of znode name during its creation. This makes a sequential node. Both persistent znode and ephemeral znode can be either sequential or not.
In typical client-server architecture, server is passively open and do not initiate communication to client. Client pulls information from server. This is however an anti-pattern for large scale distributed system. ZooKeeper implements a Watch mechanism where clients can get notifications from ZooKeeper service, instead of having to poll for events. Clients can register with the ZooKeeper service (by setting a watch on znode) for any changes associated with a znode. A watch will only trigger notification once, and needs to be re-registered (by client) for trigger the next notification. A watch is triggered upon:
- Any changes to the data of a znode;
- any changes to the children of a znode;
- Creation of deletion of a znode
ZooKeeper guarantees that notifications are delivered in the order of event occurrence. When a client disconnects from ZooKeeper server, it doesn’t receive any watches until the connection is re-established.
API Operations
The ZooKeeper operations are:
| Operation | Description |
| create | Creates a znode in the specified path |
| delete | Deletes a znodes from the specified path. Not allowed if the znode has children. version number required |
| exists | Check if a znode at the specified path exists, and get version number; support watch |
| getChildren | Get a list of children of a znode; support watch |
| getData | get the data associated with a znode; support watch |
| setData | writes data into the data field of a znode. Version number required. |
| getACL | get the ACL of a znode |
| setACL | set the ACL in a znode |
| sync | synchronizes a client’s view of a znode |
The write operations (setData, create, delete) are atomic, durable and eventually consistent. Every znode has a stat structure including cZxid, mZxid an dpZxid that keeps track of the ID of the transactions that created, last modified this znode, or pertains to adding or removing its children.
Production znode ensemble with more than one node is running in quorum mode. Updates to ZooKeeper tree by clients must be persistently stored in this quorum of nodes for a transaction to be completed successfully. Odd number of node is recommended to avoid split-brain where network partition causes two subsets of servers in the ensemble function independently, and different clients get different results for the same requests, depending upon the server they are connected to.
All ZooKeeper nodes are listed in the configuration for client application to randomly pick from and try to connect and establish a session. The session is associated with every operation the client executes in a ZooKeeper service. The session also has a timeout period specified by the application client during session establishment. If the connection remains idle for more than the timeout period, the server expires the session. Appropriate session timeout should be set based on network condition. Sessions are kept alive by client sending heartbeat to ZooKeeper service. Application developer needs to handle connection-loss scenarios properly.
Leader Election and Atomic Broadcast
ZooKeeper ensemble contains a leader nodes, follower nodes and observer nodes.
- The leader node is elected by the cluster. It handles all write requests.
- The follower nodes are leader candidates that are not elected. They are backup to the leader nodes. They handle read request, and receive the updates proposed by the leader, and through a majority consensus mechanism, a consistent state is maintained across the ensemble.
- The observer nodes are ineligible as leader candidates. They have otherwise the same function as followers.
The service relies on the replication mechanism to ensure that all updates are persistent in all servers that constitute the ensemble. This is the core mechanism in ZooKeeper, implemented as a special atomic messaging protocol called ZooKeeper Atomic Broadcast (ZAB). ZAB (a variant of Paxos algorithm) ensures the election of new leader in the event of old leader crash, and ensures integrity of data. It defines three states (looking, following and leading) of a node, and goes through four phases (election, discovery, sync, broadcast) in its operation.
All read requests (exists, getData, getChildren) are process locally by the ZooKeeper node where the client is connected to. This makes read operation fast. All write requests (create, delete, and setData) are forwarded to the leader in the ensemble, which carries out the client request as a transaction. A transaction is identified by zxid and is idempotent. Transaction also satisfies the property of isolation (no transaction is interfered with by any other transaction). Only after a majority of the followers acknowledge that they have persisted the change does the leader commit the update.
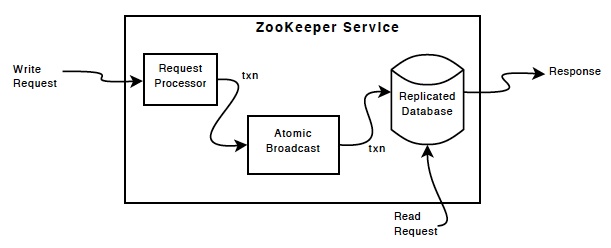
Transaction processing involves two steps in ZooKeeper: leader election and atomic broadcast. This resembles a two-phase commit protocol (which also includes a leader election and an atomic broadcast)
ZooKeeper use local storage to persist transactions. The transactions are logged to transaction logs, in sync’ed write, requiring a dedicated block device separated from boot device of server. The local storage also keep point-in-time copies (snapshots) of the ZooKeeper tree.
ZooKeeper Recipes
The ZooKeeper recipes defines high-level implementation (construct) of some common distributed coordination mechanism:
- Barrier: any thread/process must stop at this point and cannot proceed until all other threads/processes reach this barrier.
- Queue: allow FIFO in distributed system
- Lock: Fully distributed locks that are globally synchronous, meaning at any snapshot in time no two clients think they hold the same lock.
- Leader Election: designate a single process as the organizer of some task distributed among several nodes.
- Group membership: node may join or leave a group, which needs to be made available to clients. An alternative to ZooKeeper to manage group membership is gossip protocol.
- Service discovery: help client to determine IP and port for a service that are hosted by multiple servers.
- Two-phase commit: a mechanism for atomic commitment in two steps: first a commit request phase involving a voting by participants; and second, either a commit action, or an abort action, based on the voting result.
Zookeeper Administration
The official documentation includes all we need to know about administration. In addition, we need to configure log4j for proper logging. As best practices, we also should turn off swapping on ZooKeeper. We should clean up the data directory periodically if auto purge is not enabled. For optimal performance, ZooKeeper transaction log should be configured in a dedicated device.
For monitoring, ZooKeeper responds to a small sets of four-letter commands issued through telnet or nc to server’s client port. This allows the admin to check health of server or diagnose any problems. This requires the following property in zoo keeper config:
4lw.commands.whitelist=stat, ruok, conf, isro, wchc
The value can be set to asterick to allow all four-letter keyword. Once enabled, we can check server status
$ echo ruok | nc localhost 2181
imok
More four-letter commands are listed here. Apart from the four-letter commands, ZooKeeper can also be managed through Java Management Extensions (JMX).
Conclusion
Apache ZooKeeper is a coordination service for distributed application. It has become the solution for high availability for many other projects. Some of Apache’s well known open-source distributed services include:
- Apache Hadoop (an umbrella of projects including many components for BigData processing such as Hadoop Common, Hadoop Distributed File System (HDFS), Hadoop YARN (yet another resource negotiator) and Hadoop MapReduce)
- Apache HBase: non-relational database on top of HDFS
- Apache Hive: data warehouse with SQL-like interface
- Apache Kafka: stream processing
- Apache Nifi: automated data flow processing.
Some of them, such as Nifi, has an embedded implementation of ZooKeeper ensemble if there isn’t a separate ensemble. There is some limitation with embedded Zookeeper ensemble. First, we cannot start ZooKeeper without starting Nifi service on the same server. Second, we need to orchestrate the configuration so that the ZooKeeper ensemble does not grow too large. We need to keep in mind that the ZooKeeper ensemble is a separate cluster of its own, and the it is not recommended to have more than 7 nodes on ZooKeeper.