
This is an overview of the underlying technologies that drives load balancing. It covers LVS, Netfilter, iptables, IPVS and eventually kube-proxy.
LVS (Linux Virtual Server)
One of the ways to implement software load balancing is via LVS (Linux Virtual Server), as previously discussed. The diagram below shows the LVS framework, with IPVS as the fundamental technology:
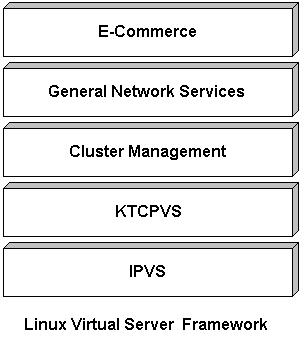
The major work of the LVS project is to develop advanced IP load balancing software (IPVS), application-level load balancing software (KTCPVS), cluster management components. KTCPVS implements application-level load balancing inside the Linux kernel (still under development). IPVS is an advanced IP load balancing software implemented inside the Linux kernel. The IPVS code was already included into the standard Linux kernel 2.4 and 2.6.
Netfilter
Both IPVS and iptables (the technology behind Linux firewall, discussed here) are based on netfilter, a packet-filtering framework provided by the Linux kernel. In this section, we will discuss them all together, starting with Netfilter and then discuss how iptables and IPVS uses netfilter.
Netfilter allows various networking-related operations to be implemented in the form of customized handlers, by offers various functions and operations for packet filtering, network address translation, and port translation, which provide the functionality required for directing packets through a network and prohibiting packets from reaching sensitive locations within a network. Netfilter represents a set of hooks inside the Linux kernel, allowing specific kernel modules to register callback functions with the kernel’s networking stack. Those functions, usually applied to the traffic in the form of filtering and modification rules, are called for every packet that traverses the respective hook within the networking stack.
Iptables
The kernel modules named ip_tables, ip6_tables, arp_tables (the underscore is part of the name), and ebtables comprise the legacy packet filtering portion of the Netfilter hook system. They provide a table-based system for defining firewall rules that can filter or transform packets. The tables can be administered through the user-space tools iptables, ip6tables, arptables, and ebtables. Notice that although both the kernel modules and userspace utilities have similar names, each of them is a different entity with different functionality.
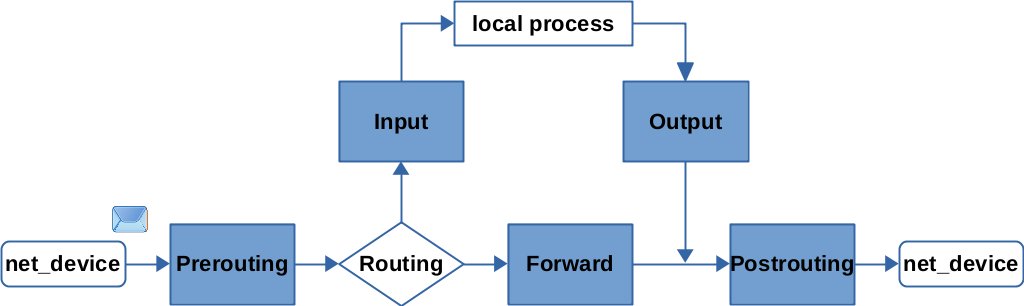
When a network packet is received on a network device, it first passes through the Prerouting hook. This is where the routing decision takes place. The kernel decides whether the packet is destined for a local process (e.g., a listening socket on a server in this system) or whether to forward it (system operates as a router). In the first case, the packet passes the Input hook and is then handed over to the local process. If the packet is destined to be forwarded, it traverses the Forward hook and then a final Postrouting hook before being sent out on a network device. For packets that are generated locally (e.g., by a client or server process that likes sending things out), they must first pass the Output hook and then the Postrouting hook before being sent out on a network device.
The aforementioned hooks exist independently for the IPv4 and IPv6 protocols. Thus, IPv4 and IPv6 packets each traverse their own hooks. There are also other hooks for ARP packets and for Bridging. And all the hooks exist independently within each network namespace. Additionally, there is an ingress hook for each network device. The list goes on… More explanations are from here and here.
IPVS
In LVS, IPVS is also based on netfilter framework, but works only on INPUT chain, by registering ip_vs_in hook function, to process request. IPVS (aka layer-4 switching) runs on a host at the front of a cluster of real servers. It directs requests for TCP/UDP based servers to the real server, while ensuring the resonse from (one or several) real server appears to the client as if they were all from a virtual service on a sigle IP address. It is based on in-kernel hash tables. The userspace utility is ipvsadm.

When the client request reaches the kernel space of load balancer, it arrives at PREROUTING chain. Route will determine whether the request packet is for the local host or not, based on the destination address of the packet. The packet is sent to INPUT chain if it is. The ip_vs_in function is hooked to LOCAL_IN and will examine the packet. If it finds a matching IPVS rule, it will (bypass INPUT chain) directly trigger POSTROUTING chain, skipping iptables rules.vThis is discussed in detail here.
IPVS supports 8 load balancing algorithms (round robin, weighted round robin, least-connection, weighted least connection, locality-based least-connection, locality-based least-connection with replication, destination-hashing, and source-hashing) and 3 packet-forwarding methods (NAT, tunneling and direct routing).
The main difference between iptables and IPVS, is iptables includes a number of tables, each with a number of chains, each further involves a number of rules. The total number of rules is large. The packet is assessed against many of such rules. For the same reason, the order of the rule matters. IPVS on the other hand, leverages hash table, with a complexity of O(1), or O(n) in the worst case scenarios. They vary significantly in the efficiency of packet filtering and forwarding, especially when the rules gets complicated. Iptable also presents more latency when adding or removing rules as more rules are involved. This presentation includes some quantitative comparison.
KubeProxy
In Kubernetes architecture, KubeProxy takes care of load balancing. Kube-proxy can run in three modes: userspace, iptables and IPVS.

The userspace mode is old and inefficient. The packet is compared against iptables rule and then forwarded to a pod named kube-Proxy, which operates as an application to forward packet to backend pods.

The iptables mode is better since it uses the kernel feature of iptables, which is fairly mature. kube-proxy manages iptables rule based on the service yaml of Kubernetes.

With the comparison between iptables and IPVS earlier, we can expect that iptables operations slow down dramatically in large scale cluster. Therefore IPVS based kubeproxy was brought up. This presentation illustrated the differences.
In this post we discussed load balancing technologies from ipvs to iptables and then to kube-proxy, which is used in Kubernetes nodes.