
Statistics Canada carries census every 5 years, with 2016 being the last run. The census data by Statistics Canada provides a wealth of insights but are published in raw format. Post-processing work is needed to extrapolate information, such as median income of a neighbourhood, age distribution of a city, etc. For someone like myself without any background in geographical informatics, it took a bit of learning to see how these work together.
The following information are typically included in the Census data:
- Population
- Population density
- Age
- Structural type of dewellings
- Family size
- Marital status
- Language
- Income
- Place of birth
- Level of education
- Occupation
We will start with level of Geographics. The level of geographics may change slightly between census programs in different years. The most recent 2016 census uses the following diagram to depict levels of geographics:

This diagram reflects a number of different hierarchies of geographic units. The best resource to understand each block, is the illustrated glossary and the chapter Census Geography in comprehensive Guide to the Census Population. For example, the chain on the far left of the diagram runs across these levels:
In this hierarchy, the level of Geographical Region of Canada is standardized in Standard Geographic Classification (SGC), in which the provinces and territories are also encoded. Note that each Census include a dictionary where all sorts of codes are kept. The dictionary also includes definition of the rest two levels: FSA (forward sortation area as the first three digits of postal code) and postal code (all six digits). Note that postal code is a mark of Canada Post Corporation, and you may translate postal code into other levels in standard geographic areas, such as CD. This is not straightforward though. You will need a product called Postal Code Conversion File (PCCF) for the conversion. Statistics Canada does not directly distribute this product. It works with its Data Liberation Initiative (DLI) partners to deliver this product.
On the diagram there are also other path to run down the hierarchy. For example, from Canada down to federal electoral district (aka ridings). However, the census is not carried out by either election ridings or postal code. Instead, it is carried out by its own collection of levels dedicated for census purpose. When using census data, we need to be familiar with these units.
Census metropolitan area (CMA) and census agglomeration (CA): formed by one or more adjacent municipalities centred on a population centre (known as the core), such as Chatham-Kent CA, Kitchener-Cambridge-Waterloo CMA. Note that CMA and CA can expand across provincial borders, such as Ottawa – Gatineau CMA. So CMA or CA is not a unit under province or territory.
Census Division (CD, essentially a region or county): general term for provincially legislated areas (such as county, municipalité régionale de comté and regional district) or their equivalents.
Census Subdivision (CSD, essentially a city): the general term for municipalities or areas treated as municipal equivalents for statistical purposes.
Census Tract (CT): small, relatively stable geographic areas that usually have a population of less than 10,000 persons, based on data from the previous Census of Population Program.
Dissemination Area (DA): is a small, relatively stable geographic unit composed of one or more adjacent dissemination blocks with an average population of 400 to 700 persons based on data from the previous Census of Population Program. It is the smallest standard geographic area for which all census data are disseminated.
Dissemination Block (DB): an area bounded on all sides by roads and/or boundaries of standard geographic areas. The dissemination block is the smallest geographic area for which population and dwelling counts are disseminated.
With these in mind, we can build two hierarchies closely related to census data:
Now we download census profile data from Statistics Canada. In the dropdown you can pick from the many of the aforementioned geographic levels.
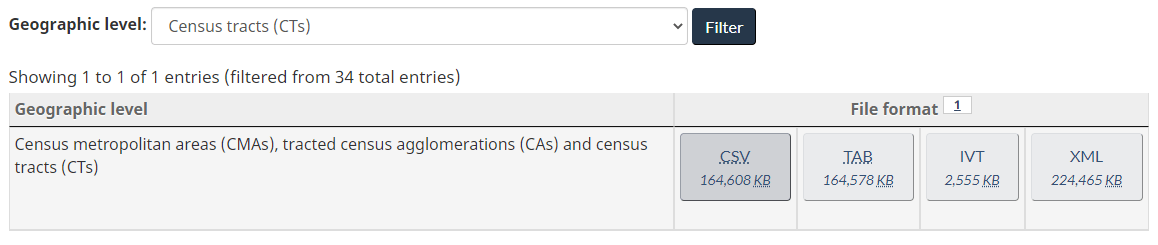
If you pick Census tracts (CT), there is one data file. The CSV file is about 160M. Also note that under geographic level column, it indicates two levels: CA/CMA and CT, which is important to keep in mind as we go through the data. In the content of the CSV, under the GEO_LEVEL column, value 1 stands for CA/CMA and value 2 stands for CT. Therefore, when GEO_LEVEL=1, the GEO_CODE value is a CA/CMA code based on Statistical Area Classification; when GEO_LEVEL=2, the GEO_CODE value is a CT numerical name (preceded by CMA/CA code). What CT numerical name represents what geographic area, is all defined in Census Tract Reference Map. There is no textual name for each census tract.
To take another example, select Dissemination areas (DAs) from the dropdown. Now the size of the CSV becomes 1.6G, but smaller data files are provided by province and territories. Select the data file for Ontario only.
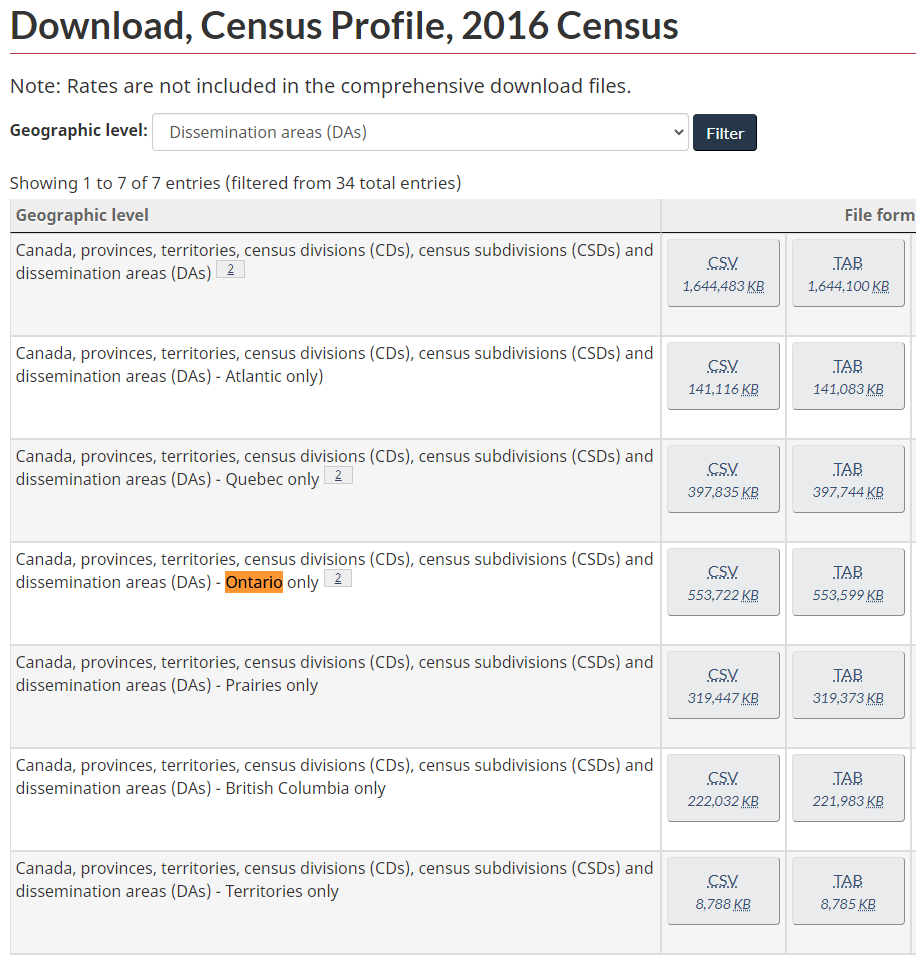
Note that there are five geographic levels as indicated: Canada, provinces/territories, CDs, CSDs and DAs. This suggests we will see 5 different values under the GEO_LEVEL column in the data file:
- 0 – Canada
- 1 – Provinces and Territories
- 2 – CDs
- 3 – CSDs
- 4 – DAs
Read the SGC documentation to understand the code from level Canada to level CSD. DA is similar to CT because the code is defined in reference map here.
Apart from DA and CT, there are other levels (such as ridings) with reference maps, as outlined in the Census geography page.
With all the above information, we can parse the data programmatically. Of course, the schema and coding information applies to Canada. Outside of Canada, pretty much all states have a counterpart government agency that manages census and statistics, just with different formats to understand from ground up. A lot of census geography concepts applies to other countries as well. For example:
- Census Bureau of United States
- Australian Bureau of Statistics
- Office for National Statistics (UK)
- Eurostat (European Union)
Welcome to the world of data.