
This is a summary of concepts in common Git operations. We will discuss brach, merge, rebase, cherrypick, stash and reset. Then we’ll discuss pull, fetch, and push.
Commit, Branch and HEAD
When you run “git commit”, the following happens:
- Git checksums each subdirectory, and stores them as a tree object (file path and name) and blob object (file content) in Git repository;
- Git creates a commit object that has the metadata and a pointer to the root project tree; or if this is not the first commit, the pointer will point to the commit immediately before it
The operations above should form a chain of commit. It can be a long chain and may diverge into branches. In Git semantics however, a branch is simply a lightweight, movable pointer to one of the commits. The default branch name in Git is master. A Git repository may contain multiple branches and the name master itself does not suggest any privilege. There is also a special pointer called HEAD, which indicates the branch you are currently working on. So branch is essentially a pointer to a commit; HEAD is essentially a pointer to a branch. “git checkout” can switch branch that HEAD points to.
Basic Merge
One type of basic merge simply moves branch pointer from one commit to another (along the same chain) without creating any commit. Here is a diagram before basic merge:
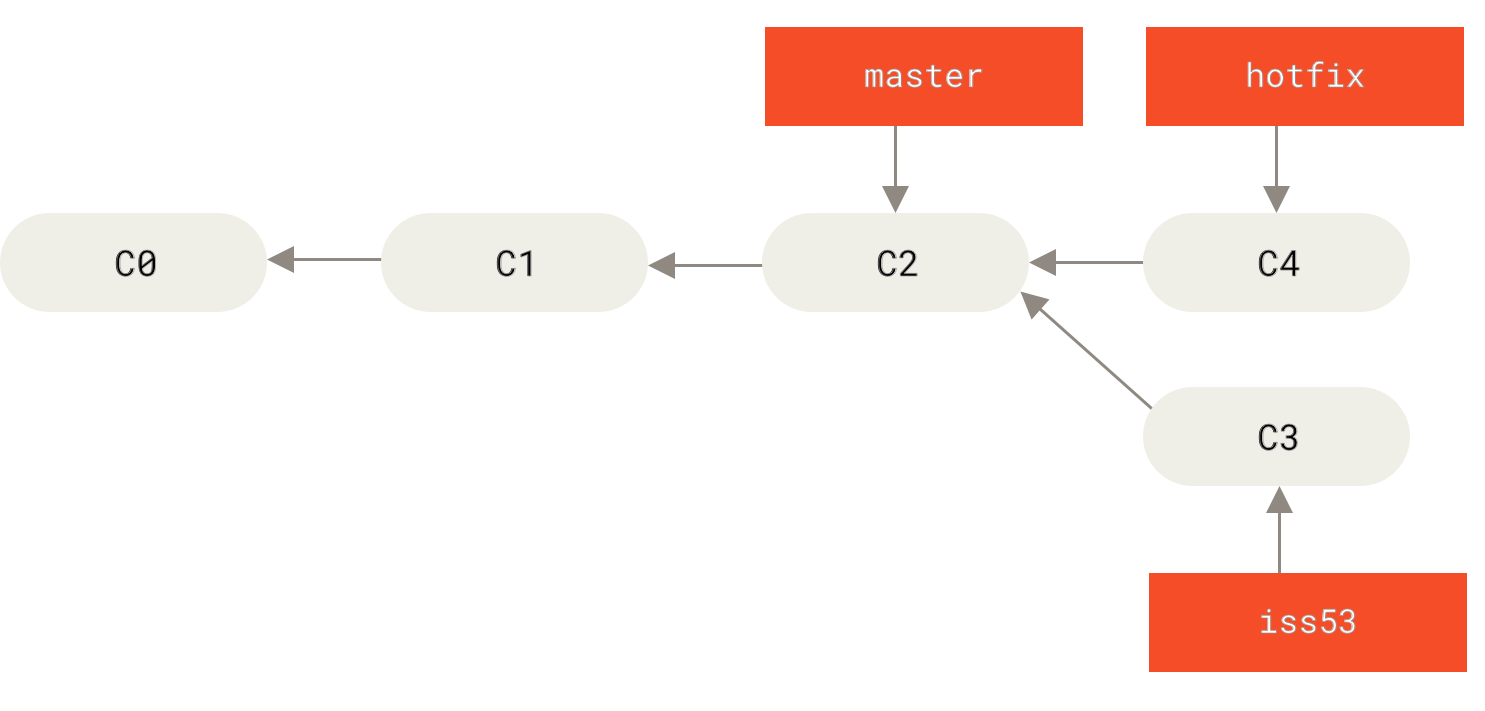
masterThe following command performs basic merge:
$ git checkout master
$ git merge hotfix
Updating f42c576..3a0874c
Fast-forward
index.html | 2 ++
1 file changed, 2 insertions(+)
Then Git simply moves the pointer (named master) forward. There is no divergent work to move together, hence no chance of merge conflict. This type of basic merge is also called “fast-forward” merge.
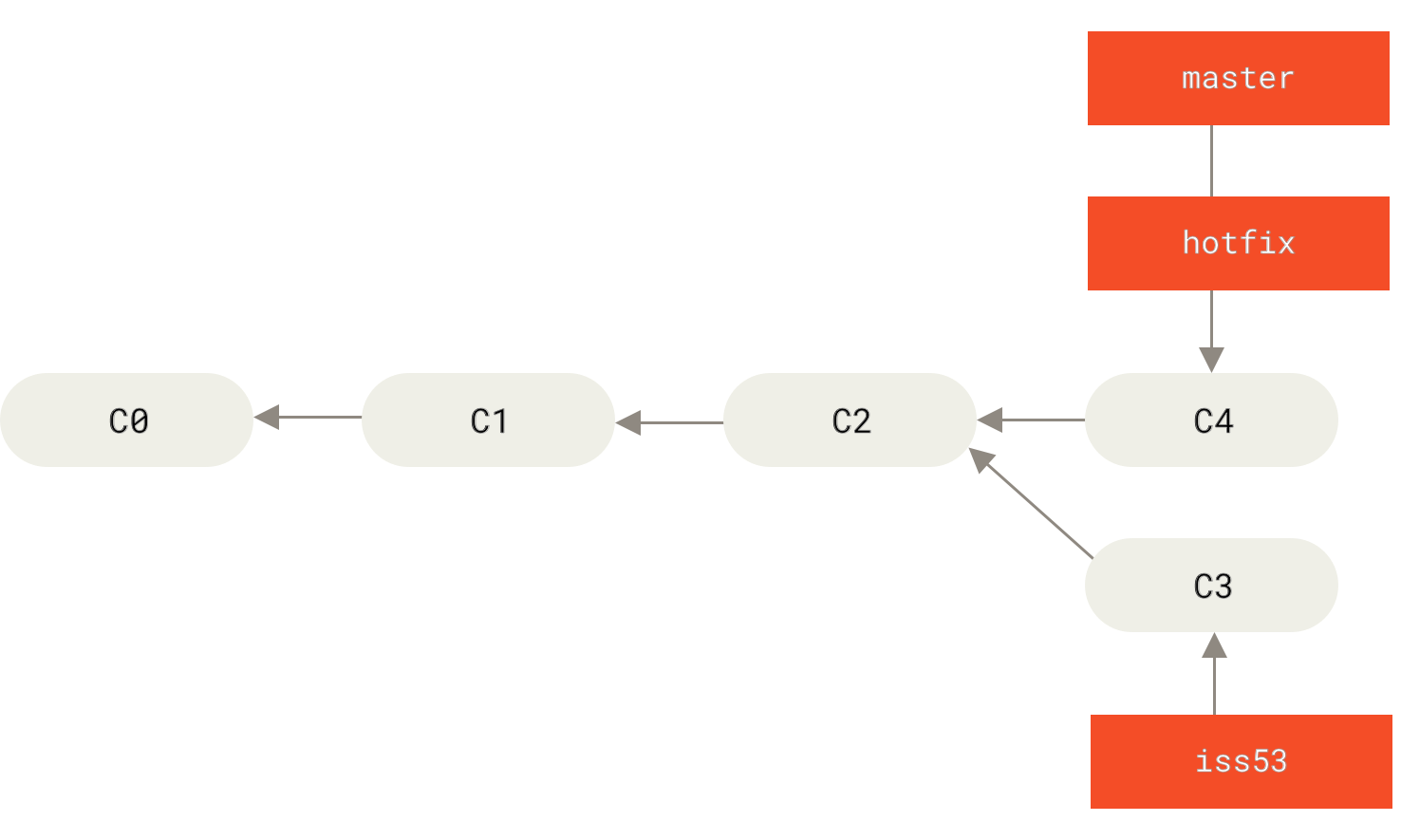
master is fast-forwarded to hotfixThe other type of merge involves reconciling divergent work together, which may or may not involve conflict. Suppose this is the commit tree to start with:
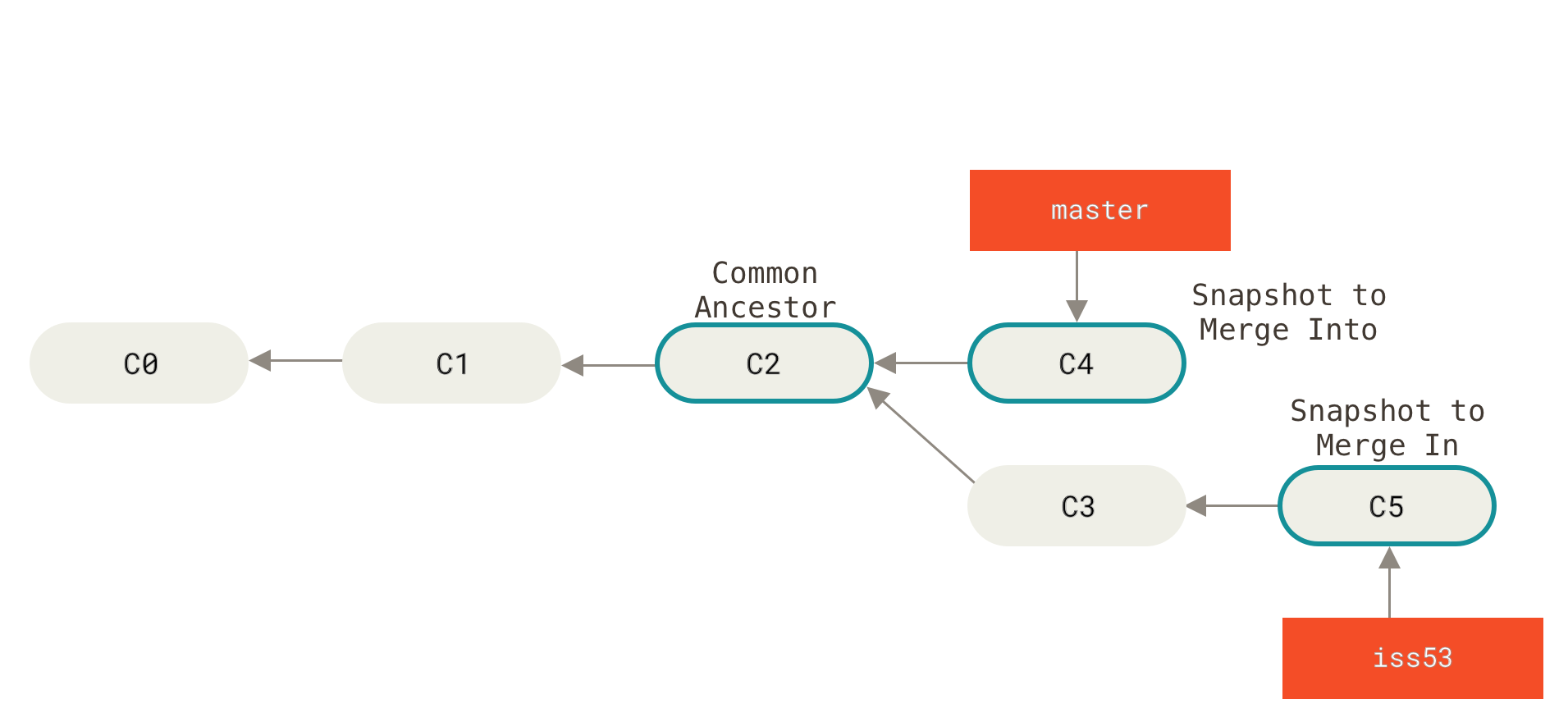
The following commands perform the merge:
$ git checkout master
Switched to branch 'master'
$ git merge iss53
Merge made by the 'recursive' strategy.
index.html | 1 +
1 file changed, 1 insertion(+)
Instead of just moving the branch pointer forward, Git creates a new snapshot that results from this three-way merge and automatically creates a new commit that points to it. This is referred to as a merge commit, and is special in that it has more than one parent.
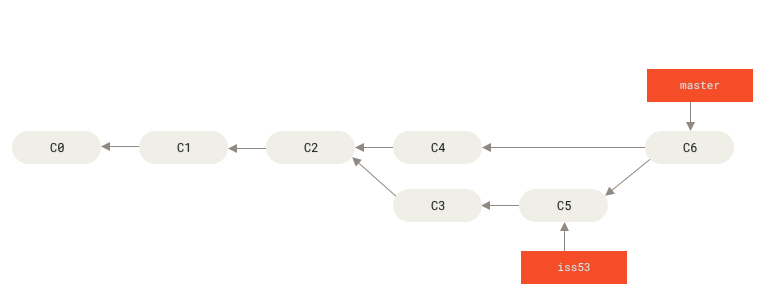
Now that your work is merged in, you have no further need for the iss53 branch. You can close the issue in your issue-tracking system, and delete the branch:
$ git branch -d iss53
If commits from two respective branches changes the same file in different ways, then there is a merge conflict. In this case, Git cannot just create a merge commit. Instead it asks the user to resolve the conflict first. You have to choose either side of the change, or just merge the content yourself. At this point, if you introduce a change that does not appear in any parent, it is referred to as an evil merge.
Beyond the basic merge, there are more sophisticated merge conflict resolution tools covered in advanced merging.
Merge and Rebase
There are two ways to integrate changes from one branch to another. Merge and rebase. Suppose your commit chain diverge into a master branch and a feature branch. Merging (from feature to master) takes the content of feature branch and integrate it with master branch.
$ git checkout master
$ git merge featureWhen you rebase a feature branch onto master, you move the base of the feature branch to master branch’s ending point.
$ git checkout feature
$ git rebase masterAfter merge, you are still on the same branch. The commits from other branch are integrated into the branch that you are already on. There is no change in any existing commits (history). After rebase, your base will be moved to a different branch, along with the commits that you have made in the previous branch (since the diverge). In other words, by re-playing those commits on a different branch, it changed history.
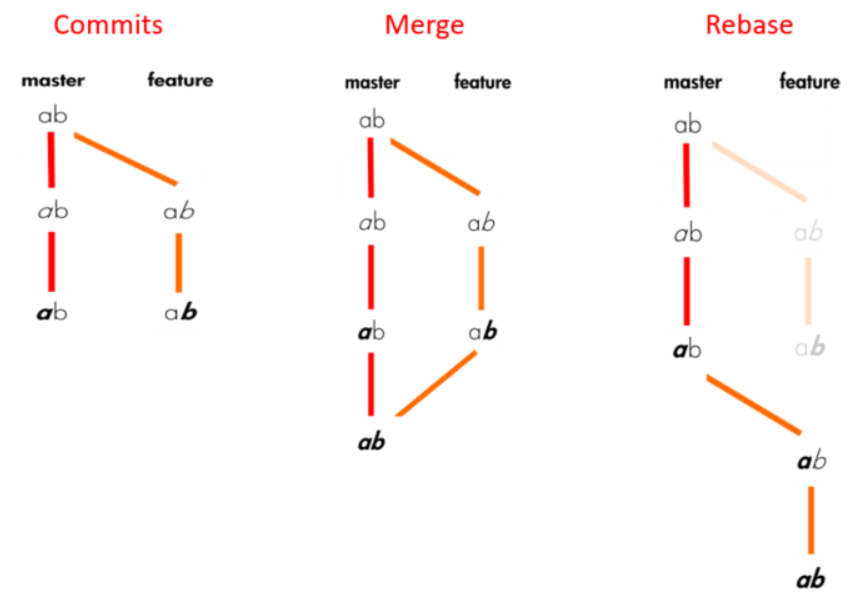
The chart above is stolen from this article, which does a better job explain in detail the difference, pros and cons of merge and rebase. Merge does create a “merge commit”, and a git history full of merges can be cluttered. Rebase does not create an extra commit but since it changes the history of a branch, it has impact to other collaborators. It can be done in an interactive way (with -i switch). The golden rules of rebasing is covered in this article. One of the principles is that never perform a rebase on a public branch.
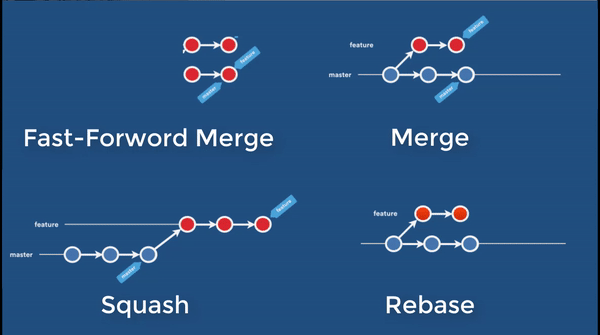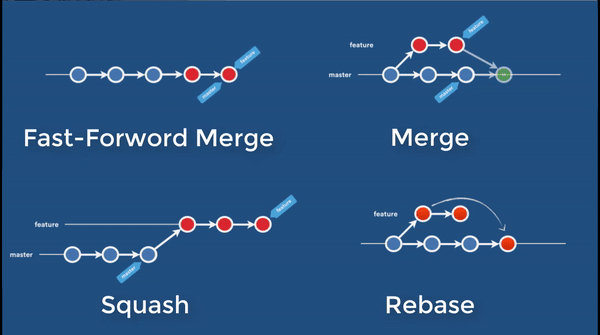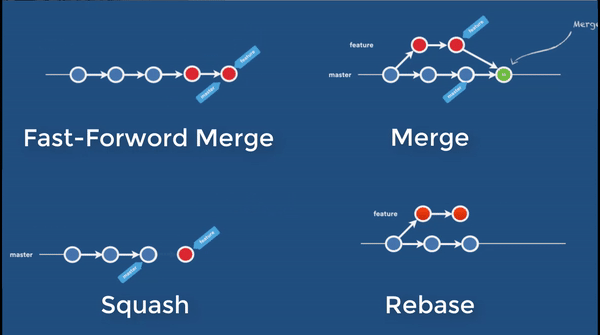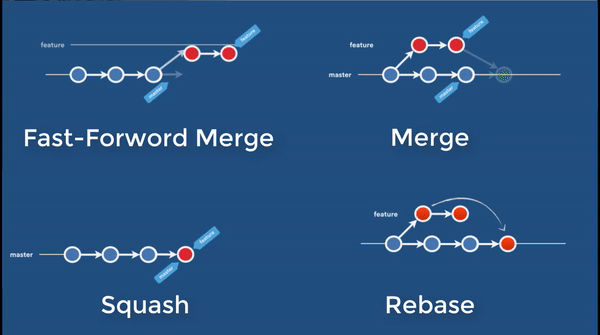
Cherrypick
In a cherrypick operation, the current branch does not change. You simply pick interested commits from other branches to re-apply to your current branch. You may pick a single or a series of commits from other branch. These commits are not “moved” to your current branch. They remain intact. They are just re-played as new commit to current branch. Unlike rebase, there is no re-writing of history, hence not as dangerous.
Reset and Stash
Suppose you are working on a part of a project and it starts getting messy. There has been an urgent bug that needs your immediate attention. It is time to save your changes and switch branches. If you are okay to give up your uncommitted work, you may perform a reset, in one of the three modes covered in a previous article.
But most likely, you don’t want to do a commit of half-done work. The solution is git stash. Stashing is handy if you need to quickly switch context and work on something else but you’re mid-way through a code change and aren’t quite ready to commit. In the most basic workflow, you need to run this command to save your uncommitted (but staged) work. As soon as you stash your change, the working directory is clean with all uncommitted local changes saved elsewhere. You can perform any other Git operations, such as change branch. When you’re ready to resume, you may pop the stash. Here is an example:
$ git add .
$ git stash
$ git checkout correctbranch
$ git stash pop
Instead of pop, you can also use apply to keep the changes in working directory.
$ git stash applyMore details are on this page from Bitbutket.
Fetch and Pull
A git fetch simply downloads blob data from remote so the .git directory comes in sync with the server. It does not attempt to update the local working directory. If there is staged or uncommitted local changes, fetch will not impact them. A git pull is essentially git fetch followed by git merge. In addition to downloading blob data, it also updates local working directory. Therefore, there is a chance of merge conflict when the same file has been modified locally. Git will usually guide you through the merge conflict by flagging the conflict area in the file and let you decide the survival changes. For example:
#! /usr/bin/env ruby
def hello
<<<<<<< HEAD
puts 'hola world'
=======
puts 'hello mundo'
>>>>>>> mundo
end
hello()
You will be prompted in an editor session to reconcile the conflict. Once the file is saved, you will also need to do a “merge commit”, before you can pull again.
Push
Git push is the opposite of pull, where you merge local branch to the remote. (There is no opposite of fetch because there is no point to merge to remote without updating working directory, no collaborator works on the working directory on the server after all). If the local branch has fallen out of sync with the remote, there is a chance of merge error during git push. To minimize the chance of a merge during push, we can run a git pull before and reconcile any potential conflict locally. This is known as a pre-merge.
Visualizer
I came across a great visualizer of commit chain here. In the command panel type some git command and it will print the commit graph for you