
Zookeeper
General definition of distributed system: a software system that is composed of independent computing entities linked together by a computer network whose components communicate and coordinate with each other to achieve a common computational goal. Implementing coordination among components of a distributed system is hard. For example, designated master node becomes single point of failure; cluster needs to detect availability of new nodes as it joins cluster.
Zookeeper is designed to simplify cluster coordination. Zookeeper implements key aspects in cluster coordination, such as distributed consensus, group management, presence protocols and leader election. In order to coordinate a cluster, zookeeper itself also runs in its own cluster, called ensemble. Zookeeper exposes a simple but powerful interface of primitives. Applications can be designed on these primitives implemented through ZooKeeper APIs to solve the problems of distributed synchronization, cluster configuration management, group membership, etc.
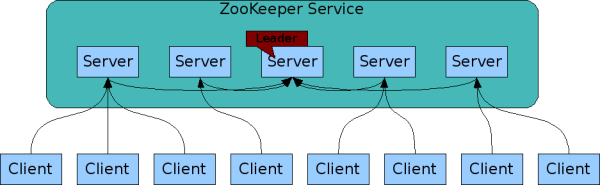
Clients can connect to a Zookeeper service by connecting to any member of the ensemble. The members of the ensemble are aware of each other’s state. As long as a majority of the nodes are available, the service will be available. Zookeeper cli (zkCli.sh) can be used to connect to Zookeeper server. they can be downloaded from here.
Zookeeper is integrated with many other services apart from Kafka, such as Nifi and Hadoop.
Kafka
Kafka is a messaging system that is horizontally scalable, fault tolerant. It can also serve as queue storage system and stream processing system. It is distributed and use Zookeeper for cluster coordination. Each node is called a broker.
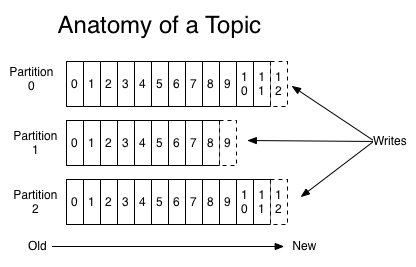
Topics in Kafka (think of table in database) is a category or feed name to which messages (records) are published. Topic is broken up into ordered commit logs called partitions. Each partition has an ID. Each message in a partition is assigned an offset. Topics that are created in Kafka are distributed across brokers based on the partition, replication, and other factors. Each partition is replicated across several brokers depending on replication factor. For each partition, Kafka elect one replica as the leader of partition.
Writes to a partition is generally sequential. Reading messages can either be from the beginning, or rewind or skip to any port in partition given an offset value. Data in a topic is retained for a configurable period of time.
A message is a unit of data in Kafka, in the format of key-value pair. A key is used to control the message that is to be written to partitions. Messages with the same keys are always written to the same partition (hash map)
A producer publishes new message to a topic. Producers do not care which partition the message is written to and will balance messages over every partition of a topic evenly. Directing messages to a partition is done using the message key and a partitioner, this will generate a hash of the key and map it to a partition.
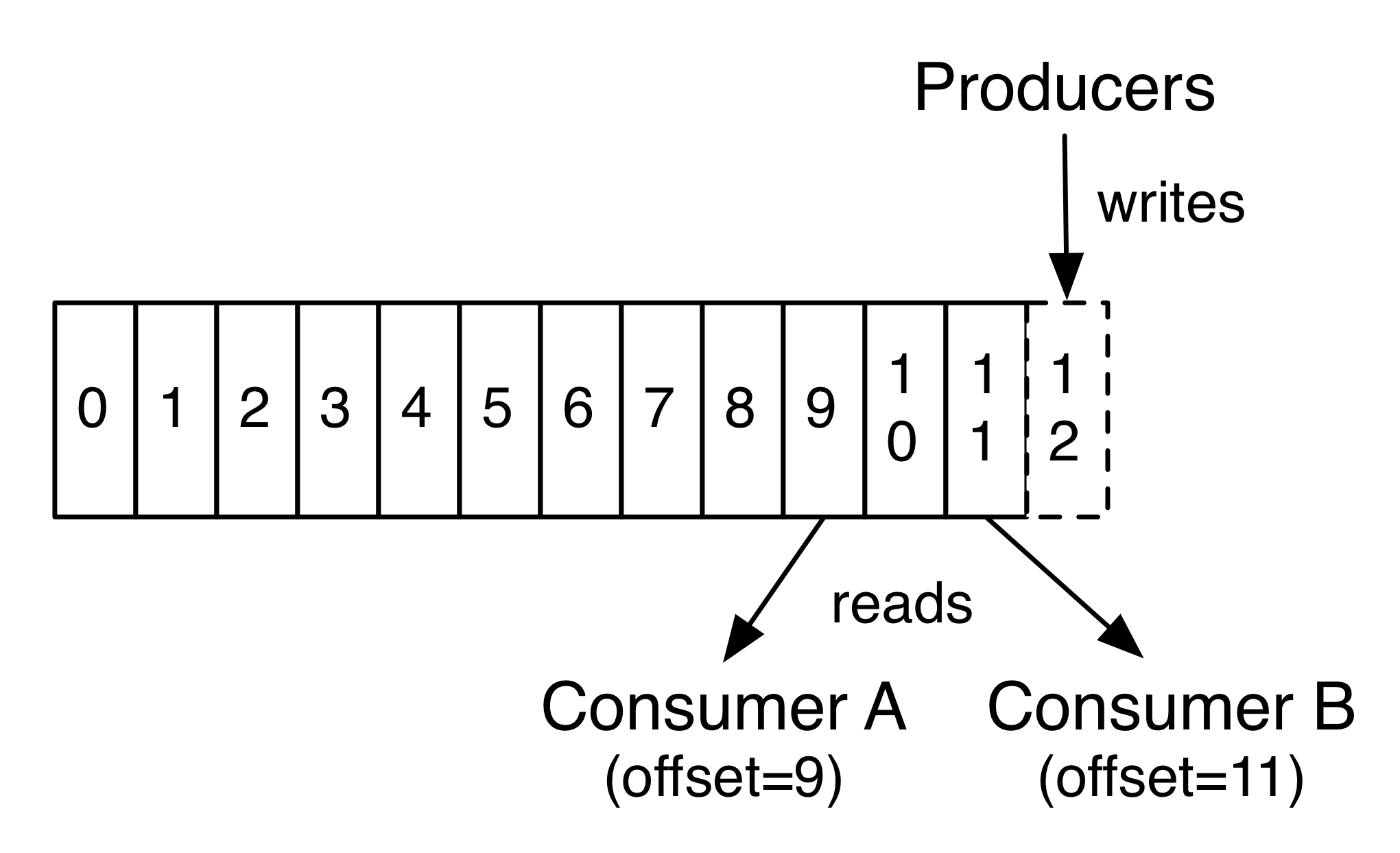
A consumer is subscribed to one or more topics and read messages sequentially. The consumer keeps track of messages it has consumed by keeping track on the offset of the message. The offset is a bit of metadata (an integer value that continually increases) that kafka adds to each message. Each partition has a unique offset which is stored with the offset of the last consumed message. A consumer can stop and start without losing its current state.
A Kafka broker is designed to operate as part of a cluster. One broker in the cluster also function as the cluster’s controller, which is responsible for administrative operations such as: assigning partitions to brokers; monitoring for broker failures in cluster. A particular partition is owned by a broker and that broker is called the leader of the partition.
All consumers and producers operating on that partition must connect to the leader.
Kafka cluster may replicate across cluster using MirrorMaker.
Reference: Kafka: The Definitive Guide: Real-Time Data and Stream Processing at Scale
