

Update 2022-08 – Read my latest article on ingress traffic management.
In this post we discuss the traffic management in Kubernetes, specifically on Service and Ingress objects. Let’s start with a traditional architecture:
In this traditional architecture, we run application as processes on the operating system on each virtual machine. The application process is bound to a certain ports on the operating system, and is wrapped into services (e.g. systemd). On the same virtual machine, there is also a reverse proxy service (e.g. Nginx). There are several main functional areas as listed below, and how they are fulfilled in traditional architecture:
| Requirement | Detail | Typically fulfilled by |
| L4 Load balancing | TCP/UDP traffic routing, operating at L3 and L4 | Network Load Balancer |
| TLS termination | Terminate TLS traffic, operating at L4 | TLS termination is available in many products such as Load Balancer (L4/L7), Nginx, or the application itself. |
| Path-based routing | Route request based on URI path, operating at L7 | Nginx, modern L7 Load Balancer. |
| Authentication | Integrate with external identity store, operating at L7 | Nginx, modern L7 Load Balancer. |
These requirements are the problems that Kubernetes needs to solve in its own architecture. They are solved by different abstraction objects in Kubernetes. Before getting to traffic management, we first need to expose an application.
Service
During traditional application deployment, we often need to organize a group of homogenous application instances as a single target for batch operation. The Pod object is an abstraction of a single application instance. The Deployment object is an abstraction of a group of homogenous Pods. The purpose of Deployment object is for Pod orchestration only. It is not designed to expose the application. To define how we want to expose an application, we use Service object.
The service object does not carry exactly the same functionalities as an operating system service. It connects to the frontend (client), as well as to the backend (server). There are two ways to connect to a backend:
- To connect to Pods as backend, use selector and label; the target port is Pod’s port. This is the most common use case.
- To connect to a custom backend (e.g. external database, services in different namespaces, during workload migration), define an Endpoints object (including address and port), and target the port;
On the frontend, there are several ways to expose service to client, as defined in ServiceType property. Each represents a level of exposure:
- ClusterIP (default): the service gets an internal IP address in the cluster. This is the lowest level of exposure. The service is only reachable from within the cluster. This is a good choice when the service is for internal assumption, such as database.
- NodePort: the service is exposed at a static port on each node. The port must be in a range pre-specified during cluster provisioning (default 30000-32767). Each node proxies traffic to that port to the service. Without a load balancer, each node is a point of entry on its own.
- LoadBalancer: this option works with external load balancer in cloud deployments. The actual creation of the load balancer happens asynchronously, and information about the provisioned balancer is published in the Service’s
.status.loadBalancerfield. Some cloud providers allow you to specify theloadBalancerIP. The benefit Load Balancer over NodePort, is it provides a single point of entry (for each service). - ExternalName: rare use case with custom endpoint object.
Headless service
With service type ClusterIP, if you explicitly specify "None" for the cluster IP (.spec.clusterIP), the service is considered a headless service. With a headless service, a cluster IP is not allocated, kube-proxy does not handle these services, and there is no load balancing or proxying done by the platform for them. Each connection to the service is forwarded to one randomly selected backing pod. Hence the document points out that you can use a headless Service to interface with other service discovery mechanisms, without being tied to Kubernetes implementation. The behaviour differs slightly based on whether selectors are present, but both resembles DNS routing with multiple A record.
Virtual IP
Kubernetes manages service traffic with virtual IP. When clients connect to virtual IP (VIP), the traffic is automatically transported to an appropriate endpoint. Virtual IP is implemented with kube-proxy. Kube-proxy can work in three modes: userspace, iptables and IPVS. I discussed these terms in this post last year. The takeaway is that IPVS is the recommended mode.
Ingress
Ingress in Kubernetes cannot match up with a counterpart in traditional architecture. It is mainly for path-based request routing. Also, do not confuse Ingress object with Ingress rule as a policy type in Network Policy object. Ingress is a high level abstraction and should be considered over Service object when the followings are involved in the routing.
- Content-based or path-based L7 routing
- Multiple protocols (e.g. gRPC, WebSockets)
- Authentication
Ingress usually work with service object (ClusterIP), as illustrated in Kubernetes documentation:
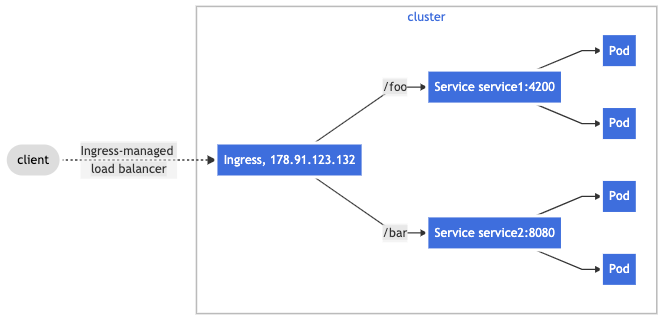
Also note that if you have a service other than HTTP or HTTPS, that you need to expose to the Internet, it is recommended to use a service object of NodePort or LoadBalancer type.
We call Ingress a high-level abstraction. Ingress object (aka ingress resource) itself does not expose application. It simply defines a set of routing rules. The implementation is provided by another object (Ingress Controller), who enforces the routing rules by monitoring and manage traffic using its own Service and Pods. You must have an Ingress controller to satisfy an Ingress. Only creating an Ingress resource has no effect. There are a number of Ingress Controllers to choose from.
Ingress Resource
In an Ingress resource, annotations are used to configure some options, depending on the corresponding Ingress Controller. What annotation can be used depends on the the specific Ingress Controller. The backend can be either a service, or a resource. A common usage for a Resource backend is to ingress data to an object storage backend with static assets. You can define DefaultBackend for an Ingress.
Each Ingress should specify a class, a reference to an IngressClass resource that contains additional configuration including the name of the controller that should implement the class. Before the IngressClass resource and ingressClassname field were added in Kubernetes 1.8, Ingress classes were specified with a kubernetes.io/ingress.class annotation on the Ingress. This annotation was never formally defined, but was widely supported by Ingress controllers. For example, here is the annotations supported by Nginx Controllers.
Below is the yaml output of the ingress from Kubernetes documentation:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
pathType: Prefix
backend:
service:
name: test
port:
number: 80
Ingress Controller
Ingress Controller exists in the form of Pods, usually as daemonSet, sometimes as a deployment. The Pods listens for requests to create or modify Ingress within the cluster, and converts the rules in the manifest into configuration directives for a load balancing components. Below is all the components related to Ingress Controller:
> kubectl -n ingress-nginx get all
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-admission-create-s7486 0/1 Completed 0 11d
pod/ingress-nginx-admission-patch-sjt2q 0/1 Completed 2 11d
pod/ingress-nginx-controller-5b74bc9868-6vmjc 1/1 Running 18 11d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller LoadBalancer 10.106.25.194 localhost 80:31774/TCP,443:31576/TCP 11d
service/ingress-nginx-controller-admission ClusterIP 10.102.38.191 <none> 443/TCP 11d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-nginx-controller 1/1 1 1 11d
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-nginx-controller-5b74bc9868 1 1 1 11d
NAME COMPLETIONS DURATION AGE
job.batch/ingress-nginx-admission-create 1/1 9s 11d
job.batch/ingress-nginx-admission-patch 1/1 25s 11d
Ingress Controller can be implemented by load balancer resource from cloud platform, or Nginx. When you have one ingress resource and one controller, the matching is assumed. When you have multiple controllers, you need to use the mechanism from the ingress controller to ensure correct matching.
Nginx is a popular controller and there are a couple of implementations as illustrated here. Let’s take a look at Nginx Controller as an example. The troubleshooting guide states that, For each Ingress/VirtualServer resource, the Ingress Controller generates a corresponding NGINX configuration file in the /etc/nginx/conf.d folder. Additionally, the Ingress Controller generates the main configuration file /etc/nginx/nginx.conf, which includes all the configurations files from /etc/nginx/conf.d. In the Rancher ingress example above, we can check the nginx configuration with the commands below:
kubectl exec ingress-nginx-controller-5b74bc9868-6vmjc -n ingress-nginx -- cat /etc/nginx/nginx.conf | less
It is important to understand the difference between a load-balancer type service and an ingress. The documentation for ingress states that: An Ingress does not expose arbitrary ports or protocols. Exposing services other than HTTP and HTTPS to the internet typically uses a service of type Service.Type=NodePort or Service.Type=LoadBalancer. This is because ingress operates at layer 7, so routes connections based on http host header or url path. Load balanced services operate at layer 4 so can load balance arbitrary tcp/udp/sctp services. Ingress should be backed by L7 load balancer, whereas load-balancer service should be backed by L4 load balancer.
Nginx Ingress Controller
There are several flavours of Nginx ingress controllers that cause much confusion. It is clarified on a blog post on Nginx website. To recap:
- Community version: Found in the kubernetes/ingress-nginx repo, the community Ingress controller is based on Nginx Open Source, with docs on Kuberentes.io. It is maintained by the Kubernetes community with assistance from the F5 Nginx team.
- Nginx version: Found in the nginxinc/kubernetes-ingress repo, the NGINX Ingress Controller is developed and maintained directly by F5 NGINX team, with docs on docs.nginx.com. It is available in two editions:
- NGINX Open Source-based
- NGINX Plus-based
There are also a number of other Ingress controller based on NGINX, such as Kong, but their names are easily distinguished. If you’re not sure which version you’re using, check the container image, then compare the image name with the repos listed above.
Load Balancer
Kubernetes by itself does not have an object for Load Balancer. The function of traditional Load Balancer is implemented through Service and Ingress objects in Kubernetes, both of which can be satisfied by a load balancer object from the cloud platform (service-managed load balancer and ingress-managed load balancer). Alternatively, you may stand up a standalone load balancer independent of the Kubernetes cluster, which is not recommended.
If your architecture is complex and you have a lot of services (e.g. using microservice), then the overhead of managing everything with Service and Ingress in Kubernetes can be significant. In that case, consider delegating these tasks to a service mesh.
Troubleshooting
There isn’t a single recipe for troubleshooting service and ingress on Kubernetes. There are some good general guide lines here and here, in addition to the guides (here and here) from official documentation. To run networking command from within the Pod network, you can launch a Pod using nicolaka netshoot image.
Bottom line
We compared service and ingress in Kubernetes. In real life, we use both, and oftentimes along with CRDs of service mesh.