

There are numerous options to build a Kubernetes cluster. If your company has a multi-cloud strategy, most likely you will have to deal with cluster creation on multiple cloud platform or on virtual machines on premise.
Most likely, the chosen cloud platform already make it simple for us. However, it is still important to understand what it really takes to build a Kubernetes cluster. In general, we need to figure out these tasks:
- Decide where to host the computing infrastructure (i.e. Node) : on premise or public cloud;
- Choose a Kubernetes release: either the vanilla release or one of the third-party distributions;
- Install Kubernetes to the computing environment, and integrate it with the cloud platform;
- Determine required add-ons (e.g. Istio or Linkerd for Service Mesh, dashboard utility, etc);
- Deploy application workload to Kubernetes platform;
A public cloud platform provider usually can assist you with task 1 through 3, and partially 4, depending on the provider. If your Kubernetes resides on private cloud or on-prem environment, you can use a Platform solution such as VMware Tanzu or Openshift, which usually covers task 1, 3 and 4. There is no standard about what task these platform solution must address. Therefore it is important to have this list of tasks in mind in order to make a good comparison. I will discuss each of the tasks in this post.
Hosting environment
Nodes are the building blocks of a Kubernetes cluster. We need master nodes as well as worker nodes. In addition, a working cluster also requires storage, and networking infrastructure.
Public cloud platforms typically provides control plane as a service, obviating administrator’s effort to provision master nodes. For example, the control plane of Azure AKS has two levels of uptime commitment: a free tier of 99.5% SLO and a paid tier with an SLA of 99.95% (using AZs) and 99.9% (without using AZs). This uptime commitment applies to control plane only and do not apply to worker nodes. The management of etcd store is also a responsibility of the cloud provider, which frees up the cluster administrator from managing etcd store. However, they cannot access etcd store either. This is not very convenient because as the size of the cluster grows it is a common requirement to connect to etcd store for troubleshooting purpose.
The deployment APIs for public cloud allow the cluster administrator to define the instance size, count and availability zone for the worker nodes. They also automatically register the worker nodes to control plane so that the cluster administrators do not have to do so by themselves. As to storage, the public cloud usually provide some default storage classes based on their storage as service. For networking device, the cluster provision process automatically configures the cloud API so the cluster can manage cloud resources such as network load balancer.
With private cloud or data centre, we usually use virtual machines, or bare-metal servers. Cluster administrators will need to make their own control plane with master nodes. and install worker nodes and register them to the master nodes. The Kubernetes Installation section below will discuss this.
Kubernetes release
If you have to install Kubernetes, you have to think about the Kubernetes release being used. You can use the binary from official Github repository. For example, the release note of version 1.24.3 points to the change log file for download links to server binaries, node binaries. This is the vanilla Kubernetes release.
Apart from the vanilla release, many developers build their own distributions, based off forks of the Kubernetes project. CNCF has a page to keep track of certified Kubernetes distributions. Some of the distributions are open source and can be used for on-prem infrastructure. Here is a list of top players:
| Distribution Name | Repo | Description |
|---|---|---|
| EKS Distro | Link | Used in EKS managed service or EKS Anywhere for on-prem infrastructure |
| AKS Engine | Link | Used in Azure Stack for on-prem infrastructure. |
| Google Kubernetes Engine | N/A | Used in GKE managed service only. |
| OpenShift Kubernetes Engine | Link | Community distribution (OKD, or OpenShift Kubernetes Distribution) is the open-source upstream. |
| Rancher Kubernetes Engine (RKE) | Link | still using Docker as container runtime. Supported CNI include: Canal, Flannel, Calico and Weave |
| K3s | Link | Lightweight distro without small resource requirement. Great for Edge, IoT, ARM etc |
| RKE2 | Link | Originally named RKE government. Supports deployment via Cluster API. Supports containerd as container runtime. Supported CNI include: Cillium, Calico, Canal and Multus. Lightweight |
| VMware Tanzu | Link | VMWare Tanzu Grid and VMWare Tanzu Community |
Above is just a very incomplete list of Kubernetes distributions. There are many more distributions that are not on this list, such as CoreOS Tectonic, Docker Kubernetes, Heptio, Mesosphere, Mirantis, Platform9, Stackube, Telekube. For full details of how each distribution is different, you will need to go over their documents.
With the selected distribution, we still need to deploy the binaries to the nodes. We can do this with a cluster management platform, or standalone installers. Cluster management platform can also help us with baseline configuration (e.g. IAM integration, CNI plugin), in addition to the binary installation.
Cluster Management Platform
These platforms are also sometimes referred to as container management platform.
For example, OpenShift container platform is a self-managed platform based on OpenShift Kubernetes Engine and can run on a variety of hosting environment, public cloud, or private cloud. The installation steps varies depending on the hosting environment. When running on public cloud such as AWS (aka ROSA), the public cloud only provides computing nodes and associated infrastructure. Many corporate with multi-cluster strategy use this option on public cloud to keep their Kubernetes cluster fleet consistent across cloud vendors.
The Openshift container platform also packages some useful open-source add-ons with corporate support, for example:
- OpenShift Service Mesh: Istio
- Ceph Storage
- Gluster Storage
- OpenShift GitOps (ArgoCD)
- OpenShift Pipelines (Tekton)
- Quay (Quay Image Registry)
- OpenShift Streams for Apache Kafka
- OpenShift Serverless (Knative Serving)
Red Hat’s strategy is to pick the most renowned open-source project in each domain and add enterprise support to it. However, for management portal, Red Hat developed its own Advanced Cluster Management tool for Kubernetes, and open-sourced it in 2020 in the upstream project Open Cluster Management.
Similar to OpenShift, VMware Tanzu also attempts to cover the domains, with a smaller product portfolio:
- Service Mesh: compatible with Istio
- Mission Control: management portal
- Observability
Google Anthos is also a container platform. Their product line include, but not limited to:
- Anthos Config Management (ACM)
- Anthos Service Mesh (ASM, an Istio distribution)
SUSE, the developer of RKE, RKE2, and K3s) offers Rancher as multi-cluster management platform. Apart from the engines, SUSE also offers Lonhorn as a storage solution. However, they do not have offerings for service mesh or GitOps. So there is no doubt that Red Hat OpenShift has the most complete portfolio for Kubernetes.
There are also companies that only offers management platforms without their own Kubernetes distribution. For example:
Product capabilities in this category vary a lot and you should refer to their specific documentation to understand. You will probably see a stack chart from each of the platform provider (e.g. SUSE Enterprise Container, OpenShift, Tanzu, Anthos, Rafay) with all technology integrations.
Cluster Installation Tools
As we saw in the installation steps for OpenShift, they are highly dependent on platform. With public cloud, the provisioning process also applies only to a specific platform. Since Kubernetes Installation process is tedious, some tools emerged to help, for example: kubespray, kubeadm, kops and Cluster API. These are governed by SIG cluster lifecycle special interest group.
Here are some traditional options to install a Kubernetes clusters:
- kube-up: the first tool to build cluster from 2015. It has been deprecated.
- Kubeadm: a tool built to provide best-practice “fast paths” for creating Kubernetes clusters that are minimum viable, and secure. Kubeadm’s scope is limited to the local node filesystem and the Kubernetes API, and it is intended to be a composable building block of higher level tools. It is first released in Sep 2016. The high level configuration steps goes through initialization (kubeadm init), control plane (kubeadm join control plane), and node (kubeadm join node). Kubeadm does not integrate with cloud providers and it does not install addons (auth, monitoring, CNI, storage class)
- Kubespray: runs on bare metal or VMs using Ansible for provisioning and orchestration. The first release was in Oct 2015. Since v2.3 (Oct 2017) kubespray started to use kubeadm internally. In addition to kubeadm, kubespray configures CNI, storage class, other CRI. It supports cloud providers and air-gap environment. However it does not support infrastructure management.
The options above are official options. You may use kubeadm and kubespray to quickly (i.e. in an hour) spin up clusters for education purposes. However, with their limitations, it typically requires a lot of efforts to build a production-grade cluster with the needed addons and integrations.
Apart from the official options, there are also unofficial tools such as kubicorn, which was first introduced in 2018 as a cluster management framework with modular support for cloud providers. However it appears to be short-lived.
In the next two sections, we introduce kops and cluster API, two most recent projects to install cluster.
Kops
The kops utility directly perform the provisioning and orchestration via API to the cloud deployment engine. Kops, with first release in Oct 2016, is tightly integrated with the unique features of the cloud providers (e.g. AWS: ASG, ELB, EBS, KMS, S3, IAM). However, kops is only CLI without controller-style reconciliation. It does not support baremetal or vsphere. It also bundles addons with fixed version.
When picking a tool to install cluster, we need to strike a balance between how much simplification the tool brings, and how many different platform the installer can work with. Kops appears to be such a good compromise. It works with a number of cloud platforms using different set of APIs, although most are in alpha and beta stages today. Here is how to install cluster on AWS.
Both kops and Cluster API have good momentum but they work differently. Cluster API was first released in Mar 2019, and is currently less mature than kops. However, it is declarative and may reflect the direction of where cluster lifecycle management is heading.
Cluster API
Cluster API focuses on following areas:
- Manage cluster lifecycle declaratively
- Infrastructure abstraction (e.g. computing, storage, networking, security, etc)
- Utilizing existing tools (e.g. kubeadm, cloud-init)
- Modular and pluggable: to be adaptable to different infrastructure providers.
It involves a number of CRs as illustrated in its diagram. We should be clear on the providers for Bootstrap, Infrastructure and Control Plane.
The biggest benefit is the controller pattern to manage the entire lifecycle of a cluster. This allows managing clusters with GitOps, and rolling upgrade of the cluster. It also allows for declarative node scaling, self healing and multi-cluster management.
The client utility for is clusterctl, and with that along with the manifest, we can create a cluster in a few commands. A lot of workflows are still in development but we can take a look at its quick start guide to get a taste of how it works. The installation steps vary a lot based on the environment and the cluster. Also it introduces the separation of management cluster and workload cluster.
- Workload cluster is the target cluster being created, as per the manifests.
- Management cluster is where you keep track of the workload cluster being managed. You can manage multiple workload clusters from a single management cluster. Note that this management cluster will store credentials about workload clusters, and may become a single point of failure.
Although Cluster API reflects a great initiative to standardize the provisioning of Kubernetes cluster, whether it will succeed has to do with the level of complexity. In the next section, we will get a taste of how it looks to deploy a Kubernetes cluster in a lab.
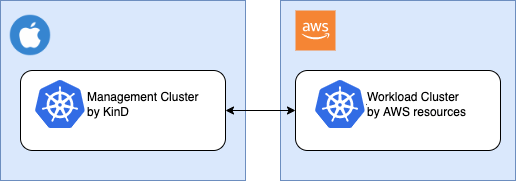
In the lab, I use my MacBook to create a management cluster with KinD. Then we configure a workload cluster in AWS from the management cluster.
Cluster API Lab
Note that the steps here are based on the quick start guide on Cluster API document. Also, there is a bug with the AWS provider so the end of the lab will report a warning. The main purpose of this lab is to demonstrate how Cluster API is supposed to work, even though it still has yet to mature.
To start, I install clusterctl (the cluster API client utility), clusterawsadm (the utility specific for AWS) on MacBook, then start a simple KinD cluster.
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.2.0/clusterctl-darwin-amd64 -o clusterctl
chmod +x ./clusterctl
sudo mv ./clusterctl /usr/local/bin/clusterctl
clusterctl version
curl -L https://github.com/kubernetes-sigs/cluster-api-provider-aws/releases/download/v1.4.1/clusterawsadm-darwin-amd64 -o clusterawsadm
chmod +x clusterawsadm
sudo mv clusterawsadm /usr/local/bin
clusterawsadm version
kind create cluster
So far, I installed the required utility and a KinD cluster on MacBook. Then I use clusterawsadm to create InstanceProfile, ManagedPolicy and IAM Roles required for cluster creation. The AWS region and access are configured as environment variables:
export AWS_REGION=us-east-1
export AWS_ACCESS_KEY_ID=AKIAXXXXXXXXXXX
export AWS_SECRET_ACCESS_KEY=J8ByduiofpwuisDjDoijOISDs
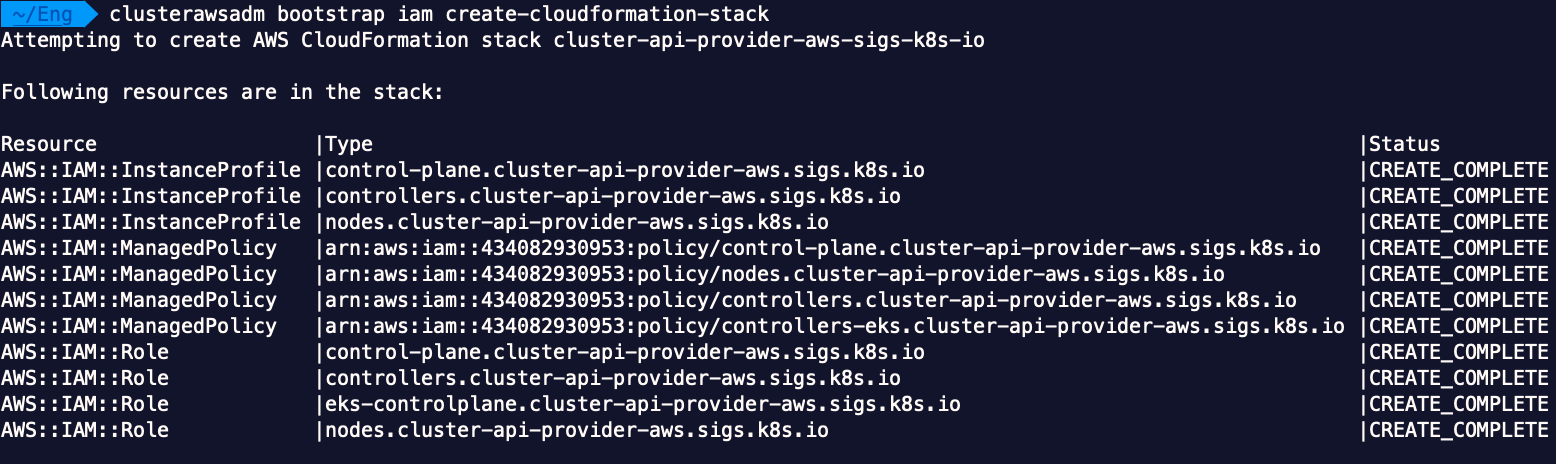
clusterawsadm bootstrap iam create-cloudformation-stack
This runs a CloudFormation stack to create the permission related resources:
Then I initialize the management cluster with the clusterctl utility, specifying AWS as a provider. I also need to assign the environment variable AWS_B64ENCODED_CREDENTIALS with proper value:
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
clusterctl init --infrastructure aws
Now I use clusterctl to generate the manifest for the workload cluster. In environment variables, I specify cluster and node sizes, SSH key name, control plane machine type and node machine type:
export AWS_SSH_KEY_NAME=cskey
export AWS_CONTROL_PLANE_MACHINE_TYPE=t3.large
export AWS_NODE_MACHINE_TYPE=t3.large
clusterctl generate cluster myekscluster --kubernetes-version 1.24.3 --control-plane-machine-count=3 --worker-machine-count=3 > capi-quickstart.yaml
kubectl apply -f capi-quickstart.yaml
At the end I tell the management cluster to create a workload cluster as per the manifest, by simply declaring the CRs. It will take some time for the cluster to create, and there are a number of ways to monitor the progress. You can monitor the log on the controller pods in their respect namespaces. You can also check the cluster status with:
kubectl get kubeadmcontrolplane
clusterctl describe cluster myekscluster
Currently there is a bug and the commands at the end will report as below:

Hopefully the bug will be fixed shortly. To delete the cluster, simply delete the resources in the manifest with kubectl delete -f capi-quickstart.yaml
Summary
There are numerous ways to build a Kubernetes cluster. Before deciding on the approach, I recommend having a full understanding of the hosting environment. This is because installation approach and hosting environment are still tightly coupled. This is the status quo and is not going to change in the near future. Both kops and cluster API reflects initiative to decouple the two but both are still in early stage and already facing growing complexity. Cluster API manages complexity with CRDs to abstract system resources and infrastructure, as illustrated here:
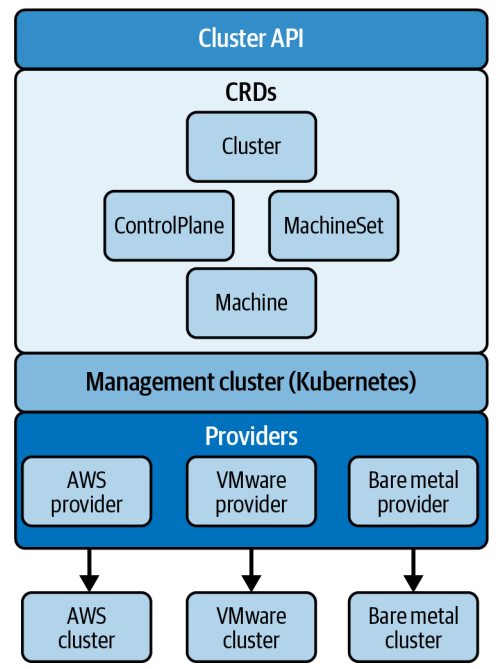
The diagram is from the “Cluster API and declarative Kubernetes Management” white paper. Here is a stream with more about the same topic.