

Etcd in Kubernetes
In Kubernetes architecture, etcd is the data store. It stores the desired state of Kubernetes object. API server is the only client that connects to etcd (via gRPC protocol). Cluster builder specifies the endpoint of etcd as a parameter to the kube-api-server process. Other Kubernetes components, whether in the control plane or from the nodes, connect to API server. API server translates their request into etcd query, and then translates etcd query result into what its clients ask for. For this reason, communication with etcd accounts for a lot of network traffic in a Kubernetes cluster.
The etcd store is a CNCF project for “a distributed, reliable key-value store for critical data in a distributed system”, developed by CoreOS team. So it is essentially a distributed key-value store for any distributed application. If an application runs on Kubernetes, it can leverage etcd store, by keeping their configurations in ConfigMap and Secret objects. One key feature is to watch for specific keys or directories for changes, and react to the changes. Voila! This is the underlying mechanism for controller!
A Kubernetes cluster may have stacked etcd deployment or connect to an external etcd store.

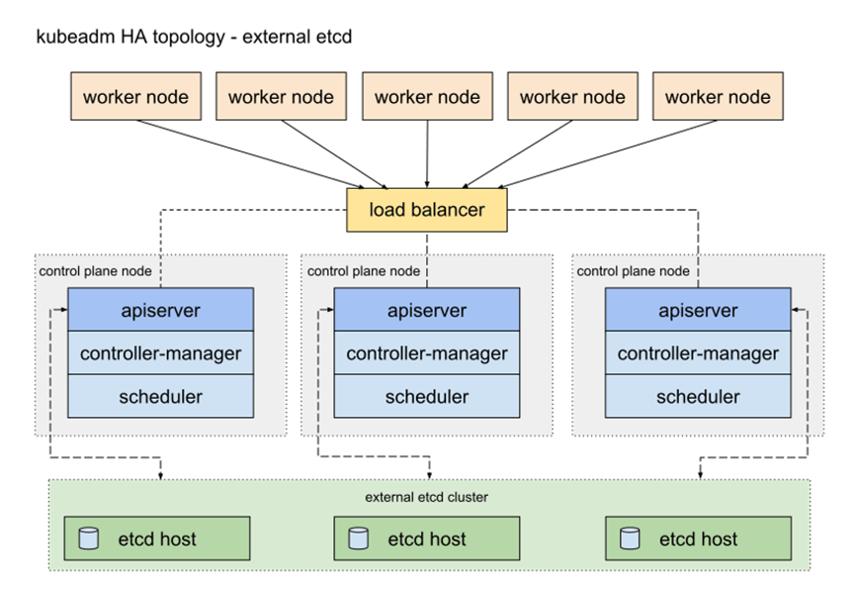
In managed Kubernetes services such as EKS in AWS and AKS in Azure, users usually do not directly access etcd store. However, it is still a very important component to understand. Its use case includes:
- Configuration sharing
- Service discovery
- Consistency
- Watching mechanism
- Expiry and extension of key
The consistency use case is based on Raft protocol for distributed consensus.
Raft protocol
I am not an expert in distributed consensus protocols and nor do I intent to cover it in depth. At a high level, I have heard of three of them so far:
Here is a good intro to the three protocols. Instead of getting into the fine details, I would like to discuss why we need such a consensus protocol (or consensus mechanism) in distributed systems, which are also decentralized systems.
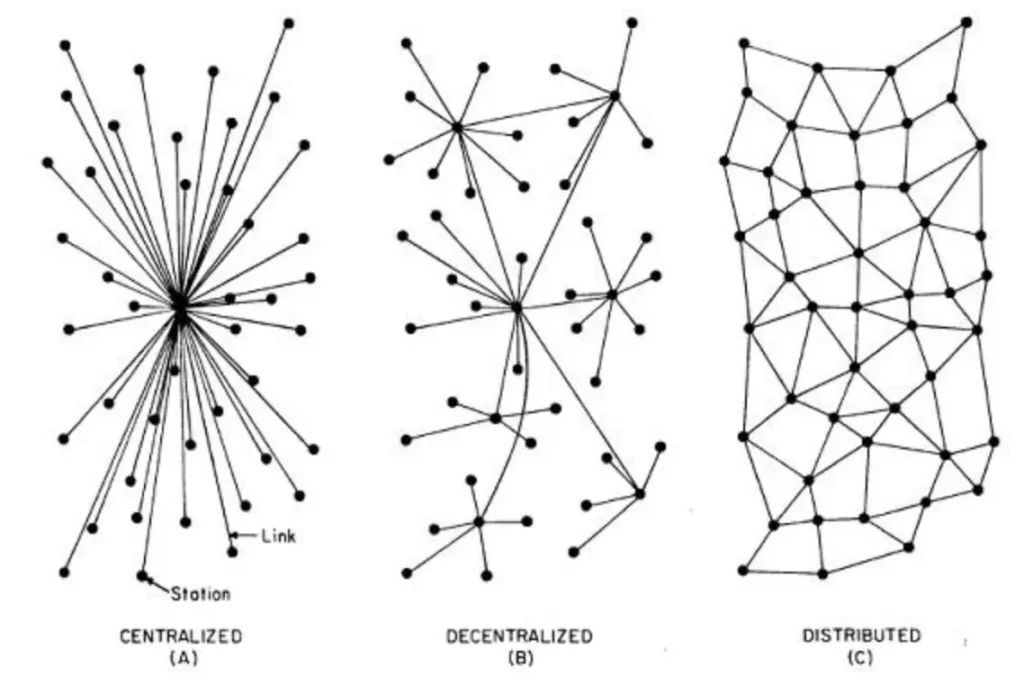
The reason a distributed system needs consensus protocol, is that a distributed system lacks a single source of truth as centralized systems do. Different parts of the distributed system may receive different signals but they must come to agreement of a single plan to act. Lamport studies this with an analogy of Byzantine Generals problem, and first proposed Paxos protocol. Paxos has been an important foundation to modern distributed systems. In Paxos, consensus is achieved in two phases, which creates the problem of livelocks. Raft is an alternative to Paxos, and is widely adopted today. Here is a link to an animated illustration for Raft protocol. The Raft protocol is also used in Redis. It has three roles: Leader, Candidate, and follower. ZAB protocol is similar to Raft, where it needs to select a leader.
Etcd Lab
In troubleshooting, if we suspect that the response from API server is inconsistent with etcd store, we want to directly connect to it.
Managed Kubernetes services do not expose their etcd store. We can use KinD or Minikube. There are two types of jump box to access etcd store: using etcd Pod, or SSH to a Node. To connect to etcd, we also need the X509 key, certificate and CA’s certificate, in addition to the endpoint, usually an IP with port 2389. When I connect to Pod shell, I find the command shell not easy to use. They might miss basic command such as ls, or do not support auto completion.
Take KinD for example, we first create a secret, then we can connect to the node with docker CLI command:
kubectl create ns myns
kubectl -n myns create secret generic mysecret --from-literal key1=value1
kubectl -n myns get secret mysecret -o jsonpath='{.data.key1}' | base64 -d
docker exec -it control /bin/bash
From the node,
apt update && apt install etcd-client
etcdctl version
nc -vz localhost 2379
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
export ETCDCTL_API=3
export ETCDCTL_CERT=/etc/kubernetes/pki/apiserver-etcd-client.crt
export ETCDCTL_KEY=/etc/kubernetes/pki/apiserver-etcd-client.key
export ETCDCTL_CACERT=/etc/kubernetes/pki/etcd/ca.crt
export ETCDCTL_ENDPOINTS='https://127.0.0.1:2379'
etcdctl member list write out=table
Now we can see the secret object directly with etcd store:
etcdctl get /registry/secrets/myns/mysecret
With get query, when using –prefix, we can use –keys-only switch to list keys without values:
etcdctl get --prefix /registry/api --keys-only
etcdctl get --prefix /registry/namespace -wjson
We can write key-value with put command:
etcdctl put myloc 0
etcdctl get myloc -wjson
In Kubernetes, all the key names start with / which makes the key looks like a POSIX path. Every Kubernetes object is stored in etcd with a unique key following a self-explanatory naming pattern. To display the path, we can also use debug log that records the call to API server:
kubectl get ns myns -v9
Look for curl command such as:
I0523 22:51:43.517728 32347 round_trippers.go:466] curl -v -XGET -H "Accept: application/json;as=Table;v=v1;g=meta.k8s.io,application/json;as=Table;v=v1beta1;g=meta.k8s.io,application/json" -H "User-Agent: kubectl/v1.23.6 (darwin/amd64) kubernetes/ad33385" 'https://127.0.0.1:64081/api/v1/namespaces/myns'
From there we can see the etcd query as the URI is namespaces/myns, which we use in etcdctl query path:
etcdctl get /registry/namespaces/myns
Every type of Kubernetes object has a storage.go file in their implementation that defines how api server should write object. Here is an example for Pod object.
Etcd also supports watch command to watch for changes. For example:
etcdctl watch --prefix /registry/namespace # watch output k create ns newns
Now we create a namespace with kubectl:
kubectl create ns myns
The output from etcdctl will reflect the change. The communication between etcdctl and etcd is gRPC protocol. The output is based on stream, as we can see from the watch result.
Etcd Maintenance
Like any distributed store, etcd needs maintenance and operation work. For example, we can check endpoint status with endpoint command:
etcdctl endpoint status
We can also backup and restore etcd store with etcdctl command:
etcdctl snapshot save /tmp/backup.db
This was an question in CKA exam. In real life, when the workload scales up, the etcd store may come across many pitfalls, such as degraded performance, unresponsiveness, some etcd member going down, network partition on etcd store causing split brain. It is important to ensure efficient communication between API server and etcd store. The etcdctl provides defrag and compact commands for common maintenance activities.