

Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability. In this post, I will introduce Ceph and explain how it stands out from traditional enterprise storage technology.
Software defined storage
In the realm of enterprise storage, I discussed PowerScale (Isilon) from Dell EMC, and touched on ONTAP by NetApp as an alternative. These solutions usually include both enterprise grade hardware, and the software layer that manages those expensive hardware. As the competition with cloud storage arises, those vendors start to decouple the software layer from the hardware to sell them separately. As a result, clients have the options to use commodity hardware. On the other hand, the software layer is built to be more accommodative to different hardware options. Eventually, the software layer evolves into Software Defined Storage (SDS) with the purpose of supporting cheaper storage hardware.
This table shows the full solution offering and SDS offering from NetApp and Dell EMC:
| Full solution offering | SDS offering | |
| NetApp | ONTAP | ONTAP Select |
| EMC | PowerScale | PowerFlex |
It is not easy to make a proprietary SDS appliance support commodity hardware. For example, PowerFlex currently supports (and bundles with) DELL’s commodity hardware only. It is most likely an involuntary move. Then, why would these commercial providers even be motivated to support a broader range of hardware by moving to SDS? It is because they face fierce competition from open-source SDS technologies, which were born to support commodity hardware. In this family of technologies, Ceph is a rising star. This family also includes other technologies such as Gluster and HDFS.
Note that the performance of a storage based on SDS still has to do with the underlying hardware. Therefore, comparing Ceph storage with PowerScale is apple to orange, without identical storage hardware. Now that we decoupled SDS and hardware, let’s take a look at two important aspects of SDS: the distributed technology to manage hardware, and the interface it provides to storage clients.
Distributed storage
The reason to use an SDS layer to manage hardware in a distributed architecture is for better scalability and high availability. The soul of this SDS layer is the ability to manage distributed system. However, a distributed storage introduces problems of its own, such as coordinating consistency. Different storage technologies have their own way to tackle these problems. For example, with PowerScale, OneFS has its own Group Management Protocol. Ceph uses CRUSH for data distribution. GlusterFS uses DHT(Distributed Hash Table) Translator.
Storage architects usually do not need to know these technologies in detail. It is not the intention of this post to cover the details of any distributed technology in any of the storage options above. However, storage architects needs to know supported API very well.
Access API
The supported access API of a storage system determines its compatibility with client systems. One good example is NFS for file storage, which defines the protocol for file share without defining the underlying implementation. Most GNU/Linux distributions come with nfsd (NFS server) which exports directories on XFS or ext4 FS as a file share with NFS protocol. In order to transfer data over network, NFS uses RPC, a request-response protocol. With object storage, S3 is a widespread protocol. Below is a list of storage implementations and their supported access API:
- Ceph supports librados, S3, Swift and FUSE
- GlusterFS supports SMB, NFS, FUSE,
- PowerScale supports NFS, SMB/CIFS, HDFS, Object, POSIX
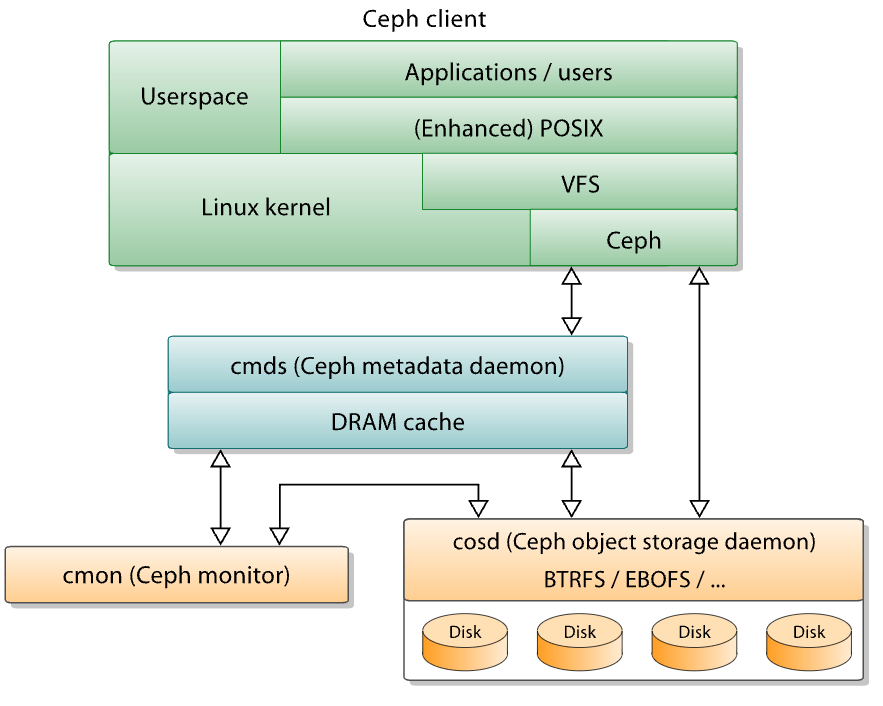
CephFS is distributed file system built on top of Ceph RADOS. It is also a client-server architecture. A Ceph Client, via librados, interacts directly with OSDs to store and retrieve data. In order to interact with OSDs, the client app must invoke librados and connect to a Ceph Monitor. For compatibility, CephFS namespaces can be export over NFS protocol using NFS-Ganesha NFS server.
Ceph Architecture
Ceph is a high-performance, distributed storage platform. It provides object storage, block storage and distributed file system, all backed by a single, reliable storage cluster running on commodity server hardware. A Ceph Storage Cluster consists of Ceph Nodes on a network. A Ceph Storage cluster requires at least one Ceph monitor (ceph-mon), Ceph Manager (ceph-mgr) and Ceph OSDs (ceph-osd). For file system clients, it also requires Ceph Metadata Server (MDS, ceph-mds) to allow user to execute basic commands on POSIX file system (e.g. ls, find)
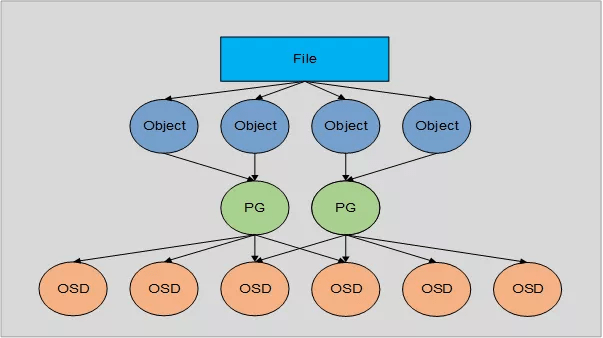
Under the hood, Ceph stores data as objects within logical storage pools. Using the CRUSH algorithm, Ceph calculates which placement group (PG) should contain the object, and which OSD should store the placement group. The CRUSH algorithm enables the Ceph Storage Cluster to scale, rebalance, and recover dynamically.
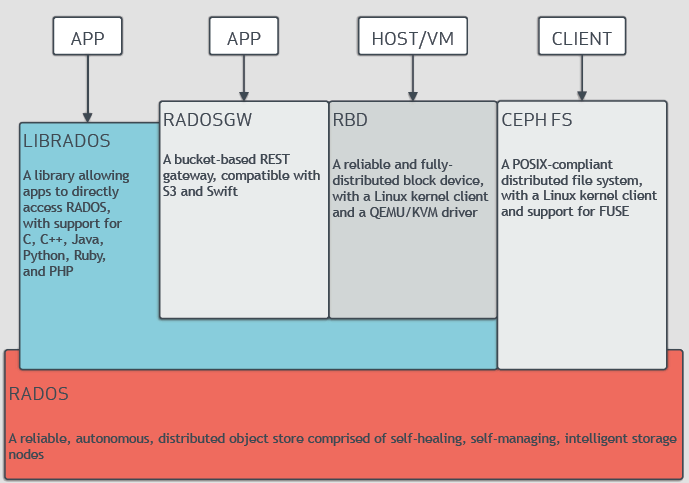
Ceph is based on RADOS (reliable autonomic distributed object store), a self-healing system that distributes and replicates data across nodes. It then layers CephFS (a distributed file system), block storage service (RADOS Block Device or RBD), and s3-compatible object storage (RADOS Gateway or RGW) on top of RADOS. For a better description, refer to this page. The chart above shows how Ceph interacts with different kinds of client. For CephFS, the client can interact with the file system via metadata daemon, as illustrated below. This diagram looks similar to the diagram for NFS.
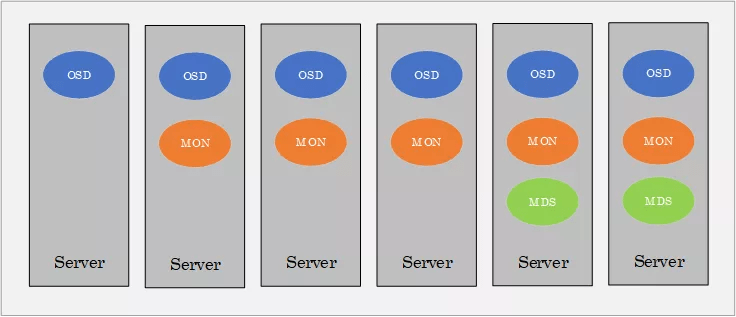
In a RADOS cluster, each server runs some daemons (i.e. OSD, MON or MDS).
When an I/O request occurs, it needs to be mapped to the specific OSD that keeps the storage units. Here is an illustration of the mapping:
As typically observed in distributed system, there is quite some communication overhead to serve a file.
Ceph Cluster Installation
Installing a VM-based Ceph cluster is no trivial effort and there are several methods. The recommended method is Cephadm. Here is a good instruction, where you will notice a lot of steps on each nodes, such as configuring NTP, installing docker, configuring hostname, Linux user and SSH, etc. You may also check this video for how involving it is. Red Hat adopts Ceph project as a product and has an installation guide on its documentation.
Previously, there was a legacy tool ceph-ansible to help administrators with server configuration. It is similar to the way kubespray helps administrators configure Kubernetes cluster. However, the document suggests that ceph-ansible is not integrated with new orchestrator APIs and therefore is not a viable option anymore. Also I did not find a way to install a single-node ceph cluster just for a quick demo. It involves tweaking the CRUSH map configuration.
If we deploy Ceph on Kubernetes for Kubernetes workload, we use Rook, an orchestrator running on Kubernetes, to integrate storage to a cluster.
Cloud Native Storage
Moving to cloud native storage, instead of presenting storage to operating system, we need to configure storage classes for Pods to use persistent volumes dynamically, using storage provisioners. Ceph also shows good presence in cloud native storage ecosystem. In a self-managed Kubernetes cluster, Ceph gives us the capability to configure storage classes to access connected storage. In public cloud, Ceph allows us to configure storage classes connecting to disks attached to the Nodes, an alternative to the cloud vendor provided native storage classes with high availability across availability zones. This layer enables the organization to normalize how their application connects to persistent volumes, a capability particularly helpful in the multi-cloud strategy of the cluster.
Rook is a CNCF project to orchestrate storage system on Kubernetes. It automates storage administrative tasks such as deployment, bootstrapping, configuring, provisioning and monitoring, using declarative templates. It supports Ceph and a number of other storage backends such as Cassandra, NFS, MinIO.