

File storage (e.g. NFS) used to be prevalent until object storage comes in for competition.
The competition
Traditionally, enterprise storage product lines are built around three capabilities, as listed in this table below:
| Capability | Typical Implementation | Data served | ||||
| T1 – Block stroage | DAS (e.g. SAS cable) or SAN (Fibre Cable for FCP protocol, or Ethernet for iSCSI protocol) | Mission critical data that are extremely sensitive to latency (e.g. database). Client has block-level access. | ||||
| T2 – File storage | NAS (connect via CIFS or NFS protocols). Storage arrays are typically a mix of HDD and SSD. Storage servers are usually deployed in the same location over low latency network. DR location is usually in the same region. | Hot data. Multiple client access at file level. The size of each data request varies from small to medium (e.g. text document) | ||||
| T3 – Object storage | Hardware agnostic, connect via layer-7 protocol (e.g. S3). Storage backend can be either on premise, or in the cloud, over WAN connection. | Warm and code data. Multiple client access at object level. Traditionally for backup but use cases are expanding. The size of each data request varies significantly, from small to very large (e.g. media content). |
In the last couple decades, leading players for T2 have been enterprise storage vendors. They each have developed their secret sauces to tackle the challenges. For example, EMC has OneFS, a parallel distributed file system as the foundation of PowerScale (formerly Isilon) product line. NetApp develops ONTAP, featuring proprietary techniques for storage efficiency (deduplication, compaction and compression).
The leading players in T3 are mostly public cloud provider, such as Amazon’s S3. They might work with enterprise storage vendor behind the scene. But the T3 services appear to the end users as provided by the public cloud. Originally, the use case for T3 was archive only for its virtually unlimited capacity. This is not entirely true today. With the drastic improvement in modern network infrastructure, T3 can also brings satisfactory performance to serve hot data.
A competition between T2 and T3 arises. After all, both offer storage service over Ethernet, and both support multiple clients. Today when developers architect the storage layer of their applications, they need to weigh between supporting T2 and T3. Since NFS is the typical protocol for T2 storage (sorry Windows guys) and S3 is typical T3 storage. This competition essentially boils down to NFS versus S3.
For many, the fancy S3 is a no-brainer. While I have suffered from many NFS drawbacks, and there’s even a whole article by Linux folks about why NFS sucks, is it sentenced to death today? Does it beat S3 in some cases? Do so many organizations still stick to NFS just out of inertia?
To answer these questions, I examine four aspects to explore the differences between file storage via NFS protocol, and object storage in S3.
Data request size
Storage client can make request by byte range of a file. Therefore, data request size, instead of file size, is what ultimately matters. I pick a few data request sizes (1K, 4K, 16K, 64K, 246K, 1024K and 4096K) in my experiment, and want to see how much network traffic a write operation produces using NFS and using S3.
To emulate request size, I created files at each size (using dd command), and copy the entire file to each backend. In the mean time, I use tcpdump to write out traffic across the wire into capture files. The size of capture file gives me an idea of how much network traffic went through the network interface, which is closely related to latency.
For NFS, I mounted the target with sync option. This requires NFS client to write out to server synchronously on file copy. I’ve also set the wsize to be 1M. For S3, I simply use the following CLI command to copy file:
aws s3 cp 1kb.img s3://digihunch5ffafe32ab0fd40f
On the network interface, I use tcpdump to filter traffic through specific TCP port (443 for S3, or 2049 for NFS) and record the size of the capture file:
sudo tcpdump -s0 -pi eth0 dst port 443 or src port 443 -w /tmp/4096kb.cap
The key indicator is the payload size (file size) as a percentage of the capture size. I call it payload ratio. The closer it is to 1, the better. I have the following result from my experiment:
| Request | Payload | S3 capture size (byte) | NFS capture size (byte) | S3 payload ratio | NFS payload ratio |
| 1K | 1024 | 9352 | 4332 | 0.11 | 0.24 |
| 4K | 4096 | 12640 | 7404 | 0.32 | 0.55 |
| 16K | 16384 | 25969 | 20472 | 0.63 | 0.80 |
| 64K | 65536 | 79183 | 69746 | 0.83 | 0.94 |
| 256K | 262144 | 290035 | 271408 | 0.90 | 0.97 |
| 1024K | 1048576 | 1085366 | 1074076 | 0.97 | 0.98 |
| 4096K | 4194304 | 4381547 | 4286910 | 0.96 | 0.98 |
This result indicates that NFS has a higher ratio in all groups. However, its advantage diminishes as the data request size grows. What it tells us is that if your applications workload issues most request in small chunks of data, such as 1K, 4K, then NFS will require much less traffic over the network, and thus less latency.
This essentially explains the use case of NFS against S3: workload with small data requests.
Client Support
NFS is natively supported by Linux operating system kernel. NFS client sits below the virtual file system (VFS) layer, which sits below the system call layer. The NFS client translate system calls into RPC (remote procedure calls). Communication between client and server is completed with RPC, on top of TCP.
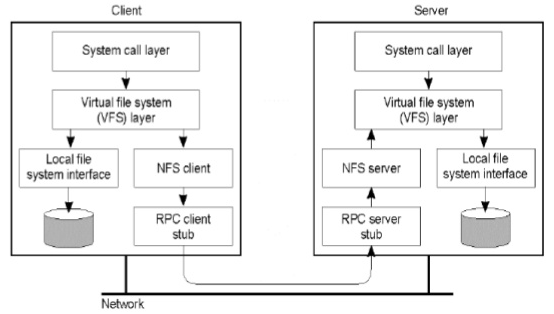
Because of the native support, in most cases, developer can treat NFS mounts as if they were local. For performance to be sustainable as file system grows, the directory structure on NFS should follow a certain naming conventions so that files are evenly distributed across directories. The client should also use list operation as sparse as it can because that operation is expensive across the network.
From developer’s perspective, NFS support is brought in by operating system and does not require much effort. On the other hand, S3 client support is not included by default in the operating system. S3 support requires special library, code changes, and integration effort to manage dependency and library version.
NFS has an advantage on client supportability. However, as we move applications to containers, and as container storage options mature, we will need an intermediary layer (storage class, storage provisioner, CSI driver, etc), NFS, or in general file storage, does not have this advantage any more.
Client-side Cache
The NFS support behind VFS layer also means it can leverage the I/O caching mechanism on the client side, that comes with operating system. Client operating system with sufficient memory can take advantage of this mechanism to give it a performance boost. Check out this guide for NFS cache tuning.
In comparison, S3 does not have a cache mechanism by itself. Either the application needs to implement its own cache mechanism, or a cache architecture needs to be introduced, such as CloudFront.
Consistency and concurrency
A common consistency problem is whether client can read the changes immediately after it writes the file. S3 and NFS make a tie in this round.
S3 originally came with eventual consistency model for read after write since 2006. As of Dec 2020 it introduced strong read-after-write consistency. For more information, refer to the guide here.
NFS has a similar consistency guarantee called close-to-open cache coherency. Any changes made by client are flushed to the server on closing the file, and a cache revalidation occurs when you re-open it.
There are more to consider in terms of consistency. For example, multiple clients tries to write the same file/object at the same time.
On the S3 side, there is a locking mechanism called S3 object lock at object level (no byte-range lock). Without an object lock, when two PUT requests are simultaneously made to an object, the request with the latest timestamp wins. Refer to the section Concurrent application on this page.
As far as NFS goes, managing this kind of consistency problem is not in the scope of the standard. Although there are some tinkers. For example, NFS v4 includes a file locking mechanism. Client can choose to lock the entire file, or a byte range within the file. Locking can be mandatory or advisory.
The convergence
NFS and S3 each has their respective advantage. Enterprise NAS customers have been looking for ways to expand into the cloud for lower storage cost. To combine the advantages of the two, solution providers started to converge file storage and object storage. There are two types of solutions that reflects this trend of convergence. In the first trend, enterprise NAS deployed on premise now have the ability to scale out into the cloud. In the second trend, public cloud just brought enterprise NAS into their product offerings.
Scale-out NAS
NAS is traditionally expensive to scale because it requires physical storage media. The idea of scale-out NAS allows NAS to connect to object storage in the public cloud, making it a hybrid architecture. This essentially makes T3 storage as a backend of T2 and it can be implemented with a virtual storage appliance (VSA). The VSA translate file system activities into API calls for object storage operations. One example is AWS storage gateway. EMC has a similar appliance called ECS and this white paper explains how it proxies file system calls and interact with object backends. NetApp, a vested enterprise NAS provider, also has a counterpart called Cloud Volumes ONTAP (CVO). It works well with NetApp on-premise deployment, but the architecture is similar. Here‘s NetApp’s take on how CVO is different than AWS Storage Gateway.
In the scale-out NAS architecture, the public cloud acts merely as extension to on-premise storage solution, to provide capacity. The NAS on premise serves the storage workload primarily.
Cloud hosted NAS
For applications hosted in public cloud, it makes sense for public cloud provider to operate enterprise NAS storage as a service. The underlying storage technology is provided by storage vendor. It is just installed in the data centre managed by the public cloud vendor, instead of customer’s own data centre.
One example is Azure NetApp Files (ANF). ANF is fully managed services, presented to users as storage volumes. The underlying storage technology is NetApp ONTAP. Because it is offered as a fully managed service, the customers are not able to manage the fine details of the storage, as they could with an ONTAP cluster on premise. This takes a lot of flexibility away from the user.
FSx ONTAP is a managed NetApp storage service by AWS, launched in September 2021. The NetApp arrays are installed in AWS data centre, ready for users to provision from AWS console, or using CLI. The Terraform provider support is not available as of yet. Unlike ANF, FSx ONTAP exposes the ONTAP CLI to users, allowing for advanced storage managed by storage gurus. They can use ONTAP CLI commands to configure custom policy for Snapshot, setup SnapMirror replication, and so forth.
Likewise, PowerScale landed on GCP as public cloud partner to launch Dell Cloud PowerScale for Google Cloud in 2020. However, it seems to require a purchase agreement before APIs are enabled.
Conclusion
Object storage has a great momentum and some sees that as a replacement of file storage in the long run. However file storage has its advantages for small data requests, OS-level cache support, and built-in POSIX compatibility. It will continue to be an option for customers with specific workload. Customer stickiness to file storage is so firm, that public cloud providers now install them in their data centres.
From competition to collaboration, it will be interesting to watch what happens next for enterprise storage.
Follow-up Reading
Tom Lyon’s presentation on why NFS must die.