
In a narrow sense, cloud storage refers to object storage. In a broader sense, it refers to any storage service (block, file or object level) provided by cloud vendors, in a cloud business model. The underlying technology of storage, is the same be it in the cloud or on-premise.
| Block storage | File storage | Object | |
| Interaction with OS | OS has direct byte-level access to disk blocks. | OS manages storage by file, or byte range of file. Files are organized in POSIX hierarchy. | OS reads and writes the entire object, or a byte range, via rest API calls. |
| Metadata | N/A | Stored in file system, for directory or file | customizable metadata |
| Common protocol | N/A | NFS | S3 |
| Implementation | SAN (bock device is typically dedicated to a single VM) or DAS | NAS, file storage is usually shared amongst multiple VMs. Locking mechanism is usually in place to keep access in order. | S3 |
| Workload | database storage, scratch data, etc | persistent data, content management, etc | archive data, media streaming, data analytics, static asset serving, etc |
Below is a list of common storage services provided by public cloud vendors to day.
| Block Storage | File Storage | Object Storage | Other managed storage service | |
| AWS | Elastic Block Store (EBS) | Elastic File System (EFS) FSx for Windows FSx for Lustre | Simple Storage Service (S3) | Storage Gateway Snow Family DataSync |
| Azure | Azure Managed Disks | Azure Files | Azure Blobs | Azure Table Azure Queues |
| GCP | Persistent Disk local SSD | Filestore | Cloud Storage | Cloud Storage for Firebase Data Transfer |
| Digital Ocean | Volumes Block storage local SSD | N/A | Space object storage (S3 compatible) | Content Delivery Network |
Since AWS is the first vendor that provides a full suite of storage service, this post will focus on the storage product lines, as a refresher of AWS cloud storage options: Simple Storage Service, Elastic File Storage and Elastic Block Storage). There will be some overlap with the AWS storage service whitepaper.
Before getting further to details, here’s a reminder of two types of policies in AWS:
| IAM policy | Resource-based policy | |
| Principal | Must be attached to individual user, group, or role to take effect | Needs to be explicitly specified, can be ARN under other AWS account |
| Element | Action/NotAction Resource/NotResource Effect (Allow/Deny) Condition | Principal/NotPrincipal Action/NotAction Resource/NotResource Effect (Allow/Deny) Condition |
| Example | Managed policy, custom policy | File system policy, S3 bucket policy, access point policy, etc |
Although the resource is usually assumed in a resource-based policy, the policy usually target a sub-section of a resource (e.g. object with certain prefix), so resource section is still required in resource-based policy. In storage services, we may use S3 bucket policy, access point policy, or file system policy for EFS.
Below we go over the three families of storage service in AWS.
EBS (Elastic Block Storage)
EBS is a distributed system. Each volume is a logical volume, made up of multiple physical devices. EBS data is persistent, and access is dedicated to a single EC2 instance at a time. If EC2 instance failed, the attached EBS volume can be detached, and then re-attached to other instance, in the same Availability Zone. There are two types of EBS:
- EC2 Instance store: ephemeral, block-level storage for EC2 instance, no replication by default, no snapshot support. Used as buffers, caches, scratch data, temporary content.
- EBS volume (persistent) : used for database, dev/test, enterprise application, etc. There are two sub-categories:
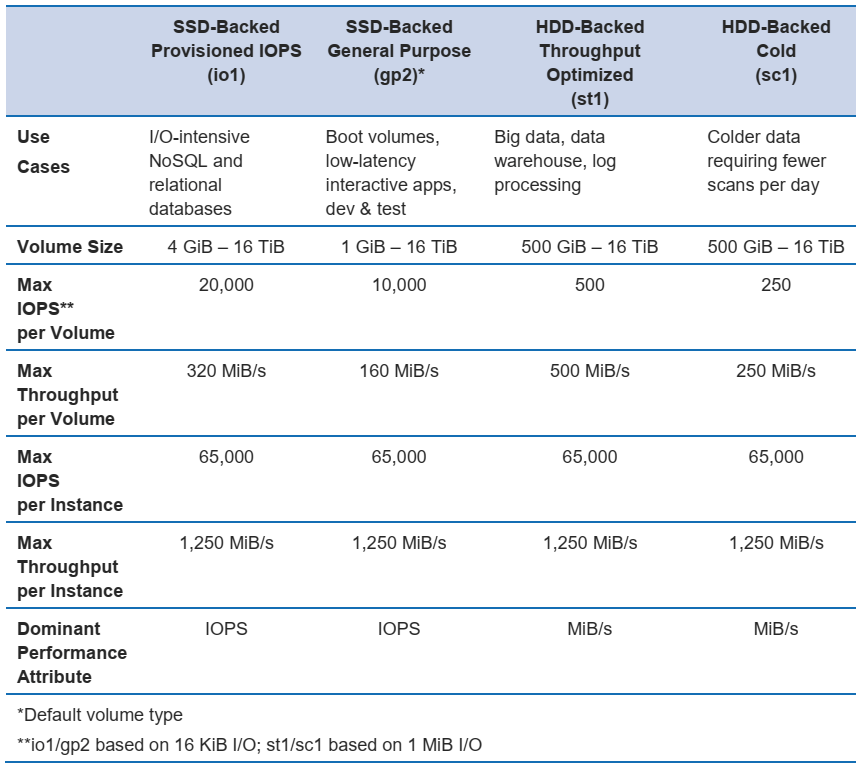
- SSD-backed volumes:
- Optimized for transnational workloads that requires very low latency
- Dominant performance attribute is IOPS
- For frequent, read/write with small size and random I/O
- Typical use case include relational database (PostgresQL, MySQL) and NoSQL (Cassandra, Mongo)
- gp2 (general purpose) and io1 (provisioned IOPS)
- HDD-backed volumes:
- Optimized for large streaming workloads demanding throughput
- Dominant performance attribute is throughput
- For workloads with lots of sequential I/O
- Typical use case icnlude big data, analytics (Kafka, Splunk, Hadoop, data warehousing), file/media server
- st1 (throughput optimized0 and sc1 (cold HDD)
- SSD-backed volumes:
The four types of EBS are compared here:
Note that the volume can be modified (change type, increase size) after creation. However, you cannot decrease size. If you increase the size, the file system must be extended after the increase.
Another way to deliver better performance is to use EBS-optimized instances. These instances have dedicated network bandwidth for its I/O traffic to and from EBS. Without EBS-optimized instance, the traffic between EBS volume and EC2 instance uses shared network link with EC2, which is subject to latency during heavy traffic. This distinction is similiar to the difference between iSCSI SAN and FC SAN. Also, you may increase read-ahead buffer in OS for better EBS performance.
On EBS, users can create snapshot, a point-in-time incremental backup. When snapshot is restored to a volume, data is loaded lazily in the background, so that volume is available immediately. This also means that initial read of data that is not yet loaded will be subject to latency, known as first read penalty. To achieve target performance, user may run an initialization on the volume, by reading all blocks with data upfront.
In a newly created snapshot, only the data blocks modified since the previous snapshot are stored as is. The rest are pointers to unchanged data blocks in the original snapshot. When a previous snapshot is deleted, AWS ensures changes are reconciled into the newer snapshot so there is no loss of data. Creation of snapshots on many volumes can be automated with Data Lifecycle Manager (DLM).
As far as encryption goes, the best practice is to create your own master key. KMS uses envelop encryption, where the data key encrypts the data, and the master key encrypts the data key. The encryption key is stored in EC2 instance memory only and never written to disk, for security and performance considerations.
EFS (Elastic File Storage)
EFS is a managed implementation of file storage that supports NFS 4.0 and 4.1, with strong data consistency and file locking. An EFS includes a single mount target in (one subnet of) each availability zone. EC2 instance, or on-premise client via Direct Connect, can mount EFS volumes using amazon-efs-utils yum package. EC2 instance can also be configured to automatic mount EFS volume in launch wizard. EFS also has a lifecycle management policy, and a storage class for infrequent access.
Performance wise, EFS has two performance modes and two throughput modes. The two performance modes are:
- General Purpose: for latency-sensitive applications and general-purpose workloads. limit of 7k ops/sec, best choice for most workloads
- Max I/O: for large-scale and data-heavy applications, with virtually unlimited ability to scale out throughput/IOPS, but with slightly higher latencies. consider this for large scale-out workloads
The two throughput modes are:
- Bursting throughput: recommended for the majority of workload. Since file system workload is typically spiky, aws use credit system to determine when the file system throughput can burst. credit accumates idle time, and consumed in retrieval
- Provisioned throughput: recommended for higher throughput to storage ratio workload, can increase the provisioned throughput afterwards. but it incurs separate throughput charge
Other ways to achieve higher performance, include parallelization of file operation (e.g. multiple threads, more instances); and increase I/O size for better throughput.
In terms of security, EFS encryption at rest must be selected at the time of file system creation. There is an TLS mount option to encrypt traffic in transit. EFS involves its own resource-based policy called file system policy to manage file-level POSIX permissions. IAM policy is used to manage NFS administration access and client access. EFS access points is also a means to enforce the use of a specific operating system user, and group to access EFS.
S3 (Simple Storage Service)
S3 is one of the earliest and maturest AWS services for object storage. It is very cheap and easy to use, and supports user-defined metadata on objects as well as many peripheral features. There is no limit to the number of objects in a bucket. As the object in bucket increases, S3 scales to request rate by automatically creating more partitions to meet the target number of request per partition. There used to be a performance trick, that requires client to make object key naming pattern distribute across multiple prefixes. It is not required any more as of July 2018.
Versioning can be enabled at bucket level, and suspended afterwards. New version of object is created on every upload, without performance penalty.
S3 integrate well with other event-driven AWS services, such as SNS, SQS, Lambda, etc. Event can fire on request such as PUT, POST, COPY.
Object tags (not to be confused with object metadata) can help categorize storage. It also facilitates access control (i.e. by being referenced in bucket policy or IAM policy), lifecycle policy, analysis and CloudWatch configurations.
S3 select is a way to retrieve only a subset of data from an object based on a SQL expression, to reduce amount of data and help with performance. The input can be json or CSV and output will be in CSV.
S3 Inventory is a tool to audit object replication status and encryption status. It generates CSV report with all objects in the given bucket name, including: key name, version id, islatest, size, last modified date, etag, storage class, multipart upload flag, delete marker, replication status, encryption status. For storage-class analysis, S3 inventory is much faster than list-object API call which parses through all objects.
S3 also has access point, similar to EFS, with unique hostnames that customers create to enforce distinct permissions and network controls for any request made through the access point.
S3 transfer acceleration take advantage of edge locations (at additional charge) to speed up transfer of large object over long distance, by providing a separate end point. It is also helpful for faster uploads over long distances. Apart from transfer acceleration, for faster uploads for large object, user may also consider multi-part upload API when the object reaches 100MB. Orphaned uploaded parts can be cleaned up in lifecycle configuration. For better download performance, take advantage of CloudFront and byte range request.