

The Three-layer model
Kubernetes is so complex that it becomes a buzz word itself. I categorize the related work into three layers: a cluster layer, a platform layer and an application layer, by their purposes. The three layers are illustrated as below:
Let’s examine each layer in this model and where the Kubernetes Platform as a Service fits in.
The Kubernetes Cluster Layer
At the bottom, the Kubernetes Cluster layer is the foundational layer. It focus on using self-hosted VMs or cloud resources to build a functional Kubernetes cluster and worker node groups. A functional cluster includes a highly available control plane, as well as scalable node groups that all communicate with the control plane. Cloud Service Providers like AWS and Azure provides managed Kubernetes service, which takes away the complexity (and flexibility as well) of managing control plane components such as etcd store and API server. The managed services also automatically provisions computing nodes and join them into the cluster. The cluster layer may also involve integration with of CNI and CSI, to ensure Pod-to-Pod communication and available storage classes.
Professionals working at this layer are infrastructure experts who understand networking, storage, as well as how to manage cloud resources or VMs, infrastructure as code. On a daily basis, they deal with VPCs/V-Nets, subnets, EBS/Azure Disk, File storage, EC2/Azure VMs, etc. When the team is doing a bad job at this layer, you might see symptoms like unresponsive cluster API, orphaned worker nodes, or kubectl failing to connect to cluster endpoint.
The tenants (applications) of the Kubernetes platform does not directly interact with this layer. If you decide to switch CSP vendor, this layer requires 100% re-engineering because the managed Kubernetes service by each CSP is different.
The Kubernetes Platform Layer
The Platform layer sits in the middle. When organization decides to adopt Kubernetes, they often underestimate the efforts required in this layer. This layer works on a functional cluster, without directly interacting with the underlying cloud resources. This layer involves any Kubernetes abstractions that do not creates tangible business value. Rather, this layer is an enabler. It allows the applications to deploy smoothly, evolve quickly, and more importantly, focus on the business.
Teams working on this layer needs to be Kubernetes experts. On a daily basis, they play with common CNCF toolings, such as Prometheus, ArgoCD, Istio, Cilium, Tekton, Open Policy Agent, etc. They are comfortable with Operators, Helm Charts, Ingress, etc. Inside of the Kubernetes cluster, they also manage the foundational services such as Event streaming (e.g. Kafka), PostgreSQL database (e.g. PostgreSQL), software-defined storage (e.g. Ceph), service mesh (e.g. Istio), Authentication (e.g. Keykloak) , etc. These services act as the infrastructure layer to the business workload. If the team is doing a bad job, you would see data loss with database, observability service not populating data, ingress does not process request, etc.
The tenants (application) share services in this layer. If you decide to switch CSP vendor. I estimate 80% of the work at this layer is portable, and 20% requires re-engineering. That is because each CSP offers different external resources, therefor the low level Kubernetes objects in this layer, such as storage classes, load balancers, supported CNIs are different. High level objects such as Kafka remains portable across platforms.
The Application Layer
The next layer at the top is application layer. Workloads in this layer are directly linked to the business value. The applications are very diverse. Most of the time, the release team is the main player at this layer. If the organization develops its own application, the software development team also work at this layer.
In terms of knowledge, the members of development team are experts in software engineering, and Software Development Life Cycle (SDLC), etc. On a daily basis, they deal with programming languages, product development, build and release. If they screw up their work, expect business errors, such as orders sent to wrong client, incorrect balance sheet, etc. This team has high visibility in the organization due to its direct link to business value.
This layer of work involves multiple tenants. Each tenant is isolated within their own namespace. When you switch CSP vendor, this layer should be readily portable with minimal effort.
It is also worth noting that, with solid platform and cluster layers, the team working at this layer do not write bespoke code for networking, observability, authentication and authorization, encryption and many other aspects not relevant to the core business. Once deployed, the application services are resilient, scale to demands, and cost efficient. This layer reaps the benefits of Kubernetes.
Kubernetes Platform as a Service
As the Kubernetes dust is still settling, a builder’s title may not always reflect which layer she or he focuses on. Today it is pretty common for infrastructure engineers to expand their role into the platform layer, or likewise, a software engineer to drill down to the platform layer.
The boundary between platform layer and cluster layer is clear. The cluster layer deals with underlying infrastructure, either in the cloud or on premise. They abstract away the complex infrastructure world from those working with the platform layer.
The boundary between platform layer and application layer is a little tricky to articulate. The application layer focuses on implementing the business logics. The platform layer takes care of the functions that are not part of business logic but essential to the business application. Take an HTTP request for example, application developer should not have to write code to terminate TLS (not part of business logic). They should only write the code to process the HTTP request (business logic). TLS termination is delegated to an Ingress, to be configured by platform builders.
The folks working at the Platform layer needs to interface with both sides. They provide Platform as a Service to the Application teams. However, their work appears mostly invisible in an organization. Their effort is oftentimes underestimated. There are several reasons for that. First, the platform layer does not directly create tangible business value. They are just someone else’s enabler. Second, their building blocks involve a lot of abstractions by Kubernetes API. Third, the idea of platform engineering is newly emerged. There hasn’t been a populous recognition of its value.
Red Hat OpenShift Container Platform
The platform team builds the platform with their choice of open-source tools. For clusters using OpenShift Kubernetes Engine, Red Hat introduces Open Shift container platform consisting of Red Hat’s opinionated (but validated) choice of toolings, for example:
- OpenShift Service Mesh: Istio
- OpenShift Streams: Apache Kafka
- OpenShift GitOps: ArgoCD
- OpenShift Container Platform Pipelines: Tekton
- OpenShift Serverless: Knative
- OpenShift Data Foundation: Ceph
Clients building their clusters with OpenShift Kubernetes Engine may build their own platform with the toolings in the OpenShift enterprise Kubernetes container platform. For more services, check out the documentation for OpenShift Container Platform. For customers with OpenShift Kubernetes Engine, their options to DIY platform are:
- Entry-Level: Red Hat OpenShift Kubernetes Engine: Enterprise Kubernetes distribution on RHEL CoreOS
- Mid-Level: Red Hat OpenShift Container Platform (RHOCP):
- Plus-Level: Red Hat OpenShift Platform Plus: RHOCP + advanced cluster management, security, data management essentials, enterprise container registry
OpenShift runs the business model of Kubernetes PaaS.This is a unique business model that I do not find a matching competitor. Even if you choose to DIY your own platform, the Red Hat’s choices are still a great reference. The OpenShift enterprise Kubernetes container platform maps perfectly to the platform layer of the three-layer model, aiming to simplify the work in the platform layer.
Managed RedHat OpenShift
At first, the OpenShift container platform started as a value add-on to the Kubernetes Engine. Now it’s a separate product line in their business model. In the mean time, OpenShift partners with major CSPs, to develop the cloud service editions, including:
- Red Hat OpenShift on AWS (ROSA)
- Microsoft Azure Red Hat OpenShift (ARO)
- Red Hat OpenShift Dedicated – on AWS and GCP
- Red Hat OpenShift on IBM Cloud
These offerings are managed Kubernetes Platform as a Service in the cloud. Since RedHat is the only player in this model, we can refer to them as managed OpenShift services. In addition to an already-confusing world of Kubernetes platform portfolios, these offerings gives consumers even more options. On AWS for example, users have the following options:
- Managed Platform: OpenShift Dedicated, managed by Red Hat
- Managed Platform: Red Hat OpenShift Service on AWS (ROSA), managed by Red Hat and AWS
- Self-built cluster: OpenShift Container Platform
This video discussed more details about these options, such as support model. It is also worth noting that these options tend to be much pricier than managed clusters such as EKS and AKS.
Since a Managed RedHat Platform makes it easy to deploy, let’s take ROSA as an example and create a cluster. To enable ROSA in AWS console, click on “Getting Started”. The next page ensures ROSA is enabled and checks other prerequisite such as meeting service quotas and creating ELB service-linked role, as show below:
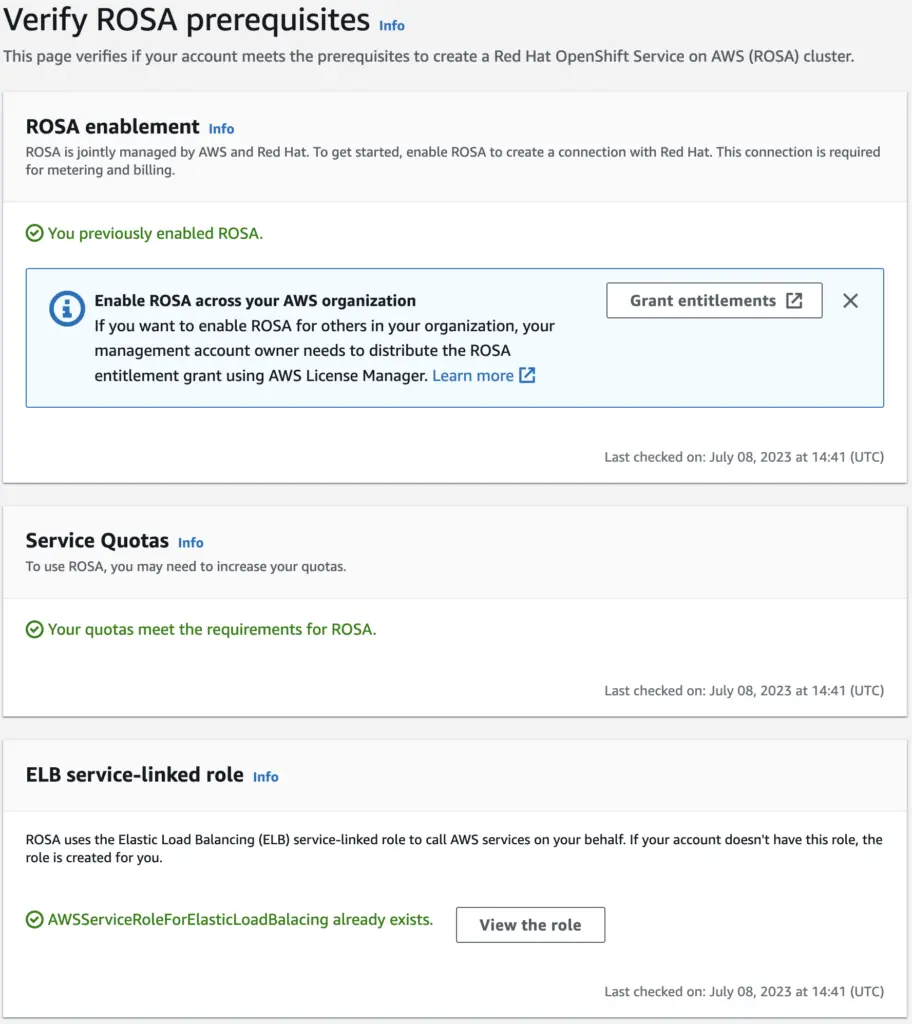
Now, with an AWS account (and ROSA enabled), a RedHat account, and the rosa-cli utility, we can create a cluster with just a few commands. As a note, be wary of the cost and do not forget to delete the cluster afterwards.
Create a ROSA cluster
With the following set of commands, we can kick off cluster creation, using STS. We can bring our own VPC, so long as it meets certain prerequisites. I use the Terraform template in the vpc-base project, to create the underlying VPC. We’ll need the followings from this template:
- The CIDR range of the VPC: as input with a default
- The subnet Ids of the private subnet to place, printed in the output
The subnets are private subnets, because we want to provision the cluster with private node and private endpoint. When we use rosa CLI, we provide the CIDR and subnet IDs.
# start with AWS cli configured to the correct profile
rosa login # with redhat account and past token
rosa create account-roles --mode auto -y # this command creates the IAM roles ManagedOpenShift-*-Role, with RedHat account as trust entity
rosa verify permissions # optional
rosa verify quota # optional
export ROSA_CLUSTER_NAME="dhc" \
OPENSHIFT_VERSION=4.13.4 \
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) \
AWS_DEFAULT_REGION=us-east-1
rosa create cluster --sts --private \
--cluster-name $ROSA_CLUSTER_NAME \
--multi-az \
--private-link \
--region $AWS_DEFAULT_REGION \
--version $OPENSHIFT_VERSION \
--enable-autoscaling \
--min-replicas 3 \
--max-replicas 3 \
--compute-machine-type m5.xlarge \
--machine-cidr 147.206.0.0/16 \
--subnet-ids subnet-052852a1fb4d7d2ad,subnet-06d8d40ae39d55c47,subnet-0f67ce08bc588012c
The CLI will pick up the correct VPC by CIDR, and prompt you to confirm creation of private cluster. After the command kicks off, it will wait for OIDC provider creation, and role creation. Then it uses a Terraform template to create the related resources including VPC. Use this command to check status:
rosa list clusters
rosa describe cluster -c dhc
When the second command displays the state of waiting (Waiting for OIDC configuration), we can create OIDC provider:
rosa create operator-roles -c $ROSA_CLUSTER_NAME --mode auto --yes
rosa create oidc-provider -c $ROSA_CLUSTER_NAME --mode auto --yes
Throughout the process, we can monitor the install log (terraform output) with:
rosa logs install -c dhc --watch
In the log, you might see errors with terminals connecting to the terraform backend, which doesn’t necessarily indicate a cluster creation error. Always check the cluster state until it reports success.
Kick the tires
Eventually the describe cluster command will show ready state. We can now create an admin user:
rosa create admin -c $ROSA_CLUSTER_NAME
The command above prints an oc command (OpenShift CLI, equivalent to kubectl) with password to log in. Let’s examine the cluster with oc. Because it is a private cluster, the endpoint is not available publicly. However, it is accessible from the Bastion host. Use the SSM Session Manager technique from my previous post to SSH to the Bastion Host, which should have oc installed. To install oc yourself, use HomeBrew on Mac. On Linux or Windows, log on to OpenShift console, go to Downloads on the left pannel and find it out under CLI tools.
The oc command may report insecure TLS on the login URL. Wait for a few minutes for the certificate to come off as safe. Once you run the oc command with password, it should return “Login successful” and then we can connect to the cluster:
$ oc get node # or kubectl get node
NAME STATUS ROLES AGE VERSION
ip-147-206-135-41.ec2.internal Ready,SchedulingDisabled infra,worker 3m5s v1.26.5+7d22122
ip-147-206-155-141.ec2.internal Ready control-plane,master 25m v1.26.5+7d22122
ip-147-206-156-81.ec2.internal Ready worker 19m v1.26.5+7d22122
ip-147-206-164-21.ec2.internal Ready infra,worker 3m3s v1.26.5+7d22122
ip-147-206-179-90.ec2.internal Ready worker 19m v1.26.5+7d22122
ip-147-206-191-118.ec2.internal Ready,SchedulingDisabled control-plane,master 26m v1.26.5+7d22122
ip-147-206-192-232.ec2.internal Ready worker 19m v1.26.5+7d22122
ip-147-206-193-198.ec2.internal Ready infra,worker 3m20s v1.26.5+7d22122
ip-147-206-218-114.ec2.internal Ready control-plane,master 26m v1.26.5+7d22122
You can use oc the same way you’d use kubectl. Both works through SOCK5 proxy. In the meantime, log in to the RedHat console with your Red Hat credential, you can see the cluster in Ready state as well:
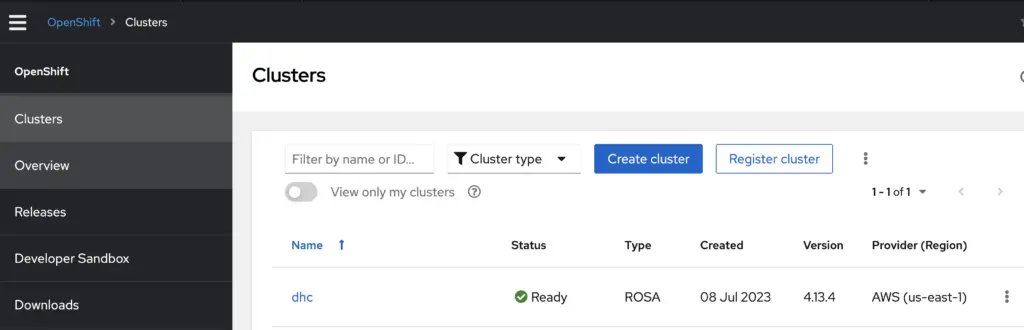
The rosa create admin command creates a htpasswd type (username-password) of identity provider (IdP) with a user named cluster-admin and a preset password. In real life however, we often configure third party IdP with OIDC integration. I’ll have to leave this to the next blog post.
We shall see the nodes as EC2 instances from AWS console as well. Note that there are three roles: control-plane, worker and infra. The infra nodes are for infrastructure services. These services (Ingress Controller, GitOps, Pipeliens) are the ones in the platform player as we discussed above.
There are many customizations you can make in this installation process and I’d have to defer to the ROSA documentation. To clean up, use the following ROSA command:
rosa remove cluster -c dhc
The output also gives you the command to delete operator roles and OIDC provider, for example:
rosa delete operator-roles -c 23o4u3j98tqmlbtjo612opb7a4bbim5f --mode auto --yes
rosa delete oidc-provider -c 23o4u3j98tqmlbtjo612opb7a4bbim5f --mode auto --yes
Then we can destroy the VPCs using terraform.
ROSA with HCP
Update Oct 2023:
The deployment above provisioned a few nodes for control plane, which add to the overall time to provision a cluster. In Aug 2023, there is a new option Hosted Control Plane (HCP) that came to allow users to provision a hosted control plane. This results in cost savings and shorter time to provision a cluster. Here is a table of comparison between the ROSA with HCP and ROSA classic.
Final words
In this post, I discussed the three-layer model and pointed out that platform layer isn’t as visible as the other two. I also experimented ROSA as a turn-key Kubernetes platform with its opinionated stack of services.
Some misinformed organizations even skip the entire platform layer in their estimate of effort. They build a cluster, ran a hello-world service and assumes they can start putting applications on the Kubernetes cluster. There are also customers who purchased the entire Managed OpenShift platform but only use it as a cluster. Yikes!
The concept of Kubernetes platform, or generally platform engineering is still spreading. The consulting team that I worked in full-time last year re-branded itself as platform engineering. Marketings are pushing it. Builders are doing it. We’ll keep an eye, on whether customers are buying it.