
Modern applications produce super large datasets beyond what traditional data-processing application can handle. Big data is a discipline that specialize in processing such data. For example, analysis, information extraction etc. The scale of large dataset grows well beyond the capacity of a single computer, which calls for computing power delivered by multi-node clustered systems. Intensive computing tasks are completed in a distributed system consisting multiple nodes each performing some tasks, known as High-Performance Computing Cluster (HPCC).
Cluster computing inherit the challenges of distributed system. Moreover, two main challenges to solve are: distributed storage, and distributed computation. In Apache Hadoop projects, HDFS and MapReduce address these two challenges respectively. Now the Hadoop ecosystem has evolved to include several core projects:
HDFS
A distributed file system for reliably storing huge amount of unstructured, semi-structured or structured data in the form of files. Parts of a single large file can be stored on different nodes across the cluster. HDFS works in master-slave mode:
- NameNode (master): holds file system namespace, controls access, keep track of DataNodes and replication factor
- DataNode (slave): stores user data
HDFS is Java-based so is portable across all platforms. User interact with HDFS using a command-line interface called “FS shell”. There is also an interface called FUSE (filesystem in userspace) to mount HDFS to Linux OS. Since HDFS supports commodity hardware it is great for storing data for further processing. However, HDFS is not suitable for storing data related to applications requiring low latency access, nor is it good for simultaneous writes to the same file. Also HDFS is not suitable for large number of small files because the metadata for each file needs to be stored on the NameNode and is held in memory. Here is the architecture guide for HDFS, and this page expands further on the read and write operations in HDFS.
Compared to NAS(e.g. NFS), HDFS is distributed by design. The data blocks are distributed across different nodes. NFS storage may or may not be distributed depending on the implementation. HDFS is designed to work with MapReduce paradigm, where computation is moved to the data. In NAS, data is stored separately from the computations. Lastly, NAS is usually made up of enterprise grade hard drive but HDFS works with commodity hardware.
MapReduce
Hadoop MapRecude is a distributed algorithm framework that allows parallel processing of huge amounts of data. It breaks a large chunk into smaller ones to be processed separately on different data nodes and automatically gather the results across the multiple nodes to return a single result. If the duration of linear data processing can be done during night hours, it makes sense to choose Hadoop MapReduce. MapReduce runs on Hadoop cluster but also supports other database formats like Cassandra and HBase. MapReduce includes:
- Job: a unit of work to be performed as requested by the client.
- Task: Jobs are divided into sub-jobs known as tasks. The tasks can be run independent of each other on different nodes. There are two types of tasks:
- Map task is performed by map() function to process one or more chunks of data and produce the output results
- Reduce task is performed by reduce() function to consolidate the results produced by each of the map task
- JobTracker: like the storage (HDFS), the computation (MapReduce) also works in master-slave fashion. A JobTracker node acts as the master to schedule task on appropriate nodes, coordinate execution of tasks, get the result back after execution of each task, re-execute failed tasks, and monitor overall progress. There is only one JobTracker node per Hadoop Cluster.
- TaskTracker: a TaskTracker node acts as teh slave and is responsible for executing a task assigned to it by the JobTracker. There are usually a number of JobTracker nodes in a Hadoop Cluster. They execute the heavy lifting tasks.
- Data Locality: if MapReduce cannot place the data and the compute on the same node, data locality put the compute on the node nearest to the respective data node(s) which contains the data to be processed.
The MapReduce programming model includes these steps: input->split->map->combine->shuffle&sort->reduce->output.

YARN
YARN (yet another resource negotiator) is a system to schedule applications and services on an HDFS cluster and manage the cluster resources like memory and CPU. The two components are:
- ResourceManager: receives the processing requests, and then passes the parts of requests to corresponding NodeManager accordingly based on the needs. ResourceManager is a central authority.
- NodeManager: installed on every DataNode, is responsible for execution of the task on every single DataNode, monitoring the resource usage and reporting to the ResourceManager.
HBase
A key-value pair NoSQL database based on HDFS storage, with column family data representation, and mater-slave replication. HBase is based on Google’s BigTable concept (similar to Cassandra). It runs on a cluster of commodity hardware and scales linearly. Compared with Cassandra, HBase doesn’t have a query language of its own. You will have to work with JRuby-based shell, or Apache Hive. HBase is also a master-slave architecture and it uses Zookeeper as a status manager. In that sense, Cassandra is a “self-sufficient” database technology whereas HBase relies on other components in Hadoop. This article also compares the data model difference between the two.
Hive
Hive is a SQL interface over MapReduce for developers and analysts who prefer SQL interface over native Java MapReduce programming to query and manage large datasets residing in HDFS. With Hive you can map a tabular structure on to data stored in distributed storage. The Hive queries are written in SQL-like language known as HiveQL, executed via MapReduce. When a HiveQL query is issued, it triggers a Map and/or Reduce job(s) to perform the operation defined in the query.
Pig
A scripting interface over MapReduce for developers who prefer scripting interface over the native Java MapReduce programming. It is a runtime environment with a shell (named Grunt Shell) for execution of MapReduce jobs via a high-level scripting language called Pig Latin. Pig is an abstraction (high-level programming language) on top of a Hadoop cluster. The Pig Latin query/command are complied into one or more MapReduce jobs and then executed on Hadoop cluster. The most common commands in Pig are:
- DUMP: displays the results to screen
- STORE: stores the results to HDFS
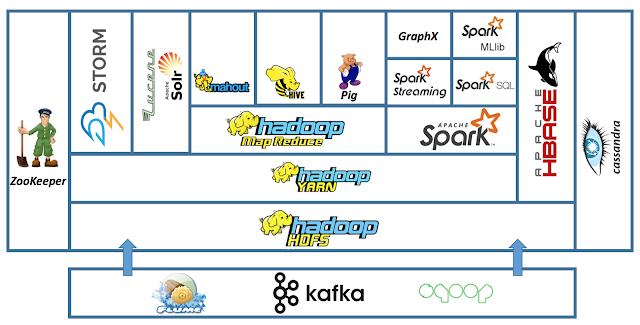
There are some other Apache projects, which are sometimes considered as in the Hadoop ecosystem as well:
- Oozie: worflow scheduling system to manage Hadoop jobs. In Oozie, a workflow is defined as a collection of control flow nodes and action nodes in a directed acyclic graph. Control flow nodes define the beginning and the end of a workflow, as well as a mechanism to control the workflow execution path. Action nodes are the mechanism by which a workkflow triggers the execution of a computation/processing task, such as MapReduce, Pig, etc.
- Sqoop (SQL-to-Hadoop): a command-line interpreter tool for importing data from database (e.g. MySQL, data warehouse, etc) into the Hadoop environment (e.g. HDFS, Hive). It can also export the data back.
- Flume: data ingestion for streaming logs into Hadoop environment. Flume is a distributed and reliable service for collecting and aggregating huge amounts of log data.
- ZooKeeper: distributed service coordinator, as previously discussed. It is based on a Paxos algorithm variant called ZAB protocol.
- Ambari: a framework for provisioning, managing and monitoring Hadoop clusters.
Hortonworks sandbox provide a VM image that have some Hadoop services pre-installed for beginners to get a taste of how it works all together.
Spark
Hadoop is used in the industry owing to a simple programming model (MapReduce) but the speed and waiting time (between queries and running the program). Spark is introduced to speed up the computing process. Spark uses Hadoop for storage (HDFS) and processing. It extends the MapReduce model to efficiently use more types of computations which includes interactive queries and stream processing.
Spark started as a sub-project of Hadoop in 2009 but since 2014 Apache has run it as a top-level project. It is a lightning-fast in-memory cluster computing technology. The features are:
- Speed: in-memory computing makes super fast processing;
- Built-in APIs supports multiple languages: Scala, Python and Java;
- Advanced analytics – apart from map and reduce, Spark also has libraries that supports SQL query, near real-time stream processing, Graph algorithms and machine learning.
Spark can run in standalone mode, on Mesos, or with YARN cluster manager. The document also provides guide on deployment on EC2 and Kubernetes. Spark contains these components:
- Spark Core: the underlying general execution engine for spakr platform that all other functionality is built upon. It provides in-memory computing and referencing datasets in external storage systems.
- SparkSQL: a components on top of Spark Core that introduces a new data abstraction called SchemaRDD, which supports both structured and semi-structured data.
- Spark Streaming: perform streaming analytics on top of Spark Core. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformation on the fly.
- MLib: a distributed machine learning framework
- GraphX: a distributed graph-processing framework
The speed of Spark is owing to its fundamental data structure – Resilient Distributed Datasets (RDD), an immutable distributed collection of objects. Each dataset in RDD (object collection) is divided into logical partitions, which can be computed on different nodes of the cluster. The object can be any type of Python, Java or Scala object, including user-defined classes. There are two ways to create RDDS:
- Parallelizing an existing collection in your driver program
- Referencing a dataset from external storage system (e.g. HDFS, HBase) or data source offering a Hadoop Input Format
You can also create RDD based on other existing RDDs. This page explains further how RDD speeds up computing compared to MapReduce.