
Kernel introduction
Linux system is composed of three main bodies of code, in line with the most traditional UNIX implementations:
- Kernel: The kernel is responsible for maintaining all the important abstractions of the operating system, such as virtual memory and processes;
- System Library: The system libraries define a standard set of functions through which applications can interact with the kernel. These functions implement much of the OS functionality that does not need the full privileges of kernel code. The most important system library is libc (C library), which provides standard C library and implements the user mode side of the Linu system call interface, as well as other critical system-level interfaces.
- System utilities
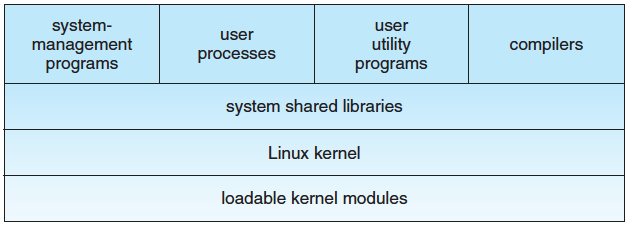
The kernel is created as a single, monolithic binary (for best performance), running in the processor’s privileged mode (aka kernel mode), that implements all the features required to qualify as an OS. The kernel can load (and unload) modules dynamically at run time.
No user code is built into the kernel. Any OS support code that does not need to run in kernel mode is placed into system libraries and runs in user mode. User mode has access only to a controlled subset of system resources.
The system libraries allow applications to make system calls to the Linux Kernel. Making a system call involves transferring control from unprivileged user mode to privileged kernel mode. The libraries also provide routines that do not correspond to system calls at all, such as sorting lagorithms, mathematical functions, and string manipulation routines.
The system utilities include all the programs necessary to initialize and then administer the system, such as those to set up networking interfaces and to add and remove users from system. User utilities include shell, file copy utility, etc
Kernel modules:
- module-management system
- module loader and unloader
- driver-registration system
- conflict resolution mechanism
Process Management
A process is the basic context in which all user-requested activity is serviced within the operating system. The basic principle of UNIX process management is to separate process creation and execution.
- fork() system call creates a new process. It duplicates a process without loading a new executable image.
- exec() system call runs a program.
This article describes the difference between fork and exec, which is very important to understand.
Process Identity consists of Process ID(PID), credentials (userID and groupID), personality, and namespace. A process’s environment is inherited from its parent and is composed of two null-terminated vectors: the argument vector and the environment vector. They are not altered when a new process is created.
The process identity and environment properties are usually set up when a process is created and not changed until that process exists. Process context include:
- scheduling context: the information that the scheduler needs to suspend and restart the process
- accounting information: the resources currently being consumed by the process
- File table: an array of pointers to kernel file structures representing open files. When making file-I/O system calls, processes refer to files by an integer known as file descriptor (fd), that the kernel uses to index into this table.
- file-system context: the process’s root directory, current working directory and namespace
- signal-handler table: defines the action to take in response to a specific signal. (e.g. terminating the process, invoking a routine in process’s address space, etc)
- virtual memory context: full contents of a process’s private address space.
Linux can create threads via the clone() system call. Linux does not distinguish between processes and threads. Instead, Linux generally uses the term task, rather than process or thread, when referring to a flow of control within a program. The clone() system call behaves identically to fork(), except that it accepts as arguments a set of flags that dictate what resources are shared between the parent and child (whereas a process created with fork() shares no resources with its parent. The flags include:
- CLONE_FS: fiel-system information is shared
- CLONE_VM: memory space is shared
- CLONE_SIGHAND: signal handlers are shared
- CLONE_FILES: open files are shared
Scheduling is the job of allocating CPU time to different tasks within an operating system. Linux supports preemptive multitasking, where the process scheduler decides which thread runs and when.
Thread scheduling uses a real-time range from 0 to 99, a nice value from -20 to 19. (bigger = nicer = less priority)
- Completely Fair Scheduler (CFS): calculates how long a thread should run as a function of the total number of runnable threads. Each thread is initialized with 1/N of the processor’s time (N=total number of thread). CFS then adjusts this allotment by weighting each thread’s allotment by its nice value. It also factors in target latency (the interval of time during which every runnable task shoudl run at least once) and the minimum granularity (minimum lenght of time any thread is allotted the processor)
- RealTime scheduling: first-come, first-servce (FCFS) and round robin
Kernel synchronization – The way the kernel schedules its own operations is fundamentally different from the way it schedules threads. A request for kernel-mode execution can occur in two ways. A running program may request an operating-system service (system call or page fault), or a device controller may deliver a hardware interrupt that causes the CPU to start executing a kernel-defined handler for that interrupt. The problem for the kernel is that all these tasks may try to access the same internal data structures. This creates the potential of data corruption, and a common way to address it is critical section – portions of code that access shared data and must not be allowed to execute concurrently. Linex Kernal uses spinlocks and semaphores (as well as reader-writer versions of these two locwk) for locking in the kernel.