
This posting covers some basic docker orchestration tools.
Docker Compose
Docker Compose’s predecessor is a tool called Fig developed by Orchard, which was acquired by Docker in 2014, with Fig renamed to Docker Compose. Docker Compose is the official container management tool. It is essentially a python script that parses yaml file, to make Docker API calls to manage containers dynamically. It is installed along with Docker on MacOS and Windows. On Linux, you will have to download package with curl command and install manually. Docker Compose has three versions so far and we should create new template with v3.
The Docker compose yaml template consists of three parts:
- services: similar to docker run
- build: specify Dockerfile to build image
- cap_add, cap_drop: specify kernel capabilities (e.g. NET_ADMIN, SYS_ADMIN)
- command: override default startup command by container
- container_name
- depends_on
- devices: map host device to container
- dns
- dns_search:
- entryppoint: override entry point from image
- env_file: specify file that stores environment variable
- environment: specify environment variable
- image: specify the location of image
- pid: share the PID namespace with host
- ports: expose network ports. HOST:CONTAINER
- networks
- volumes: mount host volume to container
- networks: similar to docker network create
- volumes: similar to docker volume create
Here is a typical structure of docker compose yaml template (wordpress):
version: "3.8"
services:
mysql:
image:mysql:5.7
volumes:
- mysql_data:/var/lib/mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD:root
MYSQL_DATABASE:mywordpress
MYSQL_USER:digihunch
MYSQL_PASSWORD:hunchdigi
wordpress:
depends_on:
- mysql
image: wordpress:php7.4
ports:
- "8080:80"
restart:always
environment:
WORDPRESS_DB_HOST:mysql:3306
WORDPRESS_DB_USER:digihunch
WORDPRESS_DB_PASSWORD: hunchdigi
WORDPRESS_DB_NAME: digihunch
networks:
frontend:
backend:
volumes
mysql-data: {}In summary, Docker Compose is an orchestration tool for single host, typically seen in development and test environment with dependencies between services.
Docker Stack
A stack is a set of related services and infrastructure that gets deployed and managed as a unit. A docker stack file has the same format as Docker Compose file, with the only requirement that the version: key specify a value of 3.0. The other difference between Docker Stacks and Docker Compose, is that stacks do not support builds. All images have to be built prior to deploying the stack.
From the stack file, Docker first executes the network section and create networks that do not exist. Then it goes through other elements. A service is a JSON collection(dictionary) that contains a bunch of keys. The image key is the only mandatory key in the service objects, which will be pulled from Docker Hub by default. Ports key maps the port of Swarm to the port of each service replica. By default, all ports are mapped using ingress mode. This means they’ll be mapped and accesible from every node in the Swarm -even nodes not running a replica. The alternative is host mode, where ports are only mapped on Swarm nodes running replicas for the service.
The environment key lets you inject environment variables into services replica.
The secrets key defines two secrets – revprox_cert and revprox_key. These must be defined in the top-level secrets key, and must exist on the system. Secrets get mounted into service replicas as a regular file. The secrets defined in this service will be mounted in each service replica as /run/secrets/revprox_cert and /run/secrets/revprox_key, unless otherwise specified.
The volumes key is used to mount pre-created volumes and host directories into a service replica.
The networks key ensures that all replicas for the service will be attached to the front-tier network. The network specified here must be defined in the networks top-level key, and if it doesn’t already exist, Docker will create it as an overlay.
The service also defines a placement constraint under the deploy key. This ensures that replicas for this service will always run on Swarm worker nodes. Placement constraints are a form of topology-aware scheduling, and can be a great way of influencing scheduling decisions.
When Docker stops a container, it issues a SIGTERM to the process with PID 1 inside the container. The container (its PID 1 process) then has a 10-second grace period to perform any clean-up operations. If it doesn’t handle the signal, it will be forcibly terminated after 10 seconds with a SIGKILL. The stop_grace_period property overrides this 10 second grace period.”
Although you may scale a docker service as part of a stack with scale command, it is not recommended. Instead, stack file should be used as the ultimate source of truth (declarative method vs imperative method). All changes to the stack should be made to the stack file, and the updated stack file used to redeploy the app.
Docker Swarm
For multi-host cluster, Docker Swarm facilitates the deployment of micro-services. Docker Swarm is:
- a cluster of Docker hosts: enterprise-grade, secure communication, PKI with automation, dynamic addition of nodes
- an orchestration engine, with deployment automation, deploying native swarm apps (using Docker API) and Kubernetes apps.
A Docker nodes can be physical servers, VMs, cloud instances, etc. Nodes are configured as managers or workers. Managers look after the control plane of the cluster, and dispatches tasks to workers. Managers forms a distributed management cluster on its own, and they use Raft protocol to ensure consistency. Workers accept tasks from managers and execute them. Swarm mandatorily uses TLS to encrypt communications, authenticate nodes, and authorize roles, with Automatic key rotation.
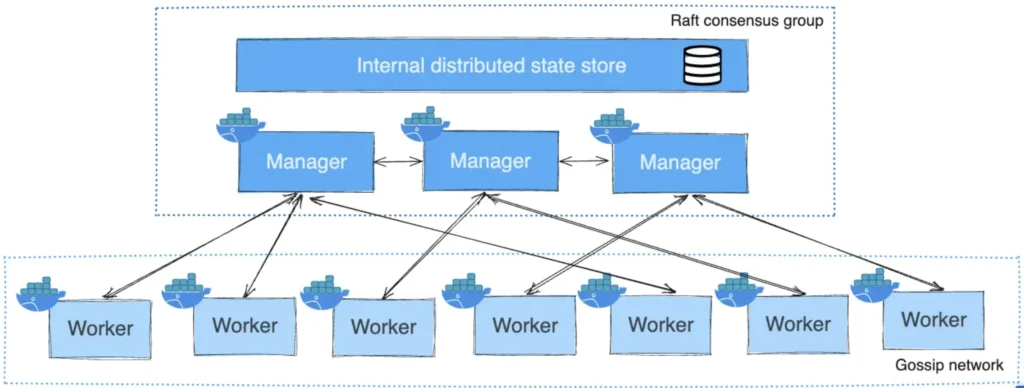
The atomic unit of scheduling on a swarm is the service. When a container is wrapped in a service, we call it a task or a replica, and the service construct adding things like scaling, rolling updates and simple rollbacks.
To initialize a swarm, we need to have the following ports open. Then we can initialize the first manager node, join additional manager nodes, and then join workers.
- 2377/tcp: for secure client-to-swarm communication
- 7946/tcp & udp: for control plane gossip
- 4789/udp: for VXLAN-based overlay networks
A Docker node can exist either in single-engine mode as stand alone, or in swarm mode as part of a swarm. Service only exist in swarm mode. Running docker swarm init on a Docker host in single-engine mode will switch that node into swarm mode, create a new swarm, and make the node the first manager of the swarm. Then additional nodes can be joined as managers or workers.
Swarm managers have native support for high availability, through an active-passive, multi-manager HA. Only one manager is considered active (the leader), which is the only one that will ever issue live commands against the swarm. If a passive manager receives commands for the swarm, it proxies them across to the leader.
Managers are either leaders or followers. This is Raft terminalogy because swarm uses an impelementation of the Raft consensus althorithm to power manager HA. As to HA, the following two best practices apply:
- deploy an odd number of managers
- don’t deploy too many managers (3 or 5 recommended, never more than 7)
Having an odd number of managers reduces the chances of split-brain conditions. Having less than 7 managers ensures that achieving consensus is quick.
With a service, we can specify name, port mappings, network to attach to, and images, as well as desired state for an application service. It is recommended in production environment to use docker-compose template to specify service. Services have replication mode, and the default is replicated. This will deploy a desired number of replicas and distribute them as evenly as possible across the cluster. The other mode is global, which runs a single replica on every node in the swarm.
Running “docker service scale” command can scale the number of service replicas from 5 to 10, which in the background updates the service’s desired state to the newly specified number of replicas. Behind the scenes, Swarm also runs a scheduling algorithm that defaults to balancing replicas as evenly as possible across the node in the swarm. Docker makes it super easy to push updates to deployed applications. With rolling update, you may specify number of replicas to update at a time, and cool-off period per update.
Here is a great article on the difference between Docker Swarm and Kubernetes.