

As discussed, serverless simply means cloud services that delegate autoscaling management to cloud platform. In my mind, the word “serverless” translates into “managed autoscaling”. As long as a service’s capacity is managed automatically, we can consider it as serverless. Given that capacity scaling accounts for a good amount of work in IT operation, moving to serverless significantly reduces operation overhead.
Unlike containers, the serverless ecosystem lacks standard. Since AWS is leading the charge in this field, let’s take a look at its offerings.
Lambda Function
Lambda functions have triggers. We can configure a trigger from an AWS service, or even a non-AWS service which supports AWS event bridge, to invoke Lambda function. Based on the trigger (e.g. SQS, S3, DynamoDB), you then specify event source mapping. For example, if trigger is SQS, you need to specify the queue name, batch size and batch window in event source mapping. If trigger is S3, the event source mapping needs to specify bucket, S3 action, etc. Event source mappings vary significantly among trigger types.
Depending on the trigger, a Lambda function may be invoked in one of the two ways:
| Synchronous invocation | Asynchronous invocation | |
|---|---|---|
| Summary | Requestor fires request and waits until it receives response before closing connection. | Lambda places triggering event in a queue and immediately returns a success code (202). Then a separate process reads events off the queue and sends them to your Lambda function. When the function returns a success response or exits without throwing an error, Lambda sends a record of the invocation to an EventBridge event bus. |
| Pros | Requestor get invocation result as soon as function run is complete | The queue decouples the request and invocation. |
| Cons | When load is high the function requires higher capacity for concurrency | Involves more parties at play and can be quite complex to troubleshoot. |
Here is a chart with the triggers that support each invocation mode.
Real-life applications often need to include libraries and dependencies that requires language-specific steps. For example, NodeJS applications need bundling (often using Webpack or esbuild). We can use Lambda layers to simplify the management. The additional libraries often need to be packaged in S3 bucket or as container image.
Lambda functions are subject to cold start to cope with. When a lot of invocations occur about the same time, the order of executions might be different than the order of upstream events that invokes the function.
API Gateway
AWS API Gateway is an API gateway implementation for REST and WebSocket APIs. It couples with Lambda in the classic multi-tier serverless architecture pattern.
In this classic pattern Lambda function often need to work with a database (e.g. DynamoDB etc), to perform CRUD operations and other custom business logics. The CRUD operations are so commonplace that it makes sense to use mapping template to configure CRUD operation instead of writing similar set of functions for each new data model. API Gateway supports such a mapping template called Velocity Template Language (VTL), a technology from Apache Velocity Project.
API Gateway integrate with many other AWS services. Here are the available integration types:
| Integration Type | Description | Integration Mode | How it works |
|---|---|---|---|
| AWS integration | connects gateway to an AWS service action as the end point. | AWS_PROXY | this mode only supports only one action with one service: the function invoking action for Lambda service. Therefore it is available only for Lambda integration and no other AWS services. For that reason, it is also known as Lambda proxy integration. This mode is recommended for Lambda integration and is the default mode for LambdaIntegrationOption CDK construct. It connects a method (PUT, GET, etc) to a Lambda function and pass along the request on the way in, and the response on the way out. You do not set integration request or integration response. Even if you do, there’s no effect. This “pass-along” mode is easier to understand and configure. |
| AWS | this mode connects an API method to a broad range of supported AWS service action. Function invoking for Lambda service is a common example but not the only service action supported in this mode. When used in Lambda integration, it is also referred to as “Lambda custom integration”, or “normal (request/response mapping) integration”. This mode is good for advanced use cases (e.g. header modification) but involves more management effort. You have to control the mapping between method request and integration request, and between integration response and method response. | ||
| HTTP integration | for generic HTTP service endpoint | HTTP_PROXY | the pass-along mode for upstream HTTP endpoint |
| HTTP | the request/response mapping mode for upstream HTTP endpoint | ||
| MOCK integration | the API gateway itself serves as the endpoint. | MOCK | the API gateway itself acts endpoint without an upstream. One example use case is to return CORS-related headers upon a pre-flight OPTIONS query. |
The table above is a summary of API Gateway integration types as covered here. In the AWS context, proxy mode suggests that the request is not being morphed (transformed). In non-proxy mode, request or response may be modified on their ways in or out.
For API gateway to invoke lambda function, synchronous invocation is used by default. You can also configure API gateway to invoke Lambda function asynchronously by using headers.
As with other API gateway implementations, AWS API Gateway can also connects to an authorizer (either another Lambda function or Cognito service) in order to authorize the incoming request.
AppSync
In a previous post, I discussed GraphQL as a modern and efficient alternative to REST API. AppSync to GraphQL is the same as API Gateway to REST API. One of the advantages that GraphQL has over REST API is more information in the response. Oftentimes, we use a proxy that supports GraphQL in front of REST API service. AppSync can act as such proxy. I think of it as a managed Apollo since they play the the role in the architecture.
Another benefit of GraphQL is the support of subscription, obviating WebSocket configuration. AppSync supports pub/sub API for real-time experience. Client application can get near real-time update as the data on the server is changed.
We can configure AppSync to connect to different data sources to formulate GraphQL response. The data source can be an HTTP endpoint, a Lambda function, a database (Relational or DynamoDB), or OpenSearch.
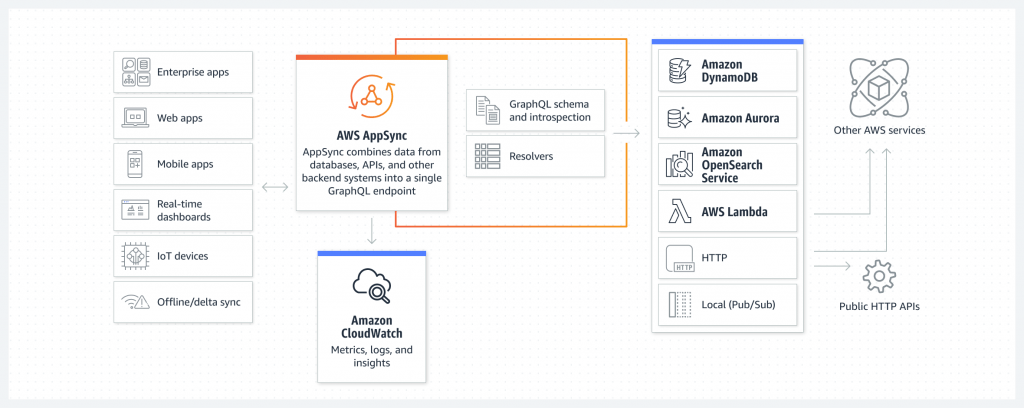
Between data source and the request, AppSync uses resolver to convert GraphQL payload to the underlying protocols and executes if the caller is authorized to invoke it. Resolvers are comprised of request and response mapping templates, which contain transformation and execution logic. AppSync also uses VTL as the mapping template for resolvers.
Messaging Services
Messaging services have three patterns: queues, pub/sub, and event buses. In AWS, the corresponding services are SQS, SNS and EventBridge. Here is a good post about how to choose among them.
Queues are temporary storage to decouple the source and destination systems. The expectation is that the actions in response to the message can be delayed. If that is not the case and the response needs to be immediate, that is by definition an event-driven pattern. A common solution is to have the AWS service invoke Lambda function. If that is not supported, we can use SNS as an intermediary.
SNS is for simple event-driven pattern. In a more complicated event-driven architecture, we often need an event bus to route events in certain ways. We also need to support various event sources by different software providers. Moreover, we want the capability to register our own event schema. These are the scenarios where EventBridge can help.
Developer tools
In application development with serverless stack, the line between application and infrastructure is somewhat blurred. Developers often find themselves making repeated configuration on cloud resources while writing application code. For example, to test Python code (application), developer has to upload the code to S3, create Lambda function referencing the code, etc. This would require too much work with AWS CLI, or CloudFormation. The AWS SAM (AWS Serverless Application Model) is a better utility for serverless development workflow.
SAM comes with its own CLI and developers can feed it with template that interacts with a number of serverless resources (e.g. API, SimpleTable, Function, etc). I view SAM as one layer of abstraction on top of CloudFormation that handles some resources in serverless stack. It saves developers from re-writing resources in CloudFormation templates and keeping them consistent, which would have been tedious. Once you deployed your application using SAM, it will appear as a Lambda Application in the console.
SAM templates are also declarative. It is simple but limited in feature. AWS CDK is also a powerful utility that works with general purpose programming language for IaC and interacts with all AWS resources. It is very powerful for building serverless applications.
AWS Amplify
We have CDK, SAM and CloudFormation but we still have to ensure integration between those resources and our applications. For example, when creating a S3 buckets, they have to get the endpoint and reference it in the application code. So is Cognito. As a result, developers still have to spend time on resource integration. They still can’t focus on business logic. We need a tool that can make opinionated configuration of cloud resources and automatically reference them from the application code. This is the purpose of AWS Amplify.
Amplify not only help application developers create backend resources with opinionated configurations. It also provides libraries for the application to use and connect to those resources seamlessly. Developers will need to include Amplify libraries in the application code. To create cloud resources, they can use Amplify CLI or Studio (a web portal from AWS console).
Amplify natively supports a number of serverless resources such as API (using API gateway or AppSync), Storage (S3 and CloudFront), Lambda function, Cognito, etc. Developer may use Amplify CLI command to create such supported resources. Amplify will prompt some guiding questions in order to configure them correctly. In addition to the natively supported resources, developers can also create custom resources. They have to declare those custom resources with CloudFormation or CDK. I came across this project as a good illustration of how Amplify works.
The Amplify Studio can save developers from using Amplify CLI commands. It also can integrate with Figma, providing developers with a framework for frontend development. However, in my experience, it is still glitchy. For now I stick to Amplify CLI.
Amplify also supports hosting capability, providing users with opinionated and customizable CI/CD pipeline configuration.
How about “clientless”
Lambda function can also run client-side logics. System administrators have to create lots of client-side scripting. While Lambda functions can encapsulate those logics, we’d still need a script orchestrator to invoke those functions. AWS Step Function comes to rescue. It was even regarded as the most under-utilized service. As the author states, a state machine (as design pattern) is simply a flow of actions with decision making logics. AWS Step function helps you groom the logic flow of existing actions with Amazon States Language. There are standard and express workflows. Each step is a state. A state can be of several different types, such as Choice, Task, Succeed, Fail, End, Map, Wait, Parallel. The task can be a Lambda function, and even AWS API calls.
AWS Step function integrate with Lambda functions. It is typically used for patterns with long process and the need to orchestrate the execution of several Lambda functions. For specific use cases, look at these sample projects. For example, a network professional needs to run a lot of connectivity testing, reusing the same Python script but run it from different subnets. We need to create a Lambda function for commands like “nc -vz” then invoke the lambda function from VPC, multiple times from different VPCs. We should use step function to drive this. It works like a Makefile on Linux, without requiring your own computer to run.
AWS Step function also integrates with other AWS services, such as SNS, SQS, Dynamo, Batch, Glue, EMR, EKS, API gateway, event bridge.
Whenever we need to create a script, involving custom actions, or AWS API calls, we should consider using AWS step function to organize the actions. The benefits are: it saves you a laptop or bastion host (“client-less”), many ways to invoke them (not just cron”).
Summary
In this post, we started with some serverless services in AWS. For server-side application, we can use API Gateway to invoke Lambda function. For client-side, we can use step function to invoke Lambda function. We then discussed some tools to speed up application development in serverless pattern.
AWS categorizes both Amplify and AppSync under Front-end Mobile. Amplify does not represent any computing resources in AWS cloud. It is a library and CLI tools to enhance developer experience. AppSync on the other hand is a cloud computing resource acting as GraphQL API for mobile or web application.