

I wrote a brief on this topic a while back. Now I need to configure OIDC in a few occasions I decide to dive deeper into the flows this time. As I stated in the last post, Nate Barbettini’s presentation from 2017 was awesome and I viewed it again. Slides are available here. Another great reference is this post from DeepNetwork Developer’s blog.
Back Channel and Front Channel
To understand why there are several different flows, it is important to understand the difference between back channel and front end channel.
In web development, traditional architecture involves a frontend (e.g. Browser, or any client-side app) and backend server. The web frontend is written in HTML, CSS, JavaScript, etc. There are also web frameworks such as Django, Angular, to save developers time. Backend (server-side) is responsible for storing and organizing data to ensure frontend can function. There might be multiple backend servers, such as session cache, data store, API server, etc.
In a nutshell, server-to-server communication is back channel, and browser-to-server communication is front channel. From security perspective, we regard front-channel as less secure, because we have less control of the location of the front-end and browser is easy to tamper with.
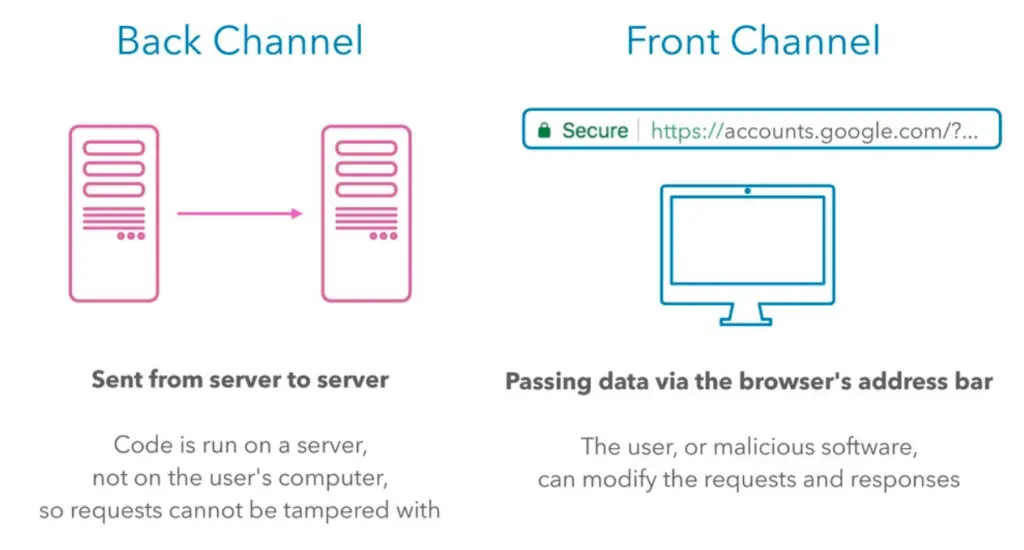
For traditional web applications with client-server architecture, when they communicate with third-party servers, they can initiate the communication from their backends, creating a back channel for better security posture. Single-page applications (SPAs) are applications without their own backends. When building an SPA, the front-end developer deals with frontend frameworks such as React, Angular or Next.js. When SPAs have to communicate with third-party APIs, they have to create a front channel. Also the API must support Cross-Origin Resource Sharing (CORS) for the browser to allow the cross-domain communication.
In the web development world, there is also Native App (aka Mobile App). Native App to Server communication is also considered back channel as we consider the client-side (Mobile App) secure. Nate’s talk makes the following recommendation for the flow (grant type) and I rephrase it as below:
| Architecture | Recommendation |
|---|---|
| Traditional Web Application (client-server architecture) | There are both front and back channels. Use authorization code flow |
| Single Page Application (SPA, e.g. JavaScript) with API backend | Front channel only. Use implicit flow |
| Native mobile App | Use authorization code flow with PKCE |
| Microservices and APIs (Machine-to-Machine) | Back-channel only. Use Client credentials flow |
The message, is that we should use Authorization Code Flow and use back channel, so long as the required component (backend) exists in the architecture. Note that the terminology for these types of applications may differ. For example, when you try to create an OIDC client for Amazon Cognito user pool, here’s how it categorizes client capability (app type):
- Public client: A native, browser, or mobil-device app. Cognito API requests are made from user systems that are not trusted with a client secret.
- Confidential client: A server-side application that can securely store a client secret. Cognito API requests are made from a central server.
Get used to different terms describing the same concept.
OAuth 2.0 and OIDC flows
The original problem that OAuth 2.0 (RFC6749) addresses is delegated authorization. In all OAuth flows, the authorization server issues an Access Token for the client to carry. The Access Token identifies the scope of resources that its carrier is authorized to access. However, third-party services do not always want to delegate authorization to the identity provider. They often just need identity information and want to perform authorization on their own. The OAuth 2.0 Access Token itself is all about permission and does not care about the identify of its carrier. It is not designed for authentication. OAuth 2.0 does not provide a standard way for Authorization Server to keep identity information of the principal. Many developers needs to address identity issue and they started to (mis)use the AccessToken to store identity information in custom fields, until OIDC came about.


OIDC is a thin layer (5%) on top of OAuth 2.0 and one important addition is the ID token. The resource server can, in addition to being asked to allow access, now can understand the identity of the principal requesting to access resources from the ID token. The OIDC layer also uses standard set of scopes and proposes a userinfo endpoint for client to get more details about user information. The authorization code flows in OIDC and OAuth2.0 are roughly the same except for the additions.
In terms of the flows supported, the OAuth flows are defined in RFC6749, including the following grants:
- Authorization Code grant
- Implicit grant
- Resource Owner Password Credentials grant
- Client Credentials grant
The classic grant type is Authorization Code. After verifying with user, the Authorization Server fires a call-back to the client to pass the authorization code. The client, then takes the authorization code, along with its client ID and client secret, to fire a request to Authorization server in exchange for Access Token. The implicit grant skips the Authorization Code step and the client gets the Access Token in a one-stop shop via callback over front channel, which is less secure. The other two grants are less often used.
On the OIDC side, the specification document discusses three flows:
- Authorization Code Flow (specification 3.1)
- Implicit Flow (specification 3.2)
- Hybrid Flow (specification 3.3)
The original OAuth2.0 flows should only be used in delegated authorization scenario. In most contexts, if we talk about ID token, and if our use case involves authentication, then we’re talking about OIDC not just OAuth. Since Authorization Code Flow is the classic one, out of all these flows, in the next section we take a closer look at the Authorization Code Flow in OIDC.
Authorization Code Flow in OIDC
We consider the Authorization Code Flow the baseline flow and others as variations of it owing to architectural limitations. When we mention OIDC we implicitly refers to the Authorization Code Flow unless the context suggests otherwise. Now let’s zoom in on it:
Here is the narrative from my own words:
- The user launches client application, which detects that user has not logged in, and redirect to log in page.
- The client app sends an HTTP request for authorization code to the /authorize endpoint of Authorization server. This request consists of the following fields:
- Response type: code, indicating it is requesting authorization code
- Scope: openid, standard for oidc
- RedirectURI: my.com/oidc-callback, Authorization Server will use this to call back with code.
- The authorization server redirects the user to a prompt for log-in
- The user completes authentication and consent
- The Authorization server validates user information within its identity provider
- The Authorization server fires an HTTP request call-back at the Redirect URI (on the backend), with Authorization Code.
- The client app issues an HTTP request for ID Token and Access Token to the /token endpoint of Authorization server. This request consists of:
- Authorization Code (received from previous step)
- Client ID
- Client Secret
- The Authorization server validates the information and process the request, and prepare the response with the following fields:
- ID Token: identifies the resource owner.
- Access Token: identifies what the client app can access
- Expiration
- (Optional) Refresh Token
- The client app receives the tokens above in the HTTP response from the /token endpoint
- With the Tokens, the client app issues API requests to the resource server
- The resource server independently validates the token
- The resource server send API response back the the client app.
There are also a few points of configurations. First, the Resource Server needs to trust the Authorization Server. The Authorization Server uses its private key to sign the JWT tokens and the Resource Server needs the public key to validates it. Second, the authorization server needs to know about the client app. We usually configure the Authorization Server upfront, to generate the client ID and secret. The Client app will keep them as part of its configuration.
It is important to note that, when I use the term client app (OIDC calls it client), the word “client” is relative to the Authorization server. The client app itself consists of both frontend (browser) and backend (aka relying party). In this flow, the authorization code is not exposed to browser.
Other OIDC Flows
Now we can discuss some flows for other architectures.
The Authorization Code flow has a close variation with the use of PKCE (Proof Key for Code Exchange). For native apps, postman and Okta recommend Authorization Code flow with PKCE. When client app first requests for authorization code, it also includes a challenge. After the callback, when it sends the authorization code back to authorization server in exchange for tokens, the request now adds a verifier. This way, even if the authorization code may not be securely saved, the authorization server can ensure it is the same client app that requests authorization code and that requests tokens.
An SPA or JavaScript app does not have a way to a. store Authorization code and b. listen on a call-back URI. As a result, it makes sense for the SPA to just fetch the Tokens directly. This make the implicit flow. The spec doc refers to it as simplified authorization code flow. The grant type is “implicit” because there is no intermediate credentials issued. In this flow, the Authorization server does not authenticate its client. The tokens may be exposed to resource owner or other applications with access to resource owner’s user-agent. This flow improve the responsiveness but we should be wary of the security implications.
As stated above, for SPAs (or in-browser JavaScript), we have to choice but the Implicit Flow because the client app is front-end only and we do not consider it able to securely store credentials. Client apps that can securely store client credentials may benefit from Hybrid Flow. In the hybrid flow, when the authorization server fires callback, the callback includes a single-use authorization code, along with ID token, access token, or both, depending on the provided response_type. Then the client app sends it back to authorization server, along with client credentials, in exchange for a second ID token and access token. The specification has a good table that compares the three flows:

Apart from the three flows, there are also some “unofficial” OIDC flows, that are not discussed in the specification. For example, Auth0 adopted some original OAuth2.0 grants in conformance to OIDC, including Client Credentials Flow with OIDC and Resource Owner Password Flow with OIDC. The client credentials flow is for machine-to-machine identity and is not concerned with user identity.
Identify the Flow
A challenge that I faced is to make sense of the Authorization Code Flow in real life. I realized that the components (Client App, Authorization Server and Resource Server) in Authorization Code Flow are conceptual. In real life we do not always find a counterpart that perfectly match their features. When we try to introduce OIDC for authentication, we often need to build our own solution, with additional tools.
Take the client app for example. We would need one or several components in real life to perform the followings in order to qualify as a Client App in the sense of Authorization Code Flow, it needs to:
- know the authorization endpoint and construct the HTTP request for Authorization code;
- stand up an HTTP service (relying party) to listen to call back, and parse the Authorization Code;
- securely store Authorization code, and have access to client ID and client secret;
- construct a request for tokens using client ID, secret and authorization Code received;
- parse the tokens from the response from Token endpoint
- to pass the tokens along
When developers builds an application with OIDC integration capability, they’d have to implement all these using the library of their programming language. In addition to application’s own server, the OIDC module will need its own backend capable of doing all the activities above. The alternative option is to introduce a OIDC capable client proxy service.
As for the Resource Server, it needs to have a trust on the Authorization Server, so that it can cryptographically validate the tokens that the Authorization Server has issued using the well-known public key.
On the Authorization Server side, as we discussed. It needs to provision client ID and client secret that itself can later recognize when client app connects to it. It also needs to have both authorization endpoint and token endpoint. Often times, the authorization server contains identity store and we’d like to call it the identity provider, but that is not always the case. A company may have a home grown identity store that does not support OIDC. In that case, to qualify as an OIDC Authorization server, they need a server proxy.
Open ID Connect Specifications
Despite the different implementation by different vendors, we often need to resort to the official standard documentation. This Open ID connect page lists all the specification if you expand “OpenID Connect specification” under Final Specifications. The most commonly used ones are:
- OpenID Connect Core specification [OpenID.Core.Errata2], which covers the foundation and three login flows (Authorization Code, Implicit and Hybrid). This was developed early and the current version [OpenID.Core.Errata2] is from Dec 2023 but the two previous versions [OpenID.Core.Errata1] and [OpenID.Core.Final] had been around since 2014;
- Open ID Connect Session Management [OpenID.Session], another core document that stipulates how to manage sessions, finalized in Sept 2022;
- Open ID Connect Discovery 1.0 [OpenID.Discovery], which stipulates the hosting OIDC discovery document, finalized in Dec 2023;
- Open ID RP-Initiated Logout [OpenID.RPInitiated], one of the logout flow specification, drafted in 2020 and finalized in Sep 2022;
- Open ID Front-Channel Logout [OpenID.FrontChannel], one of the logout flow specification, drafted from March 2016 and finalized in Oct 2022;
- Open ID Back-Channel Logout [OpenID.BackChannel], one of the logout flow specification, drafted in 2016 and finalized in Sep 2022;
Do read the specification when you’re configuring integration. It is worth noting that apart from the Core specification which has been finalized for a decade, most of the other specifications did not finalize until late 2022. Therefore, it is important for integrators to validate the compliance state of the components in the implementation.
OIDC Proxy
As a result, with regard to OIDC, there are two categories of proxies: OIDC client proxy and OIDC server proxy.
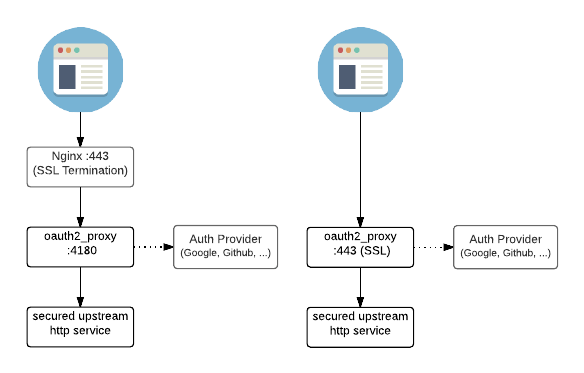
For example, in my previous post, I explained how to configure external authorization via OIDC in Istio. Looking at the diagram, it uses OAuth2 proxy to integrate with GCP as the authorization server. In this use case, GCP is natively OIDC capable, the the Hello Word App isn’t. Therefore, the OAuth2-proxy that we introduced is an OIDC client proxy.
For a corporate with Active Directory, the identity store only supports LDAP protocol. In order to quality the identity store as an OIDC Authorization Server, we would need a server-side proxy such as the LDAP connector in Dex, with the Active Directory as authentication source. The diagram of dex is a good summary of its role:
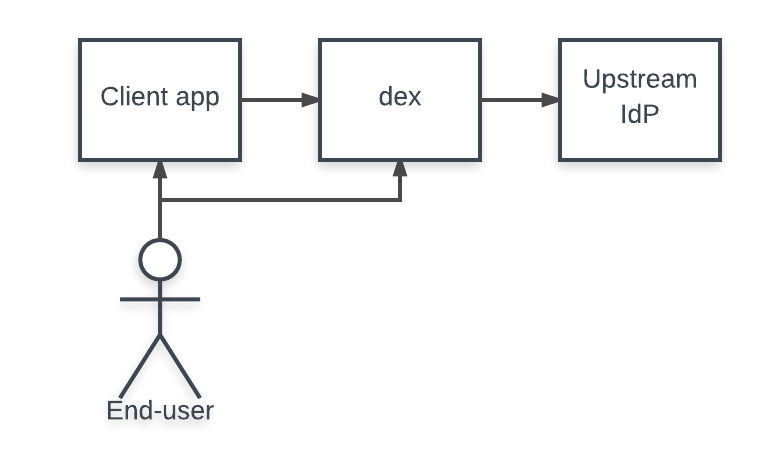
In some scenarios, we refer to this role as identity broker. Dex is an identity broker. Another important project to know is KeyCloak, which is sponsored by Red Hat and now a CNCF project. Although you can configure KeyCloak as an identity broker, it is much more than a broker. KeyCloadk is a full-fledged identity and access management solution on its own. It can act as the entire Authorization server. The diagram in this blog post summarizes its features well. It is for teams that wants to build their home grown identity store. Think of KeyCloak as a self-managed open-source alternative to IAM solutions such as Okta or Auth0.
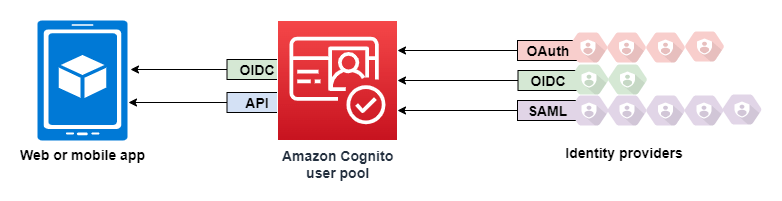
The Amazon Cognito user pool plays a similar role. A user pool serves as an identity store to an app. The integration (no matter which flow and how Cognito calls them) is supposed to be OIDC compliant. However, as of date, the integration with Cognito user pool isn’t. For example, the logout endpoint requires client_id parameter where as the RP initiated logout specification has it optional. On the other hand, it can federate its own identity pool with a third party via standard protocol including OIDC.
In any use case where we need to bring OIDC integration, we need to start with the flow recommendation for each architecture, then we examine the existing component against the flow diagram. From there, we can identify the missing pieces and determine where and how we should configure the proxy.
Summary
The OIDC topic confuses me big time every time I need to configure identity store. With this post, I was hoping to elaborate on the Authorization Code Flow for OIDC. See OpenID certification for a list of providers. Further I discussed the two categories of proxies in the OIDC picture. Hopefully, when the OIDC topic comes back again, I will be able to quickly match which is which, and identify the missing piece to build a solution.