
Background
We have previously covered a pipeline example with Jenkins calling Ansible to leverage OpenSSH configuration and Ansible inventory. We also discussed a use case with declarative pipeline.
In this posting, I will provide another advanced example, built on declarative pipeline. The pipeline file will be pulled from Git repository. Also, the script is executed on a remote agent, instead of the Jenkins master server. The reason this example is important, is that:
- Jenkinsfile is now version controlled (pipeline as code);
- Service script (e.g. python) is also version controlled from a central repository;
- Computing resource is provided by a remote agent. Since the script is pulled before running, the agent is still fungible;
- The result from service script execution is archived (similar to the way build artifact is stored in Jenkins) in master.
The architecture of this pipeline now becomes the followings:
Configure Agent
Jenkins has a plugin called SSH Build Agent, that allows you to configure a Linux agent, communicating with Jenkins master in SSH. For Window agent, it uses JNLP to communicate with master, which is outside of our scope of discussion. As I touched on in previous post, Jenkins uses its own implementation of SSH protocol to achieve this. This means that it cannot re-use the configurations in ~/.ssh/config and thus the ability to do SSH chaining is eliminated. This is incompatible with our architecture so I have to register Jenkins agent using a different launch method “Launch agent via execution of command on the master”. The execution of command on master can still leverage OpenSSH config file. In order to do so, we must copy the agent.jar file to the remote agent first (URL is ${JENKINS_URL}/jnlpJars/agent.jar). Then use SSH command to call the jar file from agent (aka slave) machine. You may add some java argument for troubleshooting. Below is an example configuration for the node.
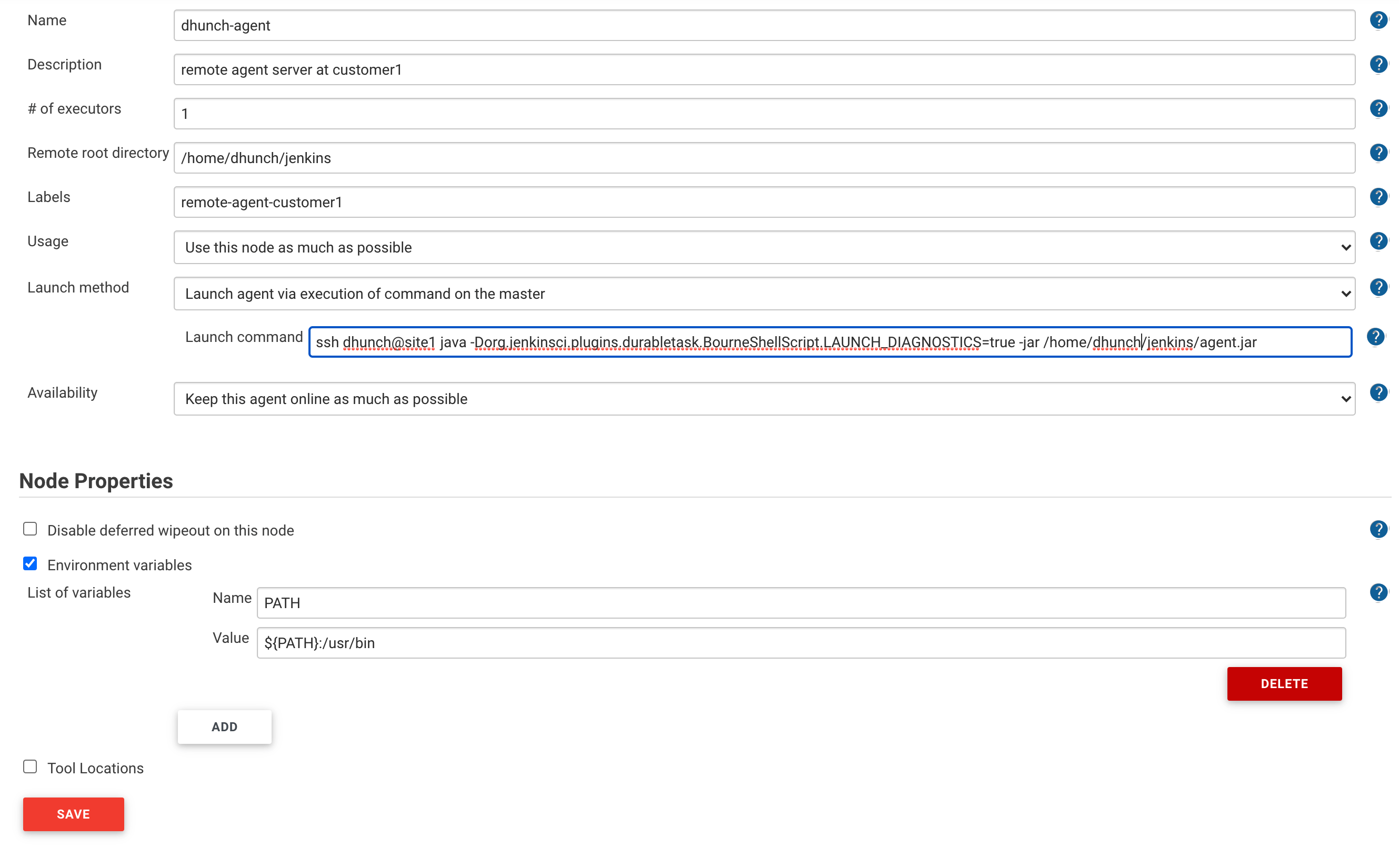
I shall also note that if the remote agent is a different operating system where the path of bash might be different, then you need to include the directory of bash executable in PATH environment variable. That can be done as in the screenshot above (PATH=${PATH:/usr/bin}). If this is incorrect, you might run into issues when running sh step in Jenkins pipeline. Here is an article about this. To translate that page, the symptom of this issue includes:
- Error from pipeline execution that says the following, which is very generic:
process apparently never started in /home/dhunch/jenkins/workspace/site-remote-job@tmp/durable-b997d26c
(running Jenkins temporarily with -Dorg.jenkinsci.plugins.durabletask.BourneShellScript.LAUNCH_DIAGNOSTICS=true might make the problem clearer)
- Job status shows:
hudson.AbortException: script returned exit code -2
at org.jenkinsci.plugins.workflow.steps.durable_task.DurableTaskStep$Execution.handleExit(DurableTaskStep.java:659)
at org.jenkinsci.plugins.workflow.steps.durable_task.DurableTaskStep$Execution.check(DurableTaskStep.java:605)
at org.jenkinsci.plugins.workflow.steps.durable_task.DurableTaskStep$Execution.run(DurableTaskStep.java:549)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:515)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
- Threaddump (only available during execution) shows:
Thread #6
at DSL.sh(awaiting process completion in /home/dhunch/jenkins/workspace/site-remote-job/durable-b997d26c; recurrence period: 9543ms; check task scheduled; cancelled? false done? false)
at WorkflowScript.run(WorkflowScript:9)
at DSL.script(Native Method)
This issue is tricky because none of the symptoms above make you think about the environment variable defined for the agent, and that the issue does not occur until you actually execute a Jenkins pipeline, usually well after the node agent is registered, and only impacts shell step (sh). It is recommended to test this with sh steps in pipeline.
Configure Repository
Our example job executes service script pulled from SCM, on a remote agent. Then the master pulls the result file to itself. The git repository can be set in Jenkins job, where you specify that the script named Jenkinsfile (from the repo) is the pipeline file that needs to be executed.
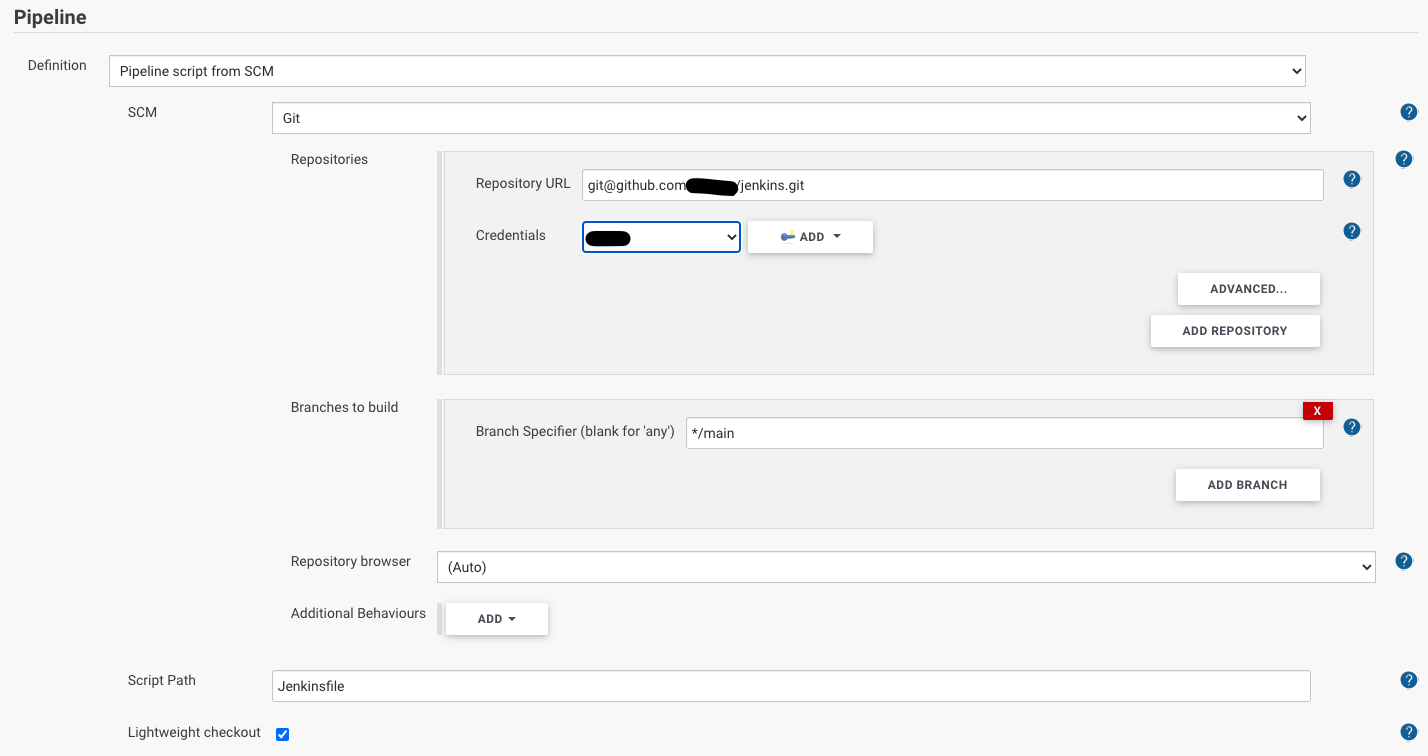
This is fairly simple, but what makes the situation more complex is the following few requirements:
- it’s the agent node that needs git (installed) and clone to repo;
- the master does not need (and should not attempt to) clone from repo;
- the master needs to do its job without having to pull SCM;
We need to be able to specify whether each step needs to pull from SCM. The following pipeline syntax shows how this is done:
def agent_dir = 'initial_value'
pipeline {
agent none
options { skipDefaultCheckout(true) }
stages {
stage('Execute Job') {
agent {
label 'remote-agent-customer1'
}
options { skipDefaultCheckout(false) }
steps {
echo 'Executing job on node'
sh 'whoami && pwd'
script {
agent_dir = sh(returnStdout: true, script: 'echo -n ${WORKSPACE}')
// the variable should not include carriage return
}
sh "echo ${agent_dir}"
}
}
stage('Pull Result') {
agent {
label 'master'
}
options { skipDefaultCheckout(true) } // no need to pull scm to this agent
steps {
echo 'Pulling job below'
sh "echo ${agent_dir}"
sh "scp dhunch@site1:\"${agent_dir}\"/result.csv ./"
}
}
}
}
In this example pipeline file, we declare agent none for the pipeline, then an agent for each specific stage. we also specify the option skipDefaultCheckout as true at the step where pulling from SCM is not needed. This allows us to finish job with multiple agent, and only pull from SCM as needed. This snippet also exemplifies how to declare a variable, assign it from stdout from one agent, and persist the value across ensuing stages.
Store Result
The reason we run pipeline jobs on this remote agent is because it is sitting in customer network and has local direct access to data. So this is perfect for situation such as data analytical jobs, which access to database on local network and store result. We need to pull the result file back to agent and make it available on Jenkins. This is so similar to “archive artifact” task (commonly seen in CI process) that we can simply use its plugin to achieve what we need. Before archive artifact, we need to pull it to local (master), as shown in the example code above. After that, we need another stage to archive the result.
stage('Archive Result') {
agent {
label 'master'
}
options { skipDefaultCheckout(true) } // no need to pull scm to this agent
steps {
archiveArtifacts artifacts: '*.csv',onlyIfSuccessful: true,fingerprint: true
}
}
I believe there is plugins to compress artifacts as well.
Conclusion
At the end I’d like to reiterate my perception about Jenkins. It is a very generic and adaptive automation platform that originally evolved from use cases in build automation. Due to this original root, many components in Jenkins are named around Continuous Integration use cases, such as the “build” button, and the “archiveArtifacts” step. These misnomers underplays what Jenkins can potentially do in continuous deployment or other automation scenarios. It is important for automation engineers to understand Jenkins components and plugins, through their functionalities and not by the name, and therefore make creative use of Jenkins as automation engine in all scenarios.
An alternative to this proposed pipeline would be Ansible Tower, a commercial project based on open-source Ansible, but with nice UI support. Ansible Tower is Ansible oriented, and it does not have everything that Jenkins can do. It should still be a decent alternative given the proposes pipeline uses Ansible a lot.