

In a previous post, I introduced Terraform Cloud and covered how to use AWS profiles with Terraform. This time I explored some alternatives to Terraform Cloud, in the context of Azure. I use Scalr as an example of multi-cloud management platform. I will also discuss some issues I’ve came across while managing permissions and variables for Terraform.
Scalr
Scalr is a multi-cloud management platform. I first used it in January but since then it seemed to focus on being a collaboration platform for Terraform. It organizes deployment by environments and workspaces. Accounts in the free tiers is allowed to have one Environment. You will also need to configure (cloud) providers and VCS providers. Once configured, it is important to link a cloud provider with an Environment. Each workspace inside of an Environment can be associated with a VCS provider. In the case of Terraform, this limits a workspace with a single cloud provider.
Permission with Azure
I have a resource group (e.g. named AutomationTest) under a subscription. My account has Contributor role of this resource group. To run Terraform, I could login to Azure as my own account on my environment using AWS CLI. Terraform will pick up the session from Azure CLI and execute as my user. However, it is recommended to run Terraform as a separate own entity. This would allow me to run Terraform template from Scalr, or Terraform Cloud. It is also a good practice for Terraform to use a separate account than a regular user account. There are a number of ways to do this as suggested on the guides for Terraform azurerm provider, including:
- Authenticating via a Service Principal and a Client Secret
- Authenticating via a Service Principal and a Client Certificate
- Authenticating via Managed Identity
- Authenticating via the Azure CLI, only recommended when running Terraform locally.
I chose the first option and followed the instruction, using the following CLI command to create the service principal:
az ad sp create-for-rbac -n tf-sp --role="Contributor" --scopes="/subscriptions/9dd2c898-8111-4322-91d6-a039a00bd513/resourceGroups/AutomationTest"
The command returns a few attributes (client ID, tenant ID, secret) that I needed to configure cloud providers in Scalr. The service principal will also be visible under App Registrations in Azure. Once configured I needed to link the provider to an Environment, for Scalr to make an connection to Azure. Otherwise, the Scalr run will return the following Error:
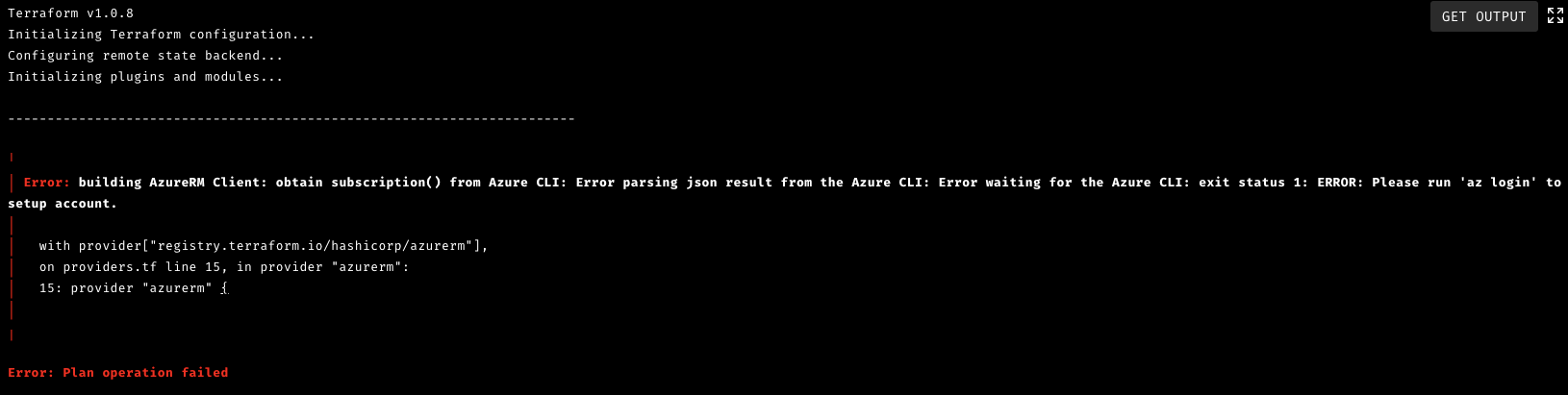
Once provider linking is completed, Scalr automatically populate required environment variables in the workspace. They show up as “Shell” variables under VARIABLES tab.
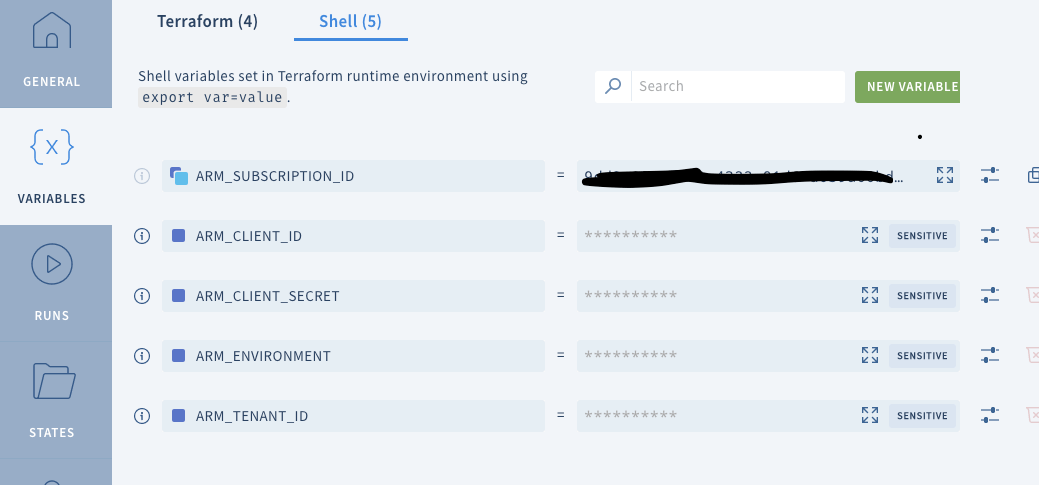
Under the Terraform tab are input variables that you wish to put in for Terraform template to pick up. Then you can run the template. This works well until I came across a permission issue when I added azurerm_role_assignment resource in Terraform template. What I was trying to do is something like this:
resource "azurerm_role_assignment" "admin_assignment" {
scope = var.rbac_aks_id
role_definition_name = "Azure Kubernetes Service RBAC Admin"
principal_id = var.rbac_principal_object_id
}
And whenever at this line, the following error returned:
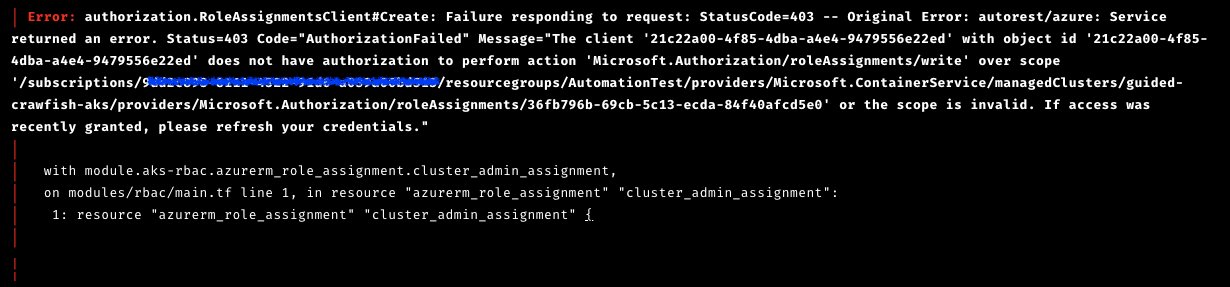
Apparently the code 403 indicates Azure doesn’t think the Terraform Service Principal has the privilege to perform Microsoft.Authorization/roleAssignments action. The reason dates back to the way I created service principle above, where I specified contributor role for resource group. However, contributor as a built-in role does not include the permission to assign roles in Azure RBAC. To address this issue, I needed a custom role, named TerraformContributor, with the following definition:
{
"assignableScopes": [
"/subscriptions/9dd2c898-8111-4322-91d6-a039a00bd513/resourceGroups/AutomationTest"
],
"description": "Grants full access to manage all resources, but does not allow you to manage assignments in Azure Blueprints, or share image galleries.",
"id": "/subscriptions/9dd2c898-8111-4322-91d6-a039a00bd513/providers/Microsoft.Authorization/roleDefinitions/637824aa-52ae-42f6-a24e-26b2a443afdf",
"name": "637824aa-52ae-42f6-a24e-26b2a443afdf",
"permissions": [
{
"actions": [
"*"
],
"dataActions": [],
"notActions": [
"Microsoft.Blueprint/blueprintAssignments/delete",
"Microsoft.Compute/galleries/share/action",
"Microsoft.Blueprint/blueprintAssignments/write"
],
"notDataActions": []
}
],
"roleName": "TerraformContributor",
"roleType": "CustomRole",
"type": "Microsoft.Authorization/roleDefinitions"
}
Compare this with the JSON statement of built-in contributor role, the exclusion of actions for Microsoft.Authorization are removed. The creation can be completed with CLI command “az role definition create” in the subscription, or use Azure portal. Once the role is created, create a new service principal using the
az ad sp create-for-rbac -n tf-sp --role="TerraformContributor" --scopes="/subscriptions/9dd2c898-8111-4322-91d6-a039a00bd513/resourceGroups/AutomationTest"
This solution is suggested on this thread.
Composite type for Input variable
Sometimes we want to define an input variable that describes a hierarchy of attributes on a resource. A good example would be Azure Kubernetes service. We can use either object or map as the variable type. The example below has a variable of each type.
variable "cluster_detail" {
description = "AKS cluster"
type = object({
resource_group = string,
cluster_name = string,
kubernetes_version = string,
node_subnet = object({
subnet_name = string
vnet_name = string
resource_group = string
}),
pod_subnet = object({
subnet_name = string
vnet_name = string
resource_group = string
}),
lb_subnet = object({
subnet_name = string
vnet_name = string
resource_group = string
}),
ad_admin_group_object_ids = list(string)
})
}
variable "common_tags" {
description = "common tags"
type = map(any)
default = {
tagA = "valueA"
tagB = "valueB"
}
}
When using object as the type, the default value needs to define all fields.
In this example where node pool configuration is exposed, we can see how using variables with hierarchy helps template user customize infrastructure specification.
Parsing Map as Input variable
To find out the best multi-cloud management platform, I tested a few of them. I find it inconsistent when I have an input variable of the map type. With Terraform Cloud, I have to specify the variable to be parsed as HCL, and the value has to be:
{"Environment" = "Dev", "Owner" = "[email protected]"}
With Scalr, I also have to specify the variable to be parsed as HCL, and the value can be either the one above, or the one below:
{"Environment":"Dev","Owner":"[email protected]"}
So Scalr is more flexible in parsing maps. Apart from Scalr and Terraform, I also tested env0 but I gave up after an hour. I could not specify to parse a variable as HCL. They need to work harder on this. Neither was I able to figure out the right syntax as plain variable. I did not test Atlantis or SpaceLift.
Enterprise Deployment
When deploying code to enterprises with their own network environment, Scalr supports running a self-hosted agent inside of the Enterprise network. This is also supported by Terraform Cloud (manage in cloud, execution in enterprise network). This is very useful when the execution machine needs to access the resource created in the enterprise environment.
A good example, is using Terraform’s Azure provider to provision an AKS cluster on the corporate network. Then use Terraform’s kubernetes provider to connect to the newly created cluster and create some Kubernetes object such as service account, as illustrated in this blog post.