

When optimizing workload performance, it is important to understand how on earth operating system allocates CPU and memory to processes. This helps understand how to set resource limit Kubernetes Pod in an optimal way.
CPU resource assignment
The OS distributes CPU resource to processes by the unit of time share of CPU time. Most of the time, many processes with CPU instructions (machine code) are waiting in the Job queue, for their share of CPU time in order to execute their instructions. As soon as CPU becomes idle, the CPU scheduler selects a process from the ready queue to run next:
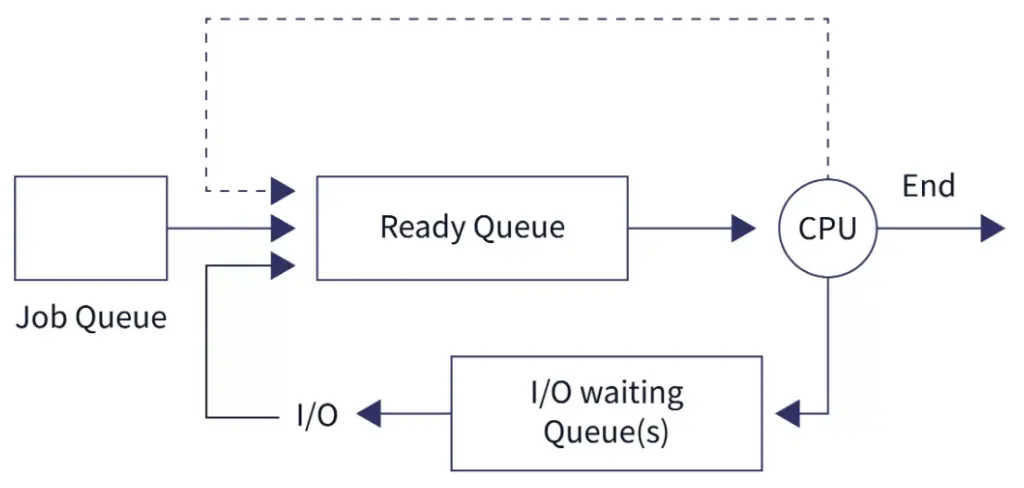
Ideally, OS should schedule CPU in a way that it should not waste any CPU cycle. It should also minimizes waiting time and response time of processes. At a high level, there are two types of CPU scheduling:
- Preemptive: OS allocate CPU resources to a process for only a limited period of time and then takes those resources back. It could interrupt a running process to execute a higher priority process.
- Non-preemptive: New processes are executed only after the current executing process has completed its execution.
Here is more information about preemptive and non-preemptive scheduling.
CPU is compressible resource in Linux
In the Linux world, all scheduling is preemptive. We also call it kernel preemption. As the wikipedia entry states: the scheduler is permitted to forcibly perform a context switch (on behalf of a runnable and higher-priority process) on a driver or other part of the kernel during its execution, rather than co-operatively waiting for the driver or kernel function (such as a system call) to complete its execution and return control of the processor to the scheduler when done.
The Linux scheduler implements a number of scheduling policies, which determine when and for how long a thread runs on a particular CPU core. The scheduling policies in RHEL include real time policies such as SCHED_FIFO and SCHED_RR where processes have a sched_priority value in the range of 1 (low) to 99 (high); and normal policies such as SCHED_OTHER, SCHED_BATCH and SCHED_IDLE, where sched_priority (specified as 0) is not used in scheduling decisions.
It is important to understand preemptive CPU scheduling on Linux. When OS allocate CPU resource to a process for one time slot, it is not committed to the same process for the next time slot. The OS reserves the ability to revoke the next CPU use and re-assign it for processes of higher priority.
Because of this, we regard CPU as a compressible resource. The compressible characteristic impacts how we optimize CPU utilization for a process, including setting CPU request and limit for Kubernetes workload.
Memory is non-compressible resource
A few years ago, I discussed how to calculate memory usage. A process requests memory from OS using memory allocation functions (the malloc family), and return memory to OS using free functions. The design of Linux OS knows that processes have a tendency to request more memory than they use, which causes under-utilization. In combat against under-utilization, the Linux OS supports memory overcommitment (on by default), allowing processes to request more memory than what is available. The processes have access to virtual memory space and the OS may swap some pages out to disks. The overcommitment mechanism also prevents processes from crashing due to insufficient memory assignment. The kernel can also OOM kill a process when the entire system is in a crisis.
Memory is non-compressible resource. When OS assigns memory pages to a process, the process has to right to keep those pages, until the OS takes them away. Unlike assigning CPU cycles, the assignment of memory pages to processes does not have an expiry time. This is the non-compressible characteristic of memory assignment.
CPU limit and requests for Kubernetes workload
It was considered best practice to set request and limit for memory and CPU. However, knowing CPU is compressible resource and memory isn’t, we should re-consider this practice. In short, for CPU, we should set request only, without setting limit. For memory, we should set limit to exactly the same as request.
A process has different level of demands for CPU at different times. Depending on the activity in the process, the level of demand can even be spiky. If there is a lot of iowait, it may not need a lot of CPU. But when there are lots of computing-bound activities, the program is CPU-thirsty as it is programmed to to more. The last thing we want is to throttle the CPU use for a process in such legit situations. When throttling happens, the process does not get sufficient time share of CPU time. At the platform level, we can’t control when the Pod (process) gets busy. The best thing it can do, is trying to fit more CPU time shares to this process when it becomes CPU thirsty. When we apply a limit of CPU in workload setting, we are potentially throttling the CPU use for a process at the times it needs more CPU time shares, which is counter-productive.
We should still configure CPU request, so that kube-scheduler factors it in when scheduling multiple Pods to a Node. The CPU request alone ensures the number of Pods are not excessive. This is the only thing we can do about controlling CPU assignment for Pods. We should also monitor CPU throttling.
Memory limit and request for Kubernetes workload
Memory is not compressible, therefore we should set both limit and request to the same value. We set memory request so that kube-scheduler has an idea assigning Pods. We set the limit so that no single Pod takes more memory than its fair share. Unlike CPU, once a Pod takes more memory than its fair share, the platform will have to be aggressive to reclaim it back, which may impacts the running of the Pod (process). In contrast, CPU scheduler never guarantees the assignment of CPU time share to a Pod beyond the end of the current CPU cycle.
When we’re setting memory limit and request with different values, we’re sending a confusing signal. We’re inviting Pods to use more memory than they requested. This increases the chance of memory shortage at the node level, and hence the need to OOM kill a Pod.
Horizontal autoscaling and Cluster Autoscaling
The native HPA is metrics-based. As I previously discussed, neither CPU nor memory metrics are good indicators of time to scale. A process or a Pod may have a temporary high demand of CPU purely due to how programmers write the code. Even if we followed the best practices as above, I would still not regard CPU and memory metrics as a reliable indicator to drive auto scaling. If a service is a potential point of congestion, we should use a queue in front and the queue size is almost always a much better indicator of the timing to scale.
As to cluster autoscaler, on it FAQ, it says flat out that you should NOT use a CPU usage based scaling mechanism. I guess this is for a similar reason (compressibility). As discussed, when a Pod is pending for schedule for too long, it emits and event that drives the cluster autoscaler.
Summary
When I first worked on Kubernetes workload I did not give this much thought and proposed the use of CPU limit. As of January 2023 I still find static code analysis tools that requires CPU limit for Pods in the check (e.g. CKV_K8S_11 on Checkov), which leads me to investigate the issue further, and noticed more voices advocating the correct use of resource limit (such as this post) in 2022. For existing deployments, it is worth a review the resource limit configuration.